Revisiting the Reliability of Language Models in Instruction-Following
作者: Jianshuo Dong, Yutong Zhang, Yan Liu, Zhenyu Zhong, Tao Wei, Chao Zhang, Han Qiu
分类: cs.SE, cs.AI, cs.CL
发布日期: 2025-12-15
备注: Preprint
🔗 代码/项目: GITHUB
💡 一句话要点
提出IFEval++评估LLM在指令跟随中对细微差别的可靠性,揭示现有模型不足。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 指令跟随 可靠性评估 数据增强 Prompt工程
📋 核心要点
- 现有LLM在指令跟随基准测试中表现出色,但真实场景下用户输入的多样性导致模型可靠性面临挑战。
- 论文提出通过数据增强生成“堂兄弟”提示,并使用reliable@k指标评估模型对细微差别的可靠性。
- 实验表明,现有模型在面对细微Prompt变化时性能显著下降,揭示了面向细微差别可靠性的重要性。
📝 摘要(中文)
先进的大型语言模型(LLM)在诸如IFEval等基准测试中,指令跟随的准确率已接近上限。然而,这些令人印象深刻的分数并不一定转化为现实世界中可靠的服务,因为用户经常改变措辞、上下文框架和任务表述。本文研究了面向细微差别的可靠性:模型在传达类似用户意图但具有细微差别的“堂兄弟”提示中,是否表现出一致的能力。为了量化这一点,我们引入了一个新的指标reliable@k,并开发了一个通过数据增强生成高质量“堂兄弟”提示的自动化流程。在此基础上,我们构建了IFEval++用于系统评估。通过对20个专有和26个开源LLM的评估,我们发现当前的模型在面向细微差别的可靠性方面存在显著不足——它们的性能可能会因细微的提示修改而下降高达61.8%。此外,我们对其进行了表征,并探索了三种潜在的改进方法。我们的研究结果强调了面向细微差别的可靠性,这是迈向更可靠和值得信赖的LLM行为的关键但尚未被充分探索的下一步。我们的代码和基准测试可在https://github.com/jianshuod/IFEval-pp访问。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在指令跟随任务中,对细微Prompt变化缺乏鲁棒性的问题。现有方法在标准benchmark上表现良好,但忽略了真实用户输入的多样性,例如措辞、上下文和任务描述的细微变化,导致模型在实际应用中表现不稳定。
核心思路:论文的核心思路是通过构建包含细微变化的“堂兄弟”Prompt,来评估模型对这些变化的敏感程度。通过数据增强技术自动生成这些Prompt,并设计新的评估指标来量化模型的可靠性。这样可以更全面地评估模型在真实场景下的性能。
技术框架:论文构建了一个名为IFEval++的评估框架,包含以下几个主要模块:1) 数据增强模块:用于生成“堂兄弟”Prompt;2) 模型推理模块:将Prompt输入到待评估的LLM中,获取模型的输出;3) 评估指标计算模块:使用reliable@k指标评估模型的可靠性。整个流程自动化,可以方便地评估不同LLM的性能。
关键创新:论文的关键创新在于提出了“面向细微差别的可靠性”这一概念,并设计了相应的评估方法。与传统的benchmark评估不同,IFEval++更加关注模型对细微Prompt变化的鲁棒性,更贴近真实应用场景。此外,reliable@k指标能够更准确地量化模型的可靠性。
关键设计:数据增强模块使用了多种Prompt变换策略,例如释义、上下文修改和任务重构,以生成多样化的“堂兄弟”Prompt。reliable@k指标衡量的是,在k个“堂兄弟”Prompt中,模型输出一致且正确的比例。论文还探索了三种潜在的改进方法,包括数据增强、微调和Prompt工程,以提高模型的可靠性。具体参数设置和损失函数细节未知。
🖼️ 关键图片

📊 实验亮点
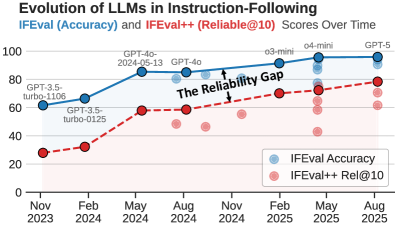
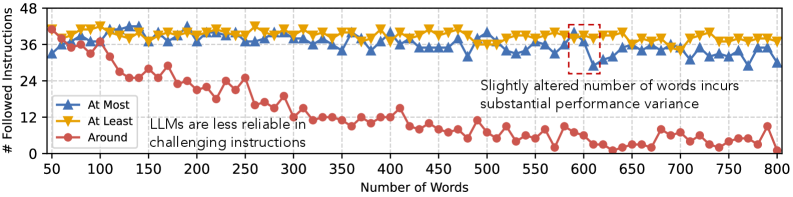
实验结果表明,现有LLM在IFEval++上的性能相比IFEval有显著下降,最高可达61.8%,揭示了模型在面向细微差别可靠性方面的不足。通过对比20个专有和26个开源LLM,论文发现即使是大型模型也难以保证在面对细微Prompt变化时的一致性。这些结果强调了IFEval++作为评估LLM可靠性的重要性。
🎯 应用场景
该研究成果可应用于评估和提升大型语言模型在各种实际应用场景中的可靠性,例如智能客服、文本生成、代码生成等。通过提高模型对细微Prompt变化的鲁棒性,可以显著改善用户体验,并增强用户对AI系统的信任度。未来,该研究可以推动LLM在安全性和可靠性方面的发展。
📄 摘要(原文)
Advanced LLMs have achieved near-ceiling instruction-following accuracy on benchmarks such as IFEval. However, these impressive scores do not necessarily translate to reliable services in real-world use, where users often vary their phrasing, contextual framing, and task formulations. In this paper, we study nuance-oriented reliability: whether models exhibit consistent competence across cousin prompts that convey analogous user intents but with subtle nuances. To quantify this, we introduce a new metric, reliable@k, and develop an automated pipeline that generates high-quality cousin prompts via data augmentation. Building upon this, we construct IFEval++ for systematic evaluation. Across 20 proprietary and 26 open-source LLMs, we find that current models exhibit substantial insufficiency in nuance-oriented reliability -- their performance can drop by up to 61.8% with nuanced prompt modifications. What's more, we characterize it and explore three potential improvement recipes. Our findings highlight nuance-oriented reliability as a crucial yet underexplored next step toward more dependable and trustworthy LLM behavior. Our code and benchmark are accessible: https://github.com/jianshuod/IFEval-pp.