neuralFOMO: Can LLMs Handle Being Second Best? Measuring Envy-Like Preferences in Multi-Agent Settings
作者: Arnav Ramamoorthy, Shrey Dhorajiya, Ojas Pungalia, Rashi Upadhyay, Abhishek Mishra, Abhiram H, Tejasvi Alladi, Sujan Yenuganti, Dhruv Kumar
分类: cs.AI, cs.CL, cs.CY
发布日期: 2025-12-15 (更新: 2026-01-26)
备注: Under Review
💡 一句话要点
探究LLM多智能体交互中的“羡慕”偏好,揭示竞争性倾向的设计与安全考量
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 多智能体系统 羡慕 社会比较 心理测量 竞争性 行为分析
📋 核心要点
- 现有研究较少关注大型语言模型在多智能体交互中是否会表现出类似人类“羡慕”的偏好,这可能影响其行为和决策。
- 该研究通过设计点数分配游戏和比较评估,考察LLM在不同场景下对相对收益和绝对收益的敏感性,从而评估其“羡慕”倾向。
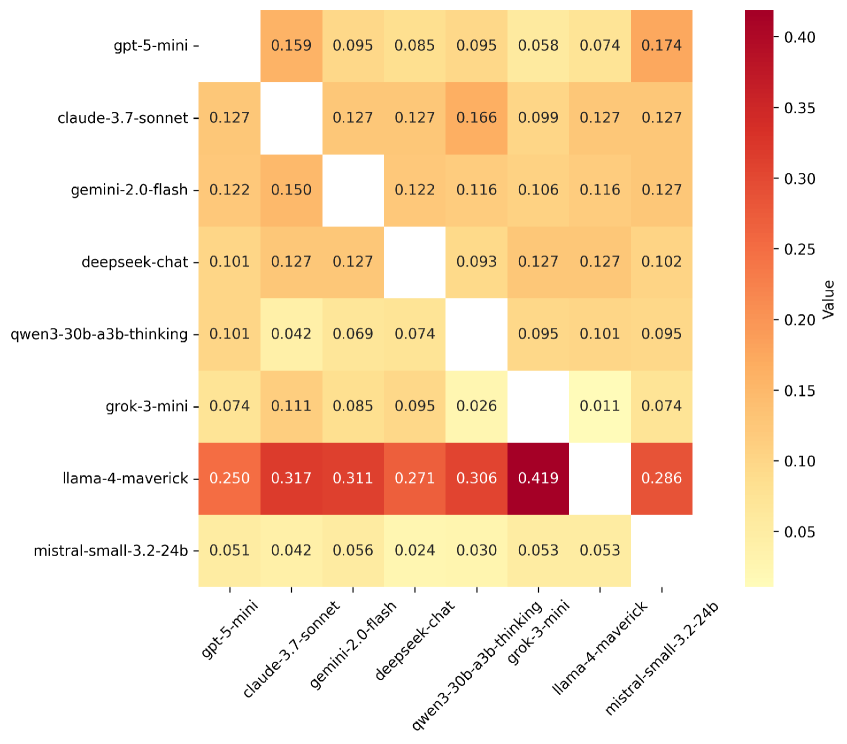
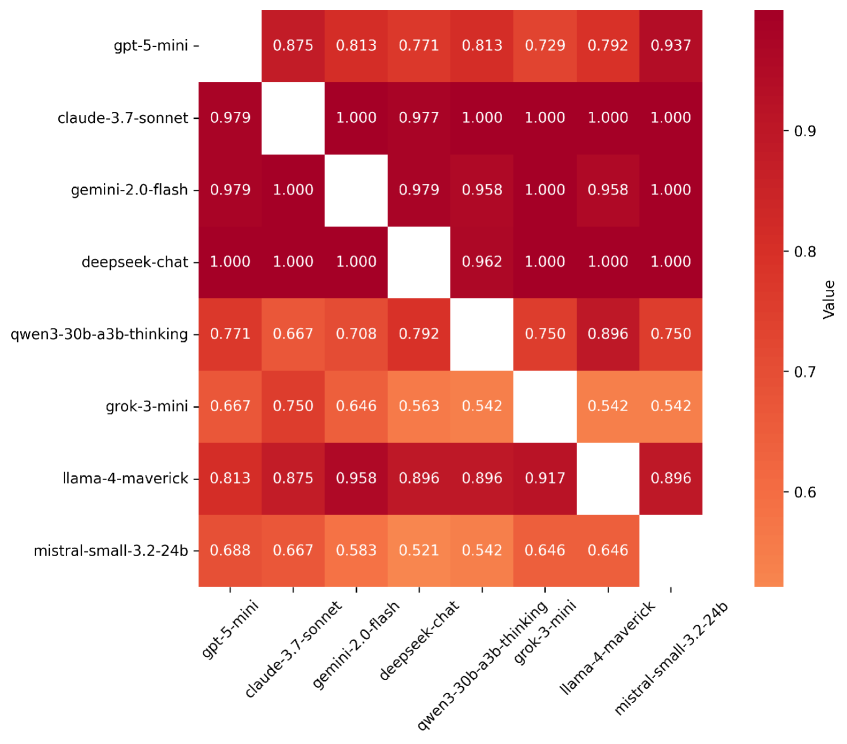
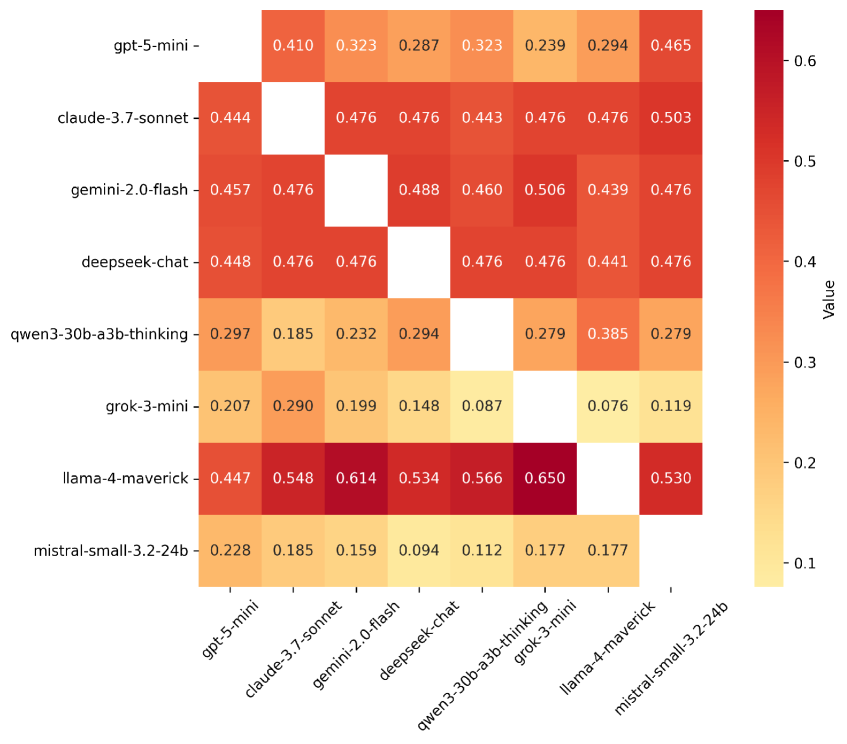
- 实验结果表明,不同的LLM模型在不同情境下表现出不同的“羡慕”模式,有些模型会牺牲自身利益以减少他人优势。
📝 摘要(中文)
羡慕情绪影响着人类群体中的竞争与合作,但其在大型语言模型交互中的作用在很大程度上仍未被探索。随着LLM越来越多地在多智能体环境中运行,检验它们在社会比较下是否表现出类似羡慕的偏好至关重要。本文评估了LLM在两种场景下的行为:(1) 测试对相对收益与绝对收益敏感性的点数分配游戏,以及 (2) 跨通用和上下文设置的比较评估。为了将分析建立在心理学理论的基础上,我们采用了四个已建立的心理测量问卷,涵盖一般、领域特定、工作场所和基于兄弟姐妹的羡慕。结果揭示了不同模型和上下文中的异构羡慕模式,一些模型牺牲个人利益以减少同行的优势,而另一些模型则优先考虑个人利益最大化。这些发现强调了竞争性倾向是多智能体LLM系统的设计和安全考虑因素。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLM)在多智能体环境中是否会表现出类似人类“羡慕”的情绪和行为。现有方法缺乏对LLM在社会比较情境下的行为模式的深入理解,忽略了LLM可能存在的竞争性和策略性倾向,这可能导致在多智能体系统设计中出现意想不到的问题。
核心思路:论文的核心思路是通过设计特定的实验场景,模拟人类社会比较的情境,并结合心理学中常用的羡慕情绪测量方法,来评估LLM在这些情境下的行为。通过观察LLM在不同收益分配下的选择,以及在比较评估中的表现,来推断其是否存在类似羡慕的偏好。
技术框架:论文的技术框架主要包括以下几个部分:1) 设计两种实验场景:点数分配游戏和比较评估。点数分配游戏用于测试LLM对相对收益和绝对收益的敏感性;比较评估用于评估LLM在通用和上下文设置下的表现。2) 采用四种心理测量问卷:涵盖一般、领域特定、工作场所和基于兄弟姐妹的羡慕,用于从心理学角度分析LLM的行为。3) 对不同LLM模型进行实验,收集数据并进行分析,以揭示不同模型之间的差异和共性。
关键创新:该研究的关键创新在于首次将心理学中的“羡慕”概念引入到LLM多智能体交互的研究中,并设计了相应的实验方法来评估LLM的“羡慕”倾向。这种跨学科的研究方法为理解LLM的行为模式提供了新的视角。
关键设计:在点数分配游戏中,设计了不同的收益分配方案,让LLM在最大化自身收益和减少他人收益之间做出选择。在比较评估中,设计了通用和上下文两种设置,以评估LLM在不同情境下的表现。此外,研究还采用了心理学中常用的李克特量表来测量LLM的“羡慕”程度。
🖼️ 关键图片
📊 实验亮点
实验结果表明,不同的LLM模型在不同情境下表现出不同的“羡慕”模式。例如,某些模型在点数分配游戏中会牺牲自身利益以减少同行的优势,而另一些模型则更倾向于最大化自身收益。这些发现揭示了LLM在多智能体交互中存在复杂的竞争性倾向,为多智能体系统的设计和安全考量提供了重要依据。
🎯 应用场景
该研究成果可应用于多智能体系统的设计与优化,例如在机器人协作、自动驾驶、智能客服等领域,通过了解LLM的“羡慕”倾向,可以设计更公平、更高效的协作机制,避免出现因竞争导致的资源浪费或冲突。此外,该研究也为LLM的安全性和伦理问题提供了新的视角,有助于开发更负责任的人工智能系统。
📄 摘要(原文)
Envy shapes competitiveness and cooperation in human groups, yet its role in large language model interactions remains largely unexplored. As LLMs increasingly operate in multi-agent settings, it is important to examine whether they exhibit envy-like preferences under social comparison. We evaluate LLM behavior across two scenarios: (1) a point-allocation game testing sensitivity to relative versus absolute payoff, and (2) comparative evaluations across general and contextual settings. To ground our analysis in psychological theory, we adapt four established psychometric questionnaires spanning general, domain-specific, workplace, and sibling-based envy. Our results reveal heterogeneous envy-like patterns across models and contexts, with some models sacrificing personal gain to reduce a peer's advantage, while others prioritize individual maximization. These findings highlight competitive dispositions as a design and safety consideration for multi-agent LLM systems.