Differentiable Evolutionary Reinforcement Learning
作者: Sitao Cheng, Tianle Li, Xuhan Huang, Xunjian Yin, Difan Zou
分类: cs.AI, cs.CL
发布日期: 2025-12-15
备注: Work in Progress. We release our code and model at https://github.com/sitaocheng/DERL
💡 一句话要点
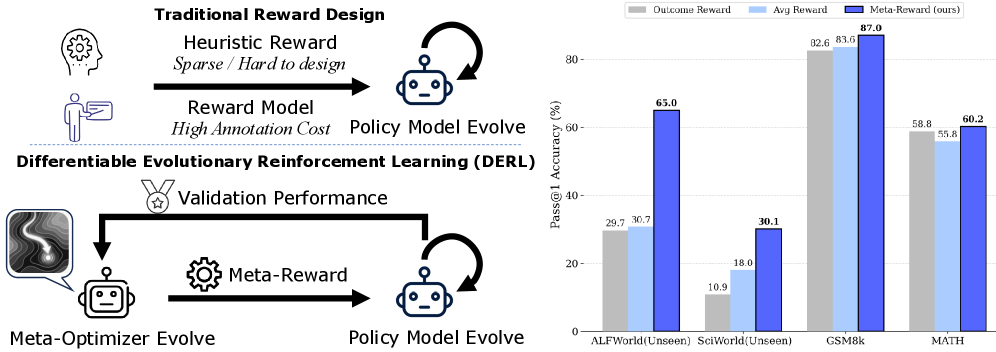
提出可微进化强化学习(DERL),自动发现复杂任务的最优奖励函数。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 可微进化 强化学习 奖励函数设计 元学习 自主智能体
📋 核心要点
- 强化学习中奖励函数的设计是难点,现有方法将奖励函数视为黑盒,忽略了奖励结构与性能的因果关系。
- DERL通过可微的元优化器进化奖励函数,利用内循环验证性能的梯度来指导奖励函数的优化。
- 实验表明,DERL在ALFWorld和ScienceWorld上超越了现有方法,尤其在分布外场景中表现突出。
📝 摘要(中文)
在强化学习中,设计有效的奖励函数是一项核心且艰巨的挑战,尤其是在为复杂推理任务开发自主智能体时。虽然已经存在自动奖励优化方法,但它们通常依赖于无导数的进化启发式方法,将奖励函数视为黑盒,无法捕捉奖励结构与任务性能之间的因果关系。为了弥合这一差距,我们提出了可微进化强化学习(DERL),这是一个双层框架,能够自主发现最优奖励信号。在DERL中,元优化器通过组合结构化的原子原语来进化奖励函数(即元奖励),从而指导内循环策略的训练。关键的是,与之前的进化方法不同,DERL的元优化是可微的:它将内循环验证性能作为信号,通过强化学习更新元优化器。这使得DERL能够近似任务成功的“元梯度”,逐步学习生成更密集和更可操作的反馈。我们在三个不同的领域验证了DERL:机器人智能体(ALFWorld)、科学模拟(ScienceWorld)和数学推理(GSM8k, MATH)。实验结果表明,DERL在ALFWorld和ScienceWorld上取得了最先进的性能,显著优于依赖启发式奖励的方法,尤其是在分布外场景中。对进化轨迹的分析表明,DERL成功地捕捉了任务的内在结构,从而在没有人为干预的情况下实现自我改进的智能体对齐。
🔬 方法详解
问题定义:强化学习中,设计合适的奖励函数以引导智能体学习复杂任务是一大难题。现有的自动奖励优化方法通常采用进化算法,将奖励函数视为黑盒,无法有效利用奖励函数与智能体行为之间的梯度信息,导致优化效率低下,泛化能力不足。
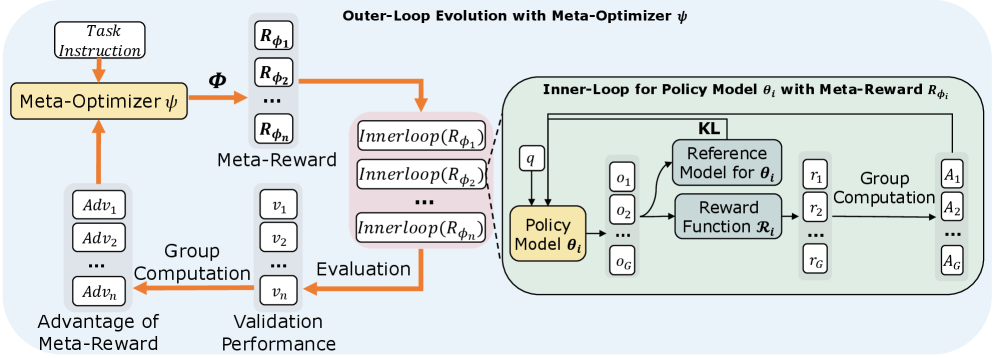
核心思路:DERL的核心思想是利用可微的元优化器来学习奖励函数。通过将内循环的策略训练过程纳入优化循环,DERL能够近似计算任务成功的“元梯度”,从而指导元优化器生成更有效、更密集的奖励信号。这种方法允许算法捕捉任务的内在结构,实现智能体的自我改进和对齐。
技术框架:DERL采用双层优化框架。外层循环的元优化器负责进化奖励函数(元奖励),它通过组合结构化的原子原语来构建奖励函数。内层循环则使用该元奖励训练智能体策略。训练完成后,使用验证集评估智能体策略的性能,并将性能反馈给元优化器,用于更新元奖励。整个过程是可微的,允许元优化器利用梯度信息来优化奖励函数。
关键创新:DERL的关键创新在于其元优化的可微性。与传统的进化算法不同,DERL能够利用内循环策略训练的梯度信息来更新元优化器,从而更有效地搜索最优奖励函数。这种可微性使得DERL能够近似任务成功的“元梯度”,并学习生成更具指导性的反馈信号。
关键设计:DERL使用强化学习算法(如PPO)作为元优化器,奖励函数由一组可学习的参数控制的原子原语组成。内循环策略的训练采用标准的强化学习算法。关键在于如何将内循环的验证性能转化为元优化器的奖励信号,以及如何设计合适的原子原语,以便元优化器能够有效地探索奖励函数空间。
🖼️ 关键图片

📊 实验亮点
DERL在ALFWorld和ScienceWorld两个复杂任务环境中取得了显著的性能提升,超越了现有基于启发式奖励的方法。尤其是在分布外场景中,DERL展现出更强的泛化能力。实验结果表明,DERL能够有效地捕捉任务的内在结构,实现智能体的自我改进,无需人工干预。
🎯 应用场景
DERL具有广泛的应用前景,可用于机器人控制、游戏AI、科学研究等领域。通过自动发现最优奖励函数,DERL可以降低人工设计奖励函数的成本,并提高智能体在复杂任务中的性能。尤其在任务目标难以明确定义或奖励函数设计困难的场景下,DERL的优势更为明显。未来,DERL有望推动自主智能体的发展,使其能够在更广泛的领域中发挥作用。
📄 摘要(原文)
The design of effective reward functions presents a central and often arduous challenge in reinforcement learning (RL), particularly when developing autonomous agents for complex reasoning tasks. While automated reward optimization approaches exist, they typically rely on derivative-free evolutionary heuristics that treat the reward function as a black box, failing to capture the causal relationship between reward structure and task performance. To bridge this gap, we propose Differentiable Evolutionary Reinforcement Learning (DERL), a bilevel framework that enables the autonomous discovery of optimal reward signals. In DERL, a Meta-Optimizer evolves a reward function (i.e., Meta-Reward) by composing structured atomic primitives, guiding the training of an inner-loop policy. Crucially, unlike previous evolution, DERL is differentiable in its metaoptimization: it treats the inner-loop validation performance as a signal to update the Meta-Optimizer via reinforcement learning. This allows DERL to approximate the "meta-gradient" of task success, progressively learning to generate denser and more actionable feedback. We validate DERL across three distinct domains: robotic agent (ALFWorld), scientific simulation (ScienceWorld), and mathematical reasoning (GSM8k, MATH). Experimental results show that DERL achieves state-of-the-art performance on ALFWorld and ScienceWorld, significantly outperforming methods relying on heuristic rewards, especially in out-of-distribution scenarios. Analysis of the evolutionary trajectory demonstrates that DERL successfully captures the intrinsic structure of tasks, enabling selfimproving agent alignment without human intervention.