M-GRPO: Stabilizing Self-Supervised Reinforcement Learning for Large Language Models with Momentum-Anchored Policy Optimization
作者: Bizhe Bai, Hongming Wu, Peng Ye, Tao Chen
分类: cs.AI, cs.CL
发布日期: 2025-12-15
备注: 7 pages, 5 figures,Accepted NeurIPS 2025 Workshop on Efficient Reasoning
💡 一句话要点
M-GRPO:通过动量锚定策略优化稳定大型语言模型的自监督强化学习
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自监督强化学习 大型语言模型 策略优化 动量模型 策略多样性 推理能力 策略崩溃
📋 核心要点
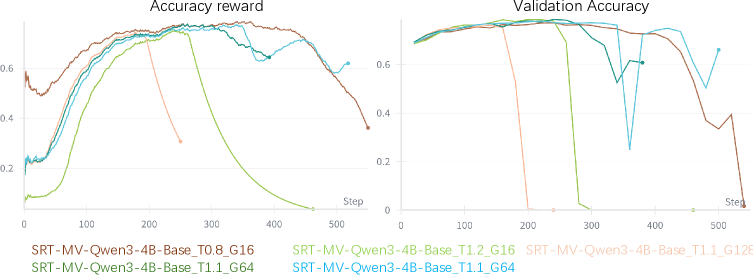
- 现有自监督强化学习方法在训练LLM时,存在长程训练下的“策略崩溃”问题,导致性能显著下降。
- 论文提出M-GRPO框架,利用动量模型提供稳定训练目标,并采用IQR自适应过滤方法保留策略多样性。
- 实验表明,M-GRPO能有效稳定训练过程,防止过早收敛,并在多个推理基准上取得领先性能。
📝 摘要(中文)
自监督强化学习(RL)为提升大型语言模型(LLM)的推理能力提供了一种有前景的方法,它无需依赖昂贵的人工标注数据。然而,我们发现现有方法在长程训练中存在一个关键失效模式:“策略崩溃”,即性能急剧下降。我们诊断了这种不稳定性,并证明简单地增加 rollout 的数量——一种常见的提升性能的策略——只能延迟,而不能阻止这种崩溃。为了对抗这种不稳定性,我们首先引入了 M-GRPO(动量锚定分组相对策略优化),该框架利用一个缓慢演化的动量模型来提供稳定的训练目标。此外,我们发现这一过程通常伴随着策略熵的快速崩溃,导致过早自信和次优的策略。为了专门解决这个问题,我们提出了第二个贡献:一种基于四分位距(IQR)的自适应过滤方法,该方法动态地修剪低熵轨迹,从而保留必要的策略多样性。我们在多个推理基准上的大量实验表明,M-GRPO 稳定了训练过程,而 IQR 过滤器防止了过早收敛。这两种创新的结合带来了卓越的训练稳定性和最先进的性能。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在自监督强化学习训练过程中出现的“策略崩溃”问题。现有方法在长程训练中,策略会突然变得次优,导致性能急剧下降。简单增加rollout数量并不能有效解决这个问题,只是延缓崩溃的发生。
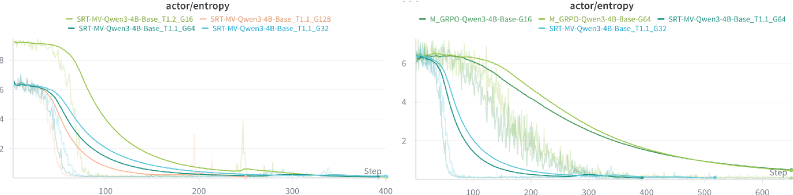
核心思路:论文的核心思路是通过引入动量模型来稳定训练目标,并使用自适应过滤方法来维持策略的多样性。动量模型提供了一个更平滑、更稳定的策略目标,避免了训练过程中的剧烈波动。自适应过滤则通过去除低熵轨迹,防止策略过早收敛到局部最优解。
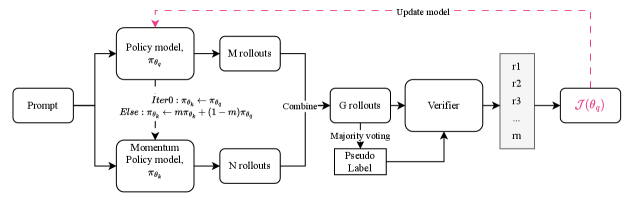
技术框架:M-GRPO框架包含两个主要组成部分:动量锚定分组相对策略优化(Momentum-Anchored Group Relative Policy Optimization)和基于四分位距(IQR)的自适应过滤。M-GRPO使用一个动量模型来生成更稳定的目标策略,该动量模型是当前策略的指数移动平均。IQR过滤器则根据轨迹的熵值动态地筛选轨迹,保留高熵轨迹,去除低熵轨迹。
关键创新:论文的关键创新在于将动量模型和自适应过滤相结合,共同解决自监督强化学习中的策略崩溃问题。动量模型提供稳定的训练目标,自适应过滤维持策略多样性,二者相互补充,共同提升训练的稳定性和性能。与现有方法相比,M-GRPO能够更有效地防止策略崩溃,并取得更好的性能。
关键设计:M-GRPO的关键设计包括:1) 动量模型的更新率,需要仔细调整以平衡稳定性和响应性;2) IQR过滤器的参数,用于控制熵阈值,从而影响轨迹的筛选;3) 损失函数的设计,需要考虑动量模型和当前策略之间的差异,以及熵的正则化。
🖼️ 关键图片
📊 实验亮点
实验结果表明,M-GRPO在多个推理基准测试中取得了最先进的性能,显著优于现有的自监督强化学习方法。通过引入动量模型和自适应过滤,M-GRPO能够有效稳定训练过程,防止策略崩溃,并提升LLM的推理能力。具体的性能提升数据在论文中进行了详细展示。
🎯 应用场景
该研究成果可应用于各种需要大型语言模型进行复杂推理和决策的任务中,例如对话系统、智能助手、游戏AI等。通过稳定自监督强化学习训练过程,可以提升LLM在这些任务中的性能和可靠性,降低对人工标注数据的依赖,具有重要的实际应用价值和广阔的应用前景。
📄 摘要(原文)
Self-supervised reinforcement learning (RL) presents a promising approach for enhancing the reasoning capabilities of Large Language Models (LLMs) without reliance on expensive human-annotated data. However, we find that existing methods suffer from a critical failure mode under long-horizon training: a "policy collapse" where performance precipitously degrades. We diagnose this instability and demonstrate that simply scaling the number of rollouts -- a common strategy to improve performance -- only delays, but does not prevent, this collapse. To counteract this instability, we first introduce M-GRPO (Momentum-Anchored Group Relative Policy Optimization), a framework that leverages a slowly evolving momentum model to provide a stable training target. In addition, we identify that this process is often accompanied by a rapid collapse in policy entropy, resulting in a prematurely confident and suboptimal policy. To specifically address this issue, we propose a second contribution: an adaptive filtering method based on the interquartile range (IQR) that dynamically prunes low-entropy trajectories, preserving essential policy diversity. Our extensive experiments on multiple reasoning benchmarks demonstrate that M-GRPO stabilizes the training process while the IQR filter prevents premature convergence. The combination of these two innovations leads to superior training stability and state-of-the-art performance.