CTIGuardian: A Few-Shot Framework for Mitigating Privacy Leakage in Fine-Tuned LLMs
作者: Shashie Dilhara Batan Arachchige, Benjamin Zi Hao Zhao, Hassan Jameel Asghar, Dinusha Vatsalan, Dali Kaafar
分类: cs.CR, cs.AI, cs.LG
发布日期: 2025-12-15
备注: Accepted at the 18th Cybersecurity Experimentation and Test Workshop (CSET), in conjunction with ACSAC 2025
💡 一句话要点
CTIGuardian:一种用于缓解微调LLM中隐私泄露的少样本框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 隐私保护 大型语言模型 微调 少样本学习 安全对齐 网络威胁情报 数据泄露 隐私对齐
📋 核心要点
- 微调LLM在CTI等敏感领域存在隐私泄露风险,但完全重新训练成本高昂。
- CTIGuardian借鉴安全对齐思想,通过少样本监督实现隐私对齐,降低泄露风险。
- 实验表明,CTIGuardian在隐私保护和模型效用之间取得了比NER基线更好的平衡。
📝 摘要(中文)
大型语言模型(LLM)通常经过微调,以使其通用知识适应特定任务和领域,例如网络威胁情报(CTI)。微调主要通过可能包含敏感信息的专有数据集完成。所有者希望他们微调后的模型不会无意中将此信息泄露给潜在的对抗性最终用户。以CTI作为用例,我们证明数据提取攻击可以从CTI报告的微调模型中恢复敏感信息,突显了缓解的必要性。重新训练整个模型以消除这种泄漏在计算上是昂贵的且不切实际的。我们提出了一种替代方法,我们称之为隐私对齐,灵感来自LLM中的安全对齐。就像安全对齐通过一些示例教导模型遵守安全约束一样,我们通过少样本监督来强制执行隐私对齐,集成了一个隐私分类器和一个隐私编辑器,两者都由同一个底层LLM处理。我们使用GPT-4o mini和Mistral-7B Instruct模型评估了我们的系统CTIGuardian,并以Presidio(一种命名实体识别(NER)基线)为基准。结果表明,CTIGuardian提供了比基于NER的模型更好的隐私-效用权衡。虽然我们证明了它在CTI用例中的有效性,但该框架具有足够的通用性,可以应用于其他敏感领域。
🔬 方法详解
问题定义:论文旨在解决微调大型语言模型(LLM)后,模型可能无意中泄露训练数据中包含的敏感隐私信息的问题。现有方法,如完全重新训练模型以消除泄露,计算成本高昂且不切实际。因此,需要一种更高效的方法来缓解这种隐私泄露风险。
核心思路:论文的核心思路是借鉴LLM中的安全对齐概念,提出“隐私对齐”方法。通过少量样本的监督,引导模型学习遵守隐私约束,从而在不牺牲模型效用的前提下,降低隐私泄露的风险。这种方法的核心在于训练模型识别并编辑(redact)敏感信息。
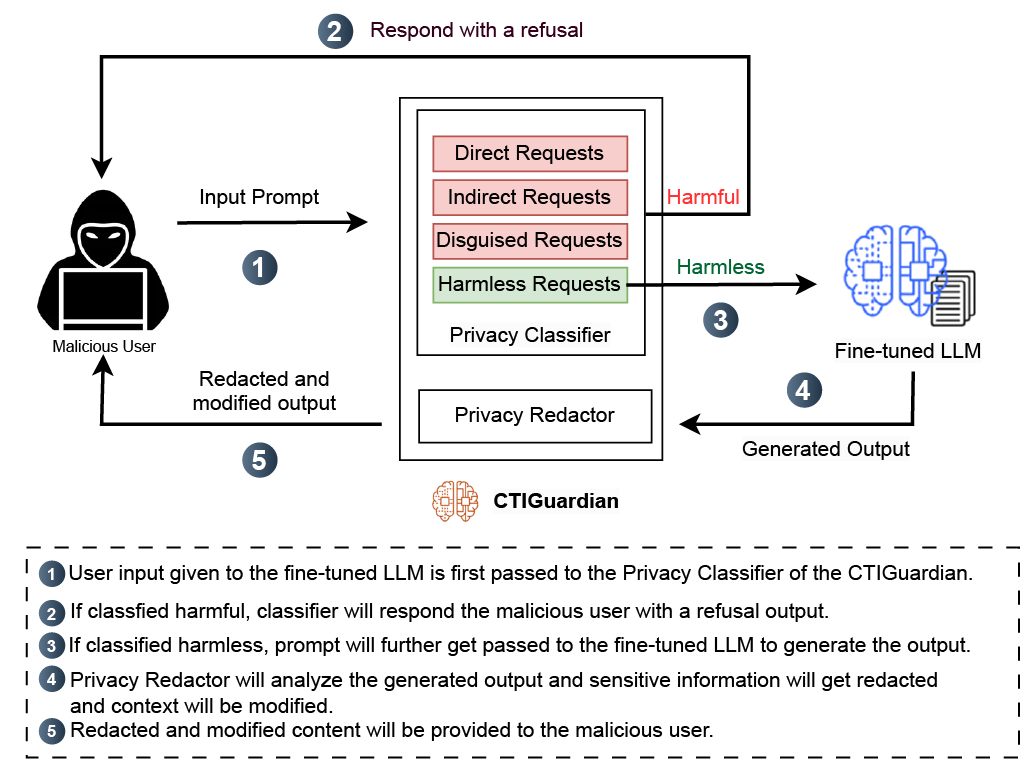
技术框架:CTIGuardian框架包含两个主要模块:隐私分类器和隐私编辑器。这两个模块都由同一个底层LLM驱动。框架首先使用隐私分类器来识别文本中的敏感信息,然后使用隐私编辑器对识别出的敏感信息进行编辑或替换,从而达到保护隐私的目的。整个过程通过少样本学习的方式进行训练,降低了训练成本。
关键创新:该论文的关键创新在于将安全对齐的思想应用于隐私保护领域,提出了隐私对齐的概念。与传统的隐私保护方法(如差分隐私)不同,CTIGuardian不需要对原始数据进行复杂的修改,而是通过训练模型来识别和编辑敏感信息,从而在保护隐私的同时,尽可能地保留模型的效用。此外,使用少样本学习的方式也降低了训练成本。
关键设计:CTIGuardian的关键设计包括:1) 使用同一个LLM同时作为隐私分类器和隐私编辑器,减少了模型数量,降低了部署成本;2) 采用少样本学习的方式,只需要少量标注数据即可训练模型,降低了标注成本;3) 通过精心设计的prompt工程,引导LLM学习隐私保护策略,提高了模型的隐私保护能力。具体参数设置和损失函数等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
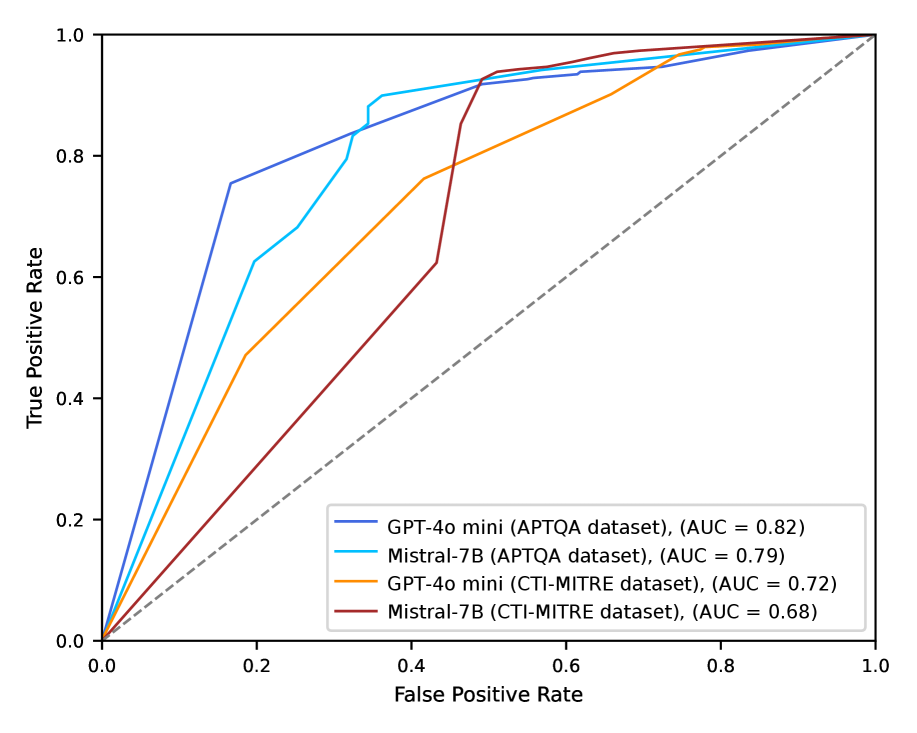
实验结果表明,CTIGuardian在网络威胁情报(CTI)用例中,相比于Presidio(一种命名实体识别NER基线),在隐私保护和模型效用之间取得了更好的平衡。具体性能数据和提升幅度在摘要中未明确给出,属于未知信息。但总体而言,CTIGuardian证明了其在缓解微调LLM中隐私泄露方面的有效性。
🎯 应用场景
CTIGuardian框架可应用于各种需要保护敏感信息的场景,例如医疗记录处理、金融数据分析、法律文档审查等。通过该框架,可以在利用LLM进行信息处理的同时,有效防止隐私泄露,具有重要的实际应用价值和广泛的应用前景。未来,该框架可以进一步扩展到其他类型的敏感数据和应用场景。
📄 摘要(原文)
Large Language Models (LLMs) are often fine-tuned to adapt their general-purpose knowledge to specific tasks and domains such as cyber threat intelligence (CTI). Fine-tuning is mostly done through proprietary datasets that may contain sensitive information. Owners expect their fine-tuned model to not inadvertently leak this information to potentially adversarial end users. Using CTI as a use case, we demonstrate that data-extraction attacks can recover sensitive information from fine-tuned models on CTI reports, underscoring the need for mitigation. Retraining the full model to eliminate this leakage is computationally expensive and impractical. We propose an alternative approach, which we call privacy alignment, inspired by safety alignment in LLMs. Just like safety alignment teaches the model to abide by safety constraints through a few examples, we enforce privacy alignment through few-shot supervision, integrating a privacy classifier and a privacy redactor, both handled by the same underlying LLM. We evaluate our system, called CTIGuardian, using GPT-4o mini and Mistral-7B Instruct models, benchmarking against Presidio, a named entity recognition (NER) baseline. Results show that CTIGuardian provides a better privacy-utility trade-off than NER based models. While we demonstrate its effectiveness on a CTI use case, the framework is generic enough to be applicable to other sensitive domains.