Pre-review to Peer review: Pitfalls of Automating Reviews using Large Language Models
作者: Akhil Pandey Akella, Harish Varma Siravuri, Shaurya Rohatgi
分类: cs.DL, cs.AI, cs.CY
发布日期: 2025-12-14
💡 一句话要点
评估大语言模型在学术评审中的应用,揭示其作为预审工具的潜力和局限性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 学术评审 预审 自然语言处理 论文评估
📋 核心要点
- 现有研究缺乏对LLM生成评审与论文发表后指标(如引用量、新颖性)之间关系的系统评估,未能充分揭示LLM评审的实用性和潜在风险。
- 本研究通过实验评估开源LLM生成评审的质量,并将其与人工评审及论文发表后指标进行对比,旨在探索LLM作为预审工具的可行性。
- 实验结果表明,LLM评审与人工评审相关性较低,但与发表后指标相关性更高,提示LLM可作为预审工具,但需警惕其潜在的偏差和过度自信问题。
📝 摘要(中文)
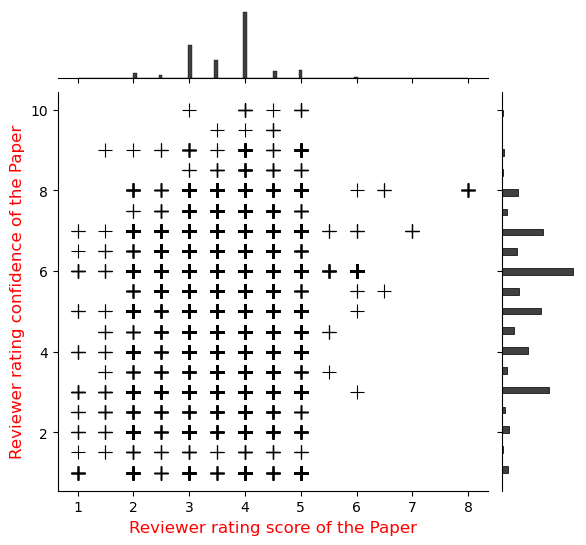
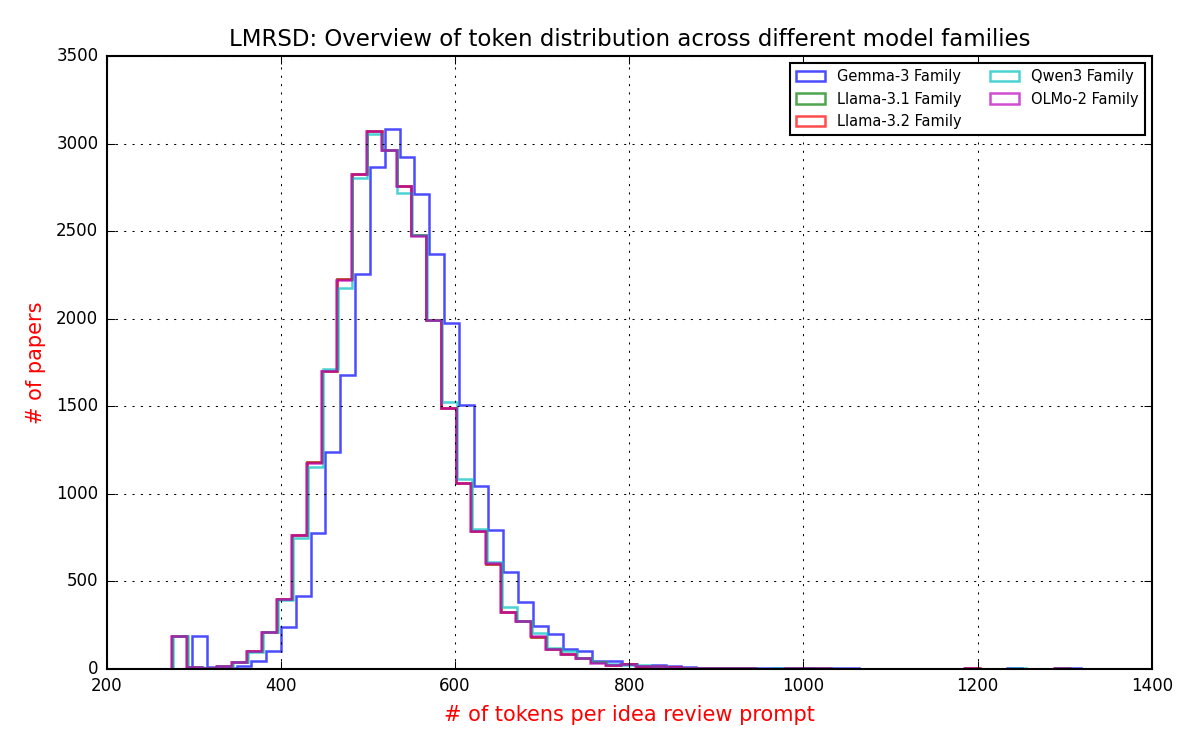
大型语言模型(LLM)是通用的任务解决器,如果作为 extit{预审}代理,而非完全自主的 extit{同行评审}代理,它们的能力可以真正帮助人们进行学术同行评审。虽然自动化学术同行评审非常有益,但作为一个概念,它也引发了对安全性、研究诚信和学术同行评审过程有效性的担忧。大多数系统评估前沿LLM生成跨学科评审的研究,都未能解决评审的对齐/未对齐问题,以及LLM生成的评审与诸如 extbf{引用次数}、 extbf{热门论文}、 extbf{新颖性}和 extbf{颠覆性}等发表结果相比的效用。本文提出了一项实验研究,其中我们收集了来自OpenReview的真实评审员评分,并使用各种前沿的开源LLM生成论文评审,以评估将LLM纳入科学评审流程的安全性与可靠性。我们的研究结果表明,尽管强调了作为自主评审员部署时的基本错位风险,但前沿开源LLM作为预审筛选代理具有实用性。我们的结果表明,所有模型与人类同行评审员的相关性较弱(0.15),存在3-5分的系统性高估偏差,并且尽管存在预测误差,但置信度得分普遍较高(8.0-9.0/10)。然而,我们也观察到LLM评审与发表后指标的相关性高于与人类评分的相关性,这表明其作为预审筛选工具的潜在效用。我们的研究结果突出了使用语言模型自动化同行评审的潜力,并解决了其中的缺陷。我们开源了我们的数据集$D_{LMRSD}$,以帮助研究界扩展自动化科学评审的安全框架。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLM)在学术论文评审中的应用潜力与风险。现有的人工评审过程耗时且成本高昂,因此自动化评审具有吸引力。然而,直接使用LLM进行评审可能存在安全性和可靠性问题,例如评审质量不高、与人工评审不一致、以及可能存在的偏见。
核心思路:论文的核心思路是将LLM定位为“预审”工具,而非完全自主的评审员。通过评估LLM生成的评审与人工评审以及论文发表后指标(如引用量)的相关性,来判断LLM作为预审筛选工具的有效性。这种思路旨在利用LLM的效率,同时避免其潜在的风险。
技术框架:研究主要分为以下几个阶段:1) 数据收集:从OpenReview收集带有真实评审员评分的论文数据。2) LLM评审生成:使用多个开源LLM(具体模型未知)生成对这些论文的评审。3) 评审质量评估:将LLM生成的评审与人工评审进行对比,计算相关性,并分析LLM的偏差和置信度。4) 发表后指标关联:将LLM评审与论文发表后的引用量等指标进行关联,分析LLM评审的预测能力。
关键创新:论文的关键创新在于:1) 系统性地评估了开源LLM在学术评审中的应用潜力,并强调了其作为预审工具的价值。2) 将LLM评审与论文发表后的指标联系起来,从而更全面地评估了LLM评审的有效性。3) 揭示了LLM评审的偏差和过度自信问题,为未来研究提供了重要的参考。
关键设计:论文的关键设计包括:1) 选择OpenReview作为数据来源,保证了评审数据的真实性。2) 使用多个开源LLM进行实验,增加了结果的可靠性。3) 采用相关性分析、偏差分析和置信度分析等多种方法,全面评估LLM评审的质量。具体参数设置、损失函数和网络结构等技术细节在论文中未明确说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LLM评审与人工评审的相关性较低(0.15),存在3-5分的系统性高估偏差,且置信度普遍较高(8.0-9.0/10)。然而,LLM评审与发表后指标的相关性高于与人工评分的相关性,表明其作为预审筛选工具具有潜在价值。研究开源了数据集$D_{LMRSD}$,为相关研究提供了数据基础。
🎯 应用场景
该研究成果可应用于学术出版领域,辅助编辑和评审人员进行论文筛选,提高评审效率。同时,研究揭示了LLM评审的局限性,有助于指导未来LLM评审系统的设计和应用,促进科研诚信和学术质量的提升。未来,可进一步探索如何利用LLM生成更具建设性和洞察力的评审意见。
📄 摘要(原文)
Large Language Models are versatile general-task solvers, and their capabilities can truly assist people with scholarly peer review as \textit{pre-review} agents, if not as fully autonomous \textit{peer-review} agents. While incredibly beneficial, automating academic peer-review, as a concept, raises concerns surrounding safety, research integrity, and the validity of the academic peer-review process. The majority of the studies performing a systematic evaluation of frontier LLMs generating reviews across science disciplines miss the mark on addressing the alignment/misalignment of reviews along with the utility of LLM generated reviews when compared against publication outcomes such as \textbf{Citations}, \textbf{Hit-papers}, \textbf{Novelty}, and \textbf{Disruption}. This paper presents an experimental study in which we gathered ground-truth reviewer ratings from OpenReview and used various frontier open-weight LLMs to generate reviews of papers to gauge the safety and reliability of incorporating LLMs into the scientific review pipeline. Our findings demonstrate the utility of frontier open-weight LLMs as pre-review screening agents despite highlighting fundamental misalignment risks when deployed as autonomous reviewers. Our results show that all models exhibit weak correlation with human peer reviewers (0.15), with systematic overestimation bias of 3-5 points and uniformly high confidence scores (8.0-9.0/10) despite prediction errors. However, we also observed that LLM reviews correlate more strongly with post-publication metrics than with human scores, suggesting potential utility as pre-review screening tools. Our findings highlight the potential and address the pitfalls of automating peer reviews with language models. We open-sourced our dataset $D_{LMRSD}$ to help the research community expand the safety framework of automating scientific reviews.