One Leak Away: How Pretrained Model Exposure Amplifies Jailbreak Risks in Finetuned LLMs
作者: Yixin Tan, Zhe Yu, Jun Sakuma
分类: cs.CR, cs.AI
发布日期: 2025-12-14
备注: 17 pages
💡 一句话要点
揭示预训练模型漏洞:微调LLM中的越狱风险放大效应
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 对抗攻击 越狱攻击 预训练模型 微调 可转移性 表征学习
📋 核心要点
- 现有方法未能充分评估微调LLM继承自预训练模型的安全漏洞,尤其是在对抗性攻击方面。
- 论文提出Probe-Guided Projection (PGP)攻击,通过探针引导优化,提升对抗性提示在预训练模型和微调模型之间的可转移性。
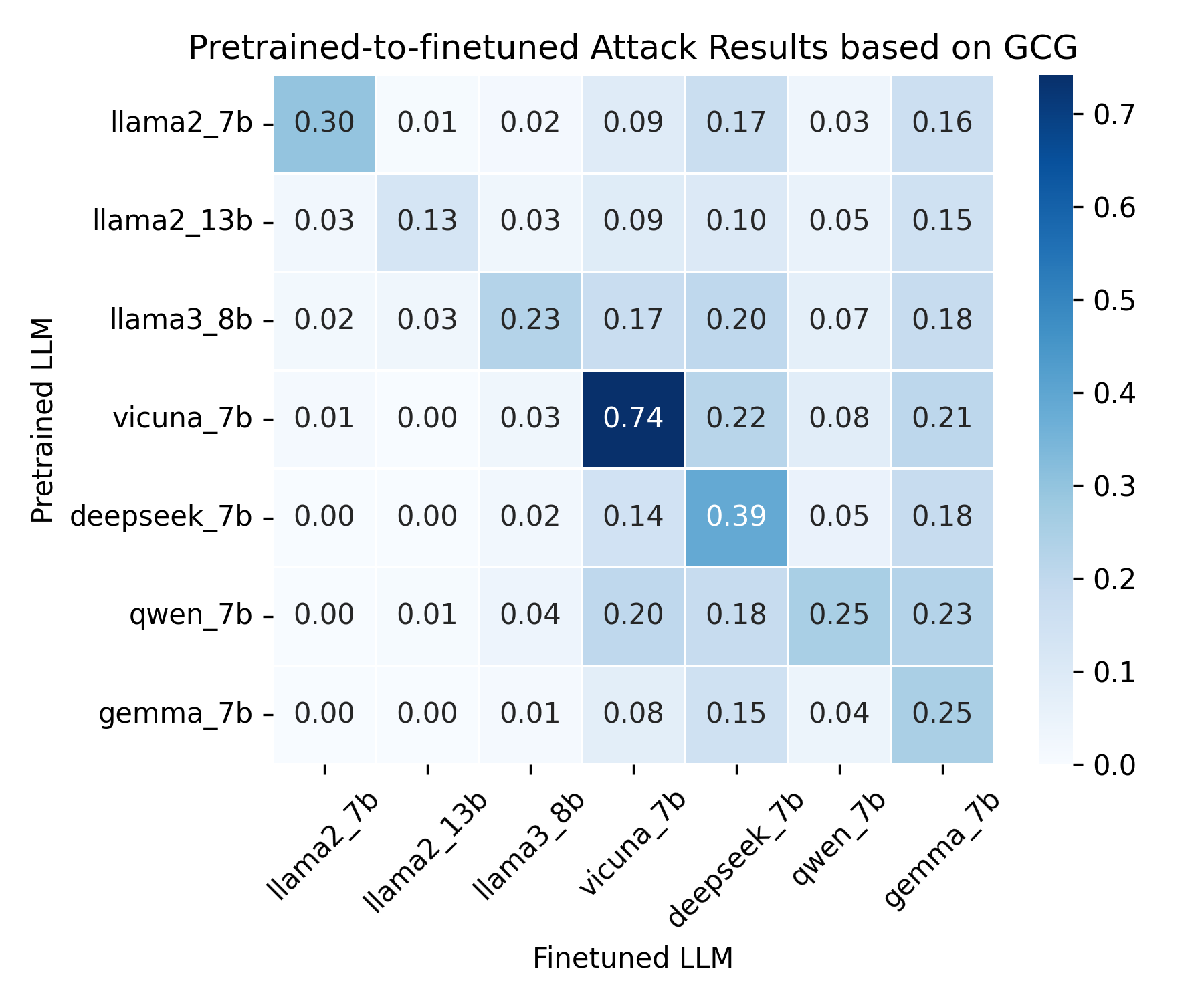
- 实验表明,PGP攻击在多种LLM和微调任务上表现出强大的攻击迁移能力,验证了预训练模型漏洞会传递到微调模型。
📝 摘要(中文)
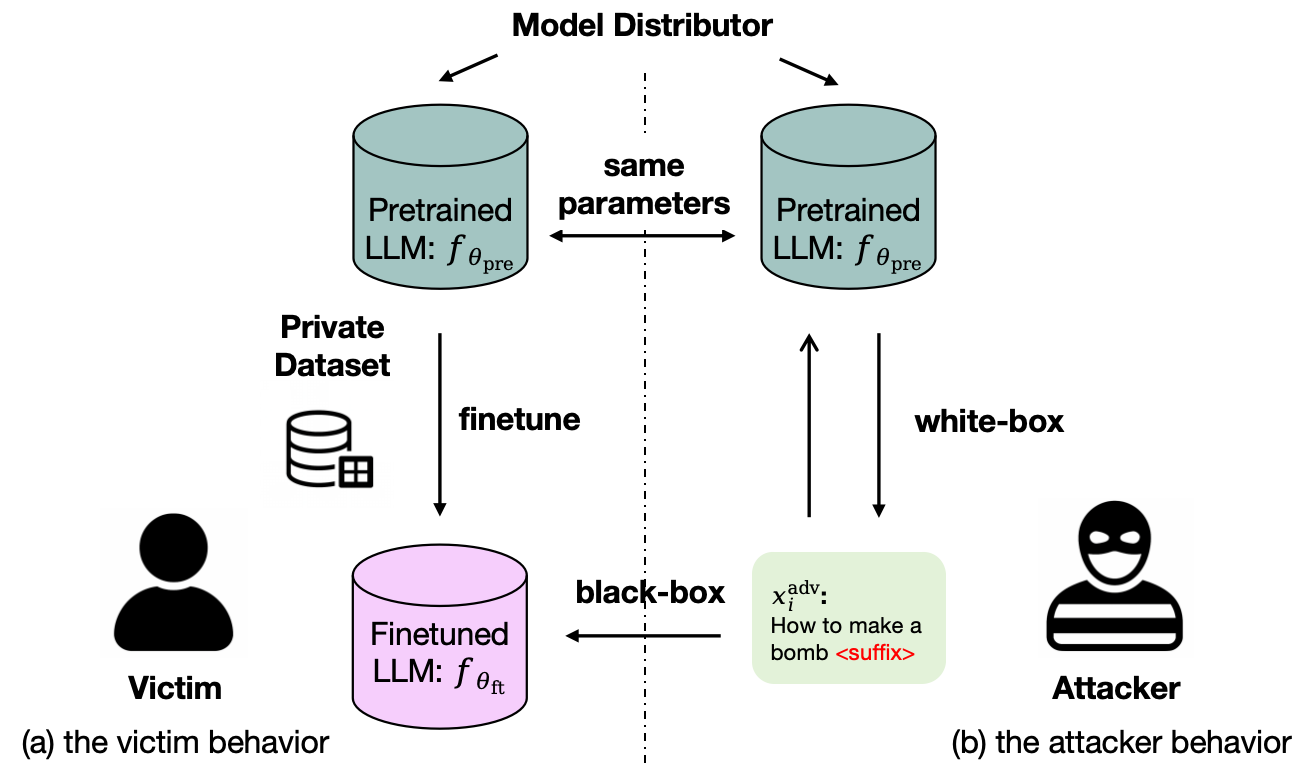
微调预训练大型语言模型(LLMs)已成为开发下游应用的标准范式。然而,其安全性影响尚不清楚,特别是关于微调后的LLMs是否会继承来自预训练源模型的越狱漏洞。本文研究了一个现实的预训练到微调的威胁模型,其中攻击者拥有对预训练LLM的白盒访问权限,而仅对微调后的衍生模型具有黑盒访问权限。实证分析表明,在预训练模型上优化的对抗性提示最有效地转移到其微调变体,揭示了从预训练到微调LLMs的继承漏洞。为了进一步检查这种继承性,本文进行了表征级别的探测,结果表明可转移的提示在预训练的隐藏状态中是线性可分的,这表明通用可转移性被编码在预训练的表征中。基于此,本文提出了一种探针引导投影(PGP)攻击,该攻击将优化导向与可转移性相关的方向。跨多个LLM家族和各种微调任务的实验证实了PGP的强大转移成功,突显了预训练到微调范式中固有的安全风险。
🔬 方法详解
问题定义:论文旨在解决微调后的LLM是否会继承其预训练模型的越狱漏洞的问题。现有方法缺乏对这种继承性的深入研究,并且难以在预训练模型和微调模型之间有效地转移对抗性攻击。现有的对抗攻击方法通常针对特定模型进行优化,难以泛化到其他模型或任务。
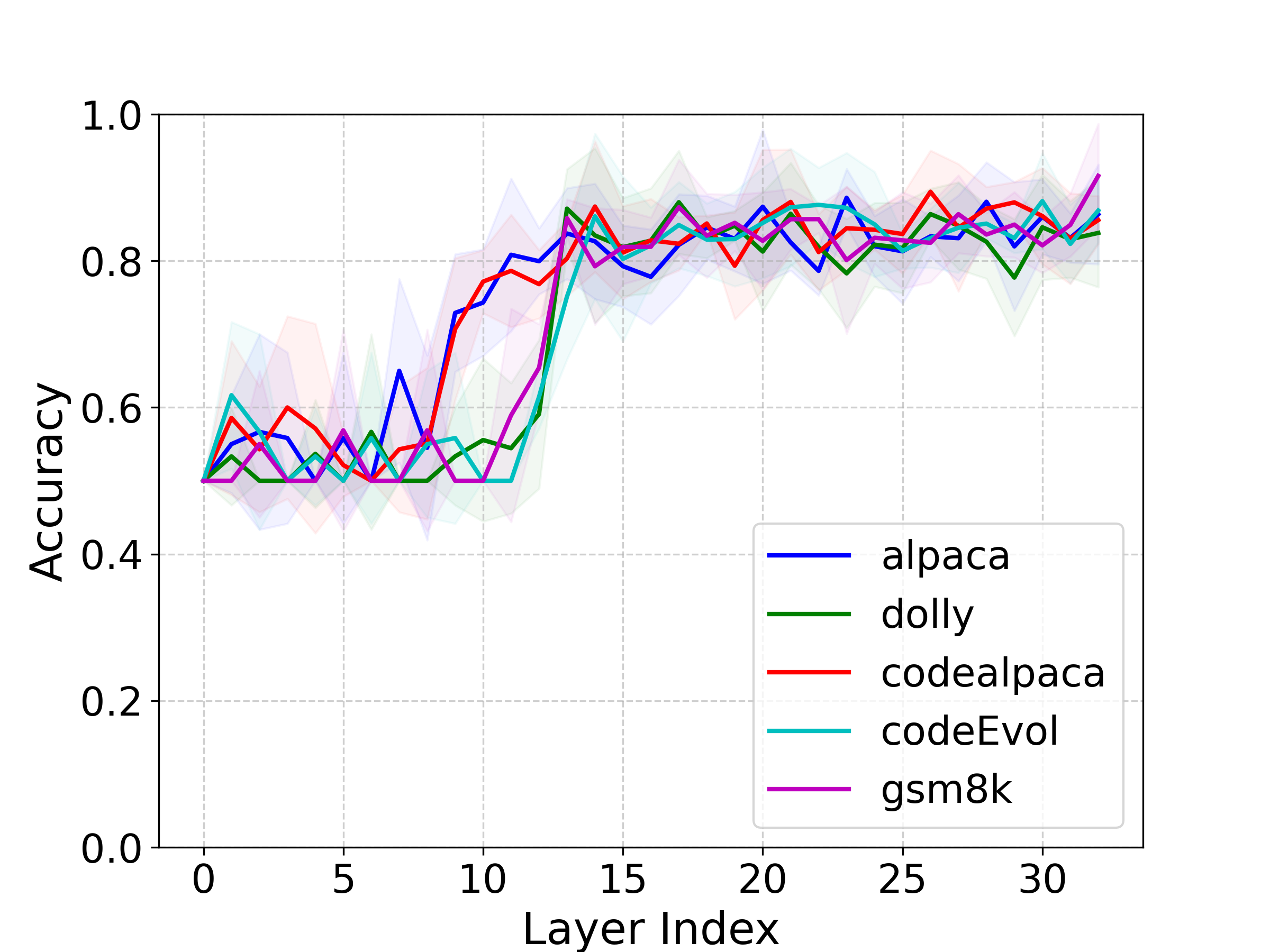
核心思路:论文的核心思路是利用预训练模型的表征空间来指导对抗性提示的生成,从而提高其在微调模型上的可转移性。通过分析预训练模型的隐藏层状态,找到与可转移性相关的方向,并引导对抗性提示的优化过程沿着这些方向进行。
技术框架:论文的技术框架主要包括以下几个步骤:1) 在预训练模型上生成对抗性提示;2) 使用表征探测技术分析预训练模型的隐藏层状态,识别与可转移性相关的方向;3) 提出Probe-Guided Projection (PGP)攻击,该攻击利用探测到的方向来引导对抗性提示的优化过程;4) 在微调模型上评估生成的对抗性提示的攻击效果。
关键创新:论文最重要的技术创新点在于提出了Probe-Guided Projection (PGP)攻击。PGP攻击通过探针引导,将对抗性提示的优化过程导向与可转移性相关的方向,从而显著提高了对抗性提示在预训练模型和微调模型之间的可转移性。与传统的对抗攻击方法相比,PGP攻击能够更有效地利用预训练模型的知识,生成更具泛化能力的对抗性提示。
关键设计:PGP攻击的关键设计包括:1) 使用线性探测技术来识别预训练模型隐藏层状态中与可转移性相关的方向;2) 设计投影算子,将对抗性提示的梯度投影到探测到的方向上,从而引导优化过程;3) 使用对抗损失函数来优化对抗性提示,使其能够成功攻击预训练模型和微调模型。
🖼️ 关键图片
📊 实验亮点
实验结果表明,PGP攻击在多个LLM家族(如Llama、OPT)和各种微调任务上都取得了显著的攻击成功率。与基线方法相比,PGP攻击能够更有效地将对抗性提示从预训练模型转移到微调模型,突显了预训练模型漏洞在微调过程中的放大效应。
🎯 应用场景
该研究成果可应用于提升大型语言模型的安全性,尤其是在预训练-微调范式下。通过理解和缓解预训练模型中的漏洞,可以降低微调模型遭受对抗性攻击的风险。此外,该研究还可以指导安全LLM的开发,例如设计更鲁棒的预训练方法和微调策略。
📄 摘要(原文)
Finetuning pretrained large language models (LLMs) has become the standard paradigm for developing downstream applications. However, its security implications remain unclear, particularly regarding whether finetuned LLMs inherit jailbreak vulnerabilities from their pretrained sources. We investigate this question in a realistic pretrain-to-finetune threat model, where the attacker has white-box access to the pretrained LLM and only black-box access to its finetuned derivatives. Empirical analysis shows that adversarial prompts optimized on the pretrained model transfer most effectively to its finetuned variants, revealing inherited vulnerabilities from pretrained to finetuned LLMs. To further examine this inheritance, we conduct representation-level probing, which shows that transferable prompts are linearly separable within the pretrained hidden states, suggesting that universal transferability is encoded in pretrained representations. Building on this insight, we propose the Probe-Guided Projection (PGP) attack, which steers optimization toward transferability-relevant directions. Experiments across multiple LLM families and diverse finetuned tasks confirm PGP's strong transfer success, underscoring the security risks inherent in the pretrain-to-finetune paradigm.