Adaptive Edge-Cloud Inference for Speech-to-Action Systems Using ASR and Large Language Models
作者: Mohammad Jalili Torkamani, Israt Zarin
分类: cs.SD, cs.AI
发布日期: 2025-12-14 (更新: 2025-12-18)
备注: preprint, 6 pages, 7 figures, 1 table
💡 一句话要点
提出ASTA:一种自适应边缘-云语音指令系统,平衡性能与资源利用。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 边缘计算 云计算 语音识别 自然语言处理 物联网 自适应系统 资源管理
📋 核心要点
- 边缘设备在语音交互中面临云端高精度与本地低延迟的权衡,现有方法难以兼顾。
- ASTA通过实时系统指标驱动的边缘-云自适应路由,动态选择推理路径,平衡性能与资源。
- 实验表明ASTA能成功路由所有指令,并在边缘和云端推理间取得平衡,验证了方案可行性。
📝 摘要(中文)
本文提出了一种名为ASTA的自适应语音到动作解决方案,用于动态地在边缘和云推理之间路由语音命令,以平衡性能和系统资源利用率。ASTA集成了设备上的自动语音识别(ASR)和轻量级离线语言模型推理,以及基于云的LLM处理,并由CPU负载、设备温度和网络延迟等实时系统指标指导。一种感知指标的路由机制在运行时选择推理路径,而基于规则的命令验证和修复组件确保成功的端到端命令执行。该解决方案在基于NVIDIA Jetson的边缘平台上实现,并使用包含80个口语命令的多样化数据集进行评估。实验结果表明,ASTA成功地路由所有输入命令以供执行,并在在线和离线推理之间实现了平衡的分配。系统实现了62.5%的ASR准确率,并且仅为47.5%的输入生成无需修复的可执行命令,突出了修复机制在提高鲁棒性方面的重要性。这些结果表明,自适应边缘-云编排是弹性且资源感知的语音控制物联网系统的可行方法。
🔬 方法详解
问题定义:语音控制的物联网设备需要在云端的高精度语言理解能力和边缘端的低延迟、隐私保护之间进行权衡。现有的边缘设备受限于计算资源,无法提供与云端相媲美的语言理解能力,而完全依赖云端则会引入延迟、网络依赖和隐私问题。
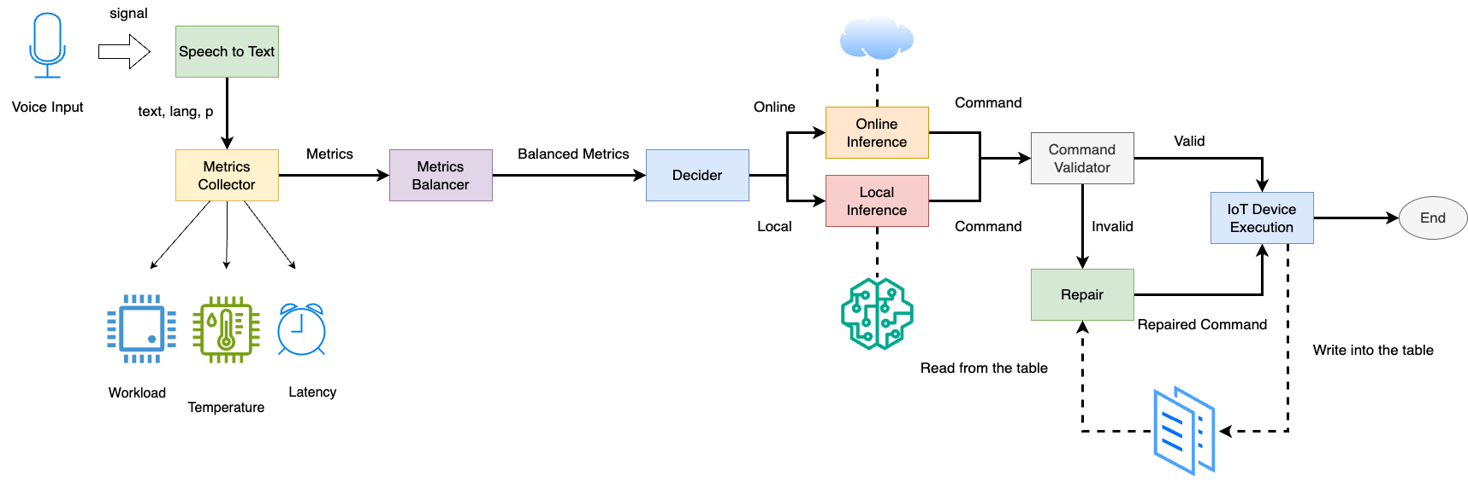
核心思路:ASTA的核心思路是根据实时的系统资源状况(如CPU负载、设备温度、网络延迟)动态地将语音命令路由到边缘或云端进行处理。对于简单的、对延迟敏感的命令,在边缘端进行快速处理;对于复杂的、需要更高精度的命令,则路由到云端进行处理。这种自适应的路由策略旨在平衡性能和资源利用率。
技术框架:ASTA系统主要包含以下几个模块:1) 设备端ASR:在设备上进行初步的语音识别。2) 轻量级离线语言模型:用于在设备端进行快速的命令解析。3) 云端LLM处理:利用云端强大的计算资源和语言模型进行更复杂的命令理解。4) 指标感知路由机制:根据实时系统指标决定将命令路由到边缘或云端。5) 命令验证与修复:对解析后的命令进行验证,并在必要时进行修复,以确保命令的正确执行。
关键创新:ASTA的关键创新在于其自适应的边缘-云路由机制。该机制能够根据实时的系统资源状况动态地调整推理路径,从而在性能、延迟和资源利用率之间取得平衡。与传统的静态边缘或云端推理方法相比,ASTA能够更好地适应不同的应用场景和系统状态。
关键设计:ASTA的路由机制是其核心。具体实现细节未知,但可以推测其可能使用了一系列阈值来判断当前系统状态是否适合在边缘端进行推理。例如,如果CPU负载过高或网络延迟过大,则将命令路由到云端。命令验证与修复模块的具体实现细节也未知,但可以推测其可能使用了基于规则或机器学习的方法来检测和纠正命令中的错误。
🖼️ 关键图片


📊 实验亮点
ASTA在包含80个口语命令的数据集上进行了评估,结果表明该系统能够成功路由所有输入命令以供执行,并在在线和离线推理之间实现了平衡的分配。系统实现了62.5%的ASR准确率,并且仅为47.5%的输入生成无需修复的可执行命令,突出了修复机制在提高鲁棒性方面的重要性。这些结果验证了自适应边缘-云编排在语音控制物联网系统中的可行性。
🎯 应用场景
ASTA适用于各种语音控制的物联网设备,例如智能家居设备、可穿戴设备和工业控制系统。通过自适应地利用边缘和云端的计算资源,ASTA可以提高语音交互的响应速度、降低延迟,并改善用户体验。此外,ASTA还可以降低对网络连接的依赖,并提高设备的隐私保护能力。未来,ASTA有望成为构建更智能、更高效的语音控制物联网系统的关键技术。
📄 摘要(原文)
Voice-based interaction has emerged as a natural and intuitive modality for controlling IoT devices. However, speech-driven edge devices face a fundamental trade-off between cloud-based solutions, which offer stronger language understanding capabilities at the cost of latency, connectivity dependence, and privacy concerns, and edge-based solutions, which provide low latency and improved privacy but are limited by computational constraints. This paper presents ASTA, an adaptive speech-to-action solution that dynamically routes voice commands between edge and cloud inference to balance performance and system resource utilization. ASTA integrates on-device automatic speech recognition and lightweight offline language-model inference with cloud-based LLM processing, guided by real-time system metrics such as CPU workload, device temperature, and network latency. A metric-aware routing mechanism selects the inference path at runtime, while a rule-based command validation and repair component ensures successful end-to-end command execution. We implemented our solution on an NVIDIA Jetson-based edge platform and evaluated it using a diverse dataset of 80 spoken commands. Experimental results show that ASTA successfully routes all input commands for execution, achieving a balanced distribution between online and offline inference. The system attains an ASR accuracy of 62.5% and generates executable commands without repair for only 47.5% of inputs, highlighting the importance of the repair mechanism in improving robustness. These results suggest that adaptive edge-cloud orchestration is a viable approach for resilient and resource-aware voice-controlled IoT systems.