Large Language Newsvendor: Decision Biases and Cognitive Mechanisms
作者: Jifei Liu, Zhi Chen, Yuanguang Zhong
分类: cs.AI
发布日期: 2025-12-14
💡 一句话要点
研究表明大型语言模型在新报童问题中存在决策偏差,且可能放大人类认知偏误
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 决策偏差 新报童问题 认知偏误 供应链管理
📋 核心要点
- 现有方法未能充分理解大型语言模型在商业决策中可能放大人类认知偏差的风险,尤其是在供应链管理等高风险场景。
- 本研究通过动态新报童问题,分析了GPT-4、GPT-4o和LLaMA-8B等LLMs的决策模式,旨在识别和理解其认知偏差。
- 实验发现LLMs会复制并放大“过低/过高”订购偏差和需求追逐行为,表明架构约束而非知识差距是偏差的根源。
📝 摘要(中文)
尽管大型语言模型(LLMs)越来越多地被整合到商业决策中,但它们复制甚至放大人类认知偏差的潜力,预示着一种重大但尚未被充分理解的风险。这在供应链管理等高风险运营环境中尤为关键。为了解决这个问题,我们使用动态环境下的经典新报童问题,研究了领先LLMs的决策模式,旨在识别其认知偏差的性质和来源。通过对GPT-4、GPT-4o和LLaMA-8B进行动态、多轮实验,我们测试了五种已知的决策偏差。我们发现,与人类基准相比,LLMs始终如一地复制了经典的“过低/过高”订购偏差,并显著放大了其他倾向,如需求追逐行为。我们的分析揭示了一个“智能悖论”:更复杂的GPT-4通过过度思考表现出最大的非理性,而效率优化的GPT-4o表现接近最优。由于即使提供了最优公式,这些偏差仍然存在,我们得出结论,它们源于架构约束,而不是知识差距。管理者应该根据具体任务选择模型,因为我们的结果表明,效率优化的模型在某些优化问题上可以胜过更复杂的模型。LLMs对偏差的显著放大凸显了在高风险决策中迫切需要强大的人工监督,以防止代价高昂的错误。我们的研究结果表明,设计结构化的、基于规则的提示是管理者约束模型启发式倾向并提高人工智能辅助决策可靠性的实用有效策略。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLMs)在经典的新报童问题中的决策行为,并识别和分析其存在的认知偏差。现有方法未能充分理解LLMs在商业决策中可能放大人类认知偏差的风险,尤其是在供应链管理等高风险场景下,可能导致代价高昂的错误。
核心思路:论文的核心思路是通过模拟动态的新报童问题,让LLMs进行多轮决策,并观察其订货量与最优订货量之间的偏差。通过对比不同LLMs(GPT-4, GPT-4o, LLaMA-8B)的决策模式,以及与人类基准的比较,来揭示LLMs的认知偏差类型和程度。同时,通过提供最优公式,排除知识差距的影响,从而推断偏差的根源。
技术框架:整体框架包括以下几个主要阶段:1) 问题设定:构建动态的新报童问题,包括需求分布、成本参数等;2) 模型选择:选择GPT-4、GPT-4o和LLaMA-8B等LLMs作为决策主体;3) 实验设计:设计多轮决策实验,每轮LLMs根据历史需求信息给出订货量;4) 偏差分析:分析LLMs的订货量与最优订货量之间的偏差,识别认知偏差类型和程度;5) 原因探究:通过提供最优公式,排除知识差距的影响,从而推断偏差的根源。
关键创新:论文的关键创新在于:1) 系统性地研究了LLMs在新报童问题中的决策偏差,揭示了LLMs可能放大人类认知偏差的风险;2) 发现了“智能悖论”,即更复杂的GPT-4通过过度思考表现出更大的非理性;3) 证明了LLMs的决策偏差源于架构约束,而非知识差距。与现有方法相比,本研究更深入地探讨了LLMs决策偏差的根源,并提出了针对性的管理建议。
关键设计:实验中,需求分布采用正态分布,成本参数包括单位进货成本和单位销售价格。LLMs通过自然语言提示进行交互,提示中包含历史需求信息和成本参数。最优公式以自然语言的形式提供给LLMs,以排除知识差距的影响。偏差分析采用统计方法,计算LLMs的订货量与最优订货量之间的偏差,并进行显著性检验。
🖼️ 关键图片


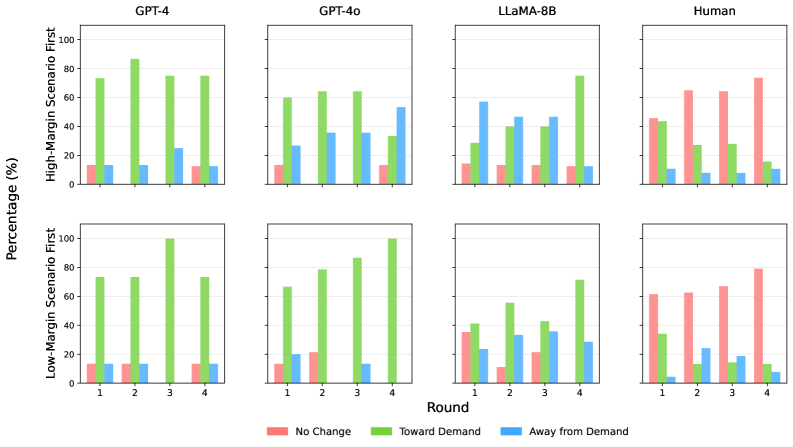
📊 实验亮点
实验结果表明,LLMs在新报童问题中普遍存在决策偏差,例如“过低/过高”订购偏差和需求追逐行为。与人类基准相比,LLMs显著放大了这些偏差。值得注意的是,GPT-4表现出最大的非理性,而效率优化的GPT-4o表现接近最优。即使提供了最优公式,这些偏差仍然存在,表明偏差源于架构约束。这些发现对LLMs在商业决策中的应用具有重要意义。
🎯 应用场景
该研究成果可应用于供应链管理、库存控制、定价策略等领域,帮助企业更好地利用大型语言模型进行决策。通过了解LLMs的认知偏差,管理者可以采取相应的措施,例如设计结构化的提示、引入人工监督等,以提高AI辅助决策的可靠性和准确性,避免因偏差导致的损失。未来,该研究可以扩展到其他决策场景,并探索更有效的偏差缓解方法。
📄 摘要(原文)
Problem definition: Although large language models (LLMs) are increasingly integrated into business decision making, their potential to replicate and even amplify human cognitive biases cautions a significant, yet not well-understood, risk. This is particularly critical in high-stakes operational contexts like supply chain management. To address this, we investigate the decision-making patterns of leading LLMs using the canonical newsvendor problem in a dynamic setting, aiming to identify the nature and origins of their cognitive biases. Methodology/results: Through dynamic, multi-round experiments with GPT-4, GPT-4o, and LLaMA-8B, we tested for five established decision biases. We found that LLMs consistently replicated the classic
Too Low/Too High'' ordering bias and significantly amplified other tendencies like demand-chasing behavior compared to human benchmarks. Our analysis uncovered aparadox of intelligence'': the more sophisticated GPT-4 demonstrated the greatest irrationality through overthinking, while the efficiency-optimized GPT-4o performed near-optimally. Because these biases persist even when optimal formulas are provided, we conclude they stem from architectural constraints rather than knowledge gaps. Managerial implications: First, managers should select models based on the specific task, as our results show that efficiency-optimized models can outperform more complex ones on certain optimization problems. Second, the significant amplification of bias by LLMs highlights the urgent need for robust human-in-the-loop oversight in high-stakes decisions to prevent costly errors. Third, our findings suggest that designing structured, rule-based prompts is a practical and effective strategy for managers to constrain models' heuristic tendencies and improve the reliability of AI-assisted decisions.