World Models Unlock Optimal Foraging Strategies in Reinforcement Learning Agents
作者: Yesid Fonseca, Manuel S. Ríos, Nicanor Quijano, Luis F. Giraldo
分类: cs.AI, cs.LG
发布日期: 2025-12-14 (更新: 2025-12-27)
备注: 14 pages, 6 figures
💡 一句话要点
基于世界模型的强化学习智能体解锁最优觅食策略
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 世界模型 强化学习 觅食策略 边际价值定理 模型预测控制
📋 核心要点
- 生物觅食策略优化是一个复杂问题,现有方法难以解释生物觅食行为背后的计算机制。
- 该论文提出使用基于世界模型的强化学习智能体,通过学习环境的预测表示来模拟生物觅食行为。
- 实验表明,该方法能够使智能体收敛到与边际价值定理对齐的策略,并表现出与生物相似的决策模式。
📝 摘要(中文)
斑块觅食涉及确定何时离开资源丰富的区域并探索潜在的更有益替代方案的最佳时间。边际价值定理(MVT)常用于描述这一过程,为这种觅食行为提供了一个最优模型。尽管该模型已被广泛用于预测行为生态学,但促进生物觅食者做出最优斑块觅食决策的计算机制仍在研究中。本文表明,配备学习到的世界模型的人工觅食者自然会收敛到与MVT对齐的策略。通过使用一种基于模型的强化学习智能体,该智能体获得了对其环境的简约预测表示,我们证明了预期能力,而不仅仅是奖励最大化,驱动了有效的斑块离开行为。与标准无模型RL智能体相比,这些基于模型的智能体表现出与许多生物对应物相似的决策模式,表明预测性世界模型可以作为AI系统中更具可解释性和生物学基础的决策的基础。总的来说,我们的发现突出了生态最优性原则对于推进可解释和自适应AI的价值。
🔬 方法详解
问题定义:论文旨在解决如何通过人工智能方法模拟生物觅食行为,特别是斑块觅食中的最优离开时间决策问题。现有强化学习方法,尤其是无模型方法,难以解释生物觅食行为背后的决策机制,缺乏生物学上的合理性。
核心思路:论文的核心思路是利用世界模型赋予强化学习智能体预测能力,使其能够预测不同决策带来的长期后果,从而做出更优的觅食决策。这种预测能力被认为是生物觅食行为的关键驱动因素,而不仅仅是简单的奖励最大化。
技术框架:整体框架包含一个基于模型的强化学习智能体,该智能体通过与环境交互学习一个世界模型。该世界模型能够预测环境的未来状态和奖励。智能体利用该世界模型进行规划,选择能够最大化预期回报的动作。具体流程包括:1)智能体与环境交互,收集经验数据;2)利用经验数据训练世界模型;3)利用世界模型进行规划,选择动作;4)执行动作,获得奖励和新的环境状态;5)重复上述步骤。
关键创新:论文的关键创新在于将世界模型引入到觅食行为的建模中,并证明了世界模型能够使智能体自然地收敛到与边际价值定理对齐的策略。这表明预测能力在觅食决策中起着重要作用,而不仅仅是奖励最大化。此外,该方法提供了一种更具可解释性和生物学合理性的觅食行为建模方法。
关键设计:论文中,世界模型采用循环神经网络(RNN)进行建模,用于预测环境的未来状态和奖励。损失函数包括状态预测误差和奖励预测误差。智能体使用模型预测控制(MPC)进行规划,选择能够最大化预期回报的动作。实验中,对智能体的探索策略、奖励函数等参数进行了调整,以提高学习效率和性能。
🖼️ 关键图片
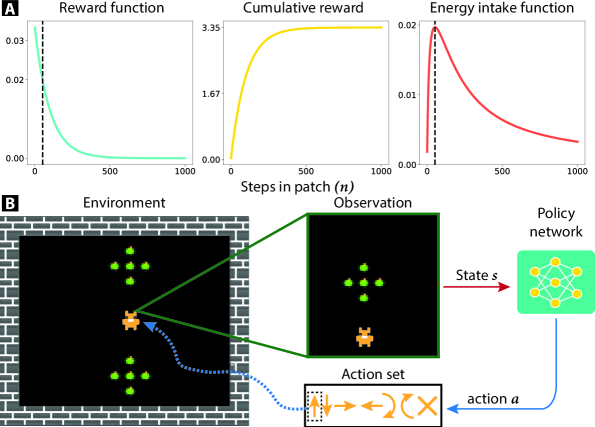


📊 实验亮点
实验结果表明,配备世界模型的强化学习智能体能够有效地学习最优的斑块觅食策略,并收敛到与边际价值定理(MVT)对齐的策略。与传统的无模型强化学习智能体相比,该方法能够更好地模拟生物觅食行为,并表现出更强的适应性和泛化能力。具体而言,基于世界模型的智能体在不同环境下的觅食效率更高,且决策模式更接近生物。
🎯 应用场景
该研究成果可应用于机器人自主导航、资源管理、搜索救援等领域。通过模拟生物觅食策略,可以设计出更智能、更高效的机器人系统,使其能够在复杂环境中自主地寻找资源、规划路径和做出决策。此外,该研究也有助于理解生物智能的本质,为人工智能的发展提供新的思路。
📄 摘要(原文)
Patch foraging involves the deliberate and planned process of determining the optimal time to depart from a resource-rich region and investigate potentially more beneficial alternatives. The Marginal Value Theorem (MVT) is frequently used to characterize this process, offering an optimality model for such foraging behaviors. Although this model has been widely used to make predictions in behavioral ecology, discovering the computational mechanisms that facilitate the emergence of optimal patch-foraging decisions in biological foragers remains under investigation. Here, we show that artificial foragers equipped with learned world models naturally converge to MVT-aligned strategies. Using a model-based reinforcement learning agent that acquires a parsimonious predictive representation of its environment, we demonstrate that anticipatory capabilities, rather than reward maximization alone, drive efficient patch-leaving behavior. Compared with standard model-free RL agents, these model-based agents exhibit decision patterns similar to many of their biological counterparts, suggesting that predictive world models can serve as a foundation for more explainable and biologically grounded decision-making in AI systems. Overall, our findings highlight the value of ecological optimality principles for advancing interpretable and adaptive AI.