Diverse LLMs vs. Vulnerabilities: Who Detects and Fixes Them Better?
作者: Arastoo Zibaeirad, Marco Vieira
分类: cs.SE, cs.AI
发布日期: 2025-12-14
🔗 代码/项目: GITHUB
💡 一句话要点
DVDR-LLM:集成多种LLM提升软件漏洞检测与修复能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 软件漏洞检测 软件漏洞修复 集成学习 代码安全
📋 核心要点
- 现有单个LLM在复杂漏洞检测和修复方面存在局限性,难以满足实际需求。
- DVDR-LLM通过集成多个LLM的输出来提高漏洞检测的准确性和鲁棒性。
- 实验表明,DVDR-LLM在检测准确率、召回率和F1分数上均优于单个LLM。
📝 摘要(中文)
大型语言模型(LLMs)越来越多地被用于软件漏洞检测(SVD)和修复(SVR)的研究。虽然单个LLM展现出一定的代码理解能力,但在识别复杂漏洞和生成修复方案时常常表现不佳。本研究提出了DVDR-LLM,一个集成框架,它结合了来自不同LLM的输出来确定聚合多个模型是否能降低错误率。评估结果表明,DVDR-LLM的检测准确率比单个模型的平均性能高出10-12%,并且随着代码复杂性的增加,优势更加明显。对于多文件漏洞,集成方法在召回率(+18%)和F1分数(+11.8%)方面比单个模型有显著提高。然而,该方法也带来了一些权衡:在验证任务中减少了假阳性,但在检测任务中增加了假阴性,因此需要仔细决定LLM之间达成一致的程度(阈值),以便在不同的安全上下文中提高性能。
🔬 方法详解
问题定义:论文旨在解决软件漏洞检测与修复(SVD/SVR)中,单个大型语言模型(LLM)在处理复杂或多文件漏洞时表现不佳的问题。现有方法依赖于单个LLM,容易受到模型自身偏差和知识覆盖范围的限制,导致检测准确率和修复质量不高。尤其是在多文件漏洞场景下,单个LLM难以捕捉跨文件的依赖关系,从而影响检测效果。
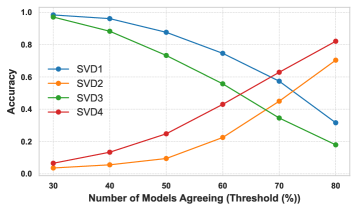
核心思路:论文的核心思路是利用集成学习的思想,通过聚合多个不同LLM的输出来提高漏洞检测和修复的性能。这种方法旨在利用不同LLM在代码理解、漏洞模式识别等方面的互补优势,从而降低错误率,提高整体的准确性和鲁棒性。通过设置合适的阈值,可以控制集成模型的敏感度和特异性,以适应不同的安全需求。
技术框架:DVDR-LLM框架主要包含以下几个阶段:1) 输入处理:接收待检测的代码片段或项目。2) LLM推理:将代码输入到多个不同的LLM中进行漏洞检测和修复建议生成。3) 结果聚合:对来自不同LLM的输出进行整合,例如通过投票或加权平均等方式。4) 阈值判断:根据预设的阈值,判断是否存在漏洞或采纳修复建议。5) 输出结果:输出最终的漏洞检测结果和修复建议。
关键创新:该论文的关键创新在于提出了一个基于集成学习的漏洞检测与修复框架DVDR-LLM,它通过聚合多个LLM的输出来提高性能。与传统的单个LLM方法相比,DVDR-LLM能够更好地利用不同模型的优势,降低错误率,尤其是在处理复杂和多文件漏洞时表现更佳。此外,通过调整LLM之间达成一致的程度(阈值),可以灵活地平衡假阳性和假阴性,以适应不同的安全上下文。
关键设计:DVDR-LLM的关键设计包括:1) LLM选择:选择具有不同架构、训练数据和代码理解能力的LLM,以保证模型的多样性。2) 聚合策略:采用投票、加权平均等策略来整合不同LLM的输出,权重可以根据LLM的性能或可靠性进行调整。3) 阈值设置:设置合适的阈值来控制集成模型的敏感度和特异性,阈值的大小会影响假阳性和假阴性的比例。4) 多文件漏洞处理:针对多文件漏洞,设计专门的跨文件依赖关系分析模块,以提高检测准确率。
🖼️ 关键图片

📊 实验亮点
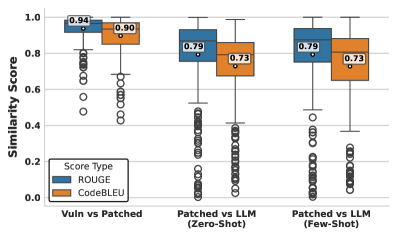
实验结果表明,DVDR-LLM在漏洞检测准确率上比单个LLM的平均性能提高了10-12%。对于多文件漏洞,DVDR-LLM在召回率上提升了18%,F1分数提升了11.8%。这些结果表明,集成多个LLM可以显著提高漏洞检测的性能,尤其是在处理复杂漏洞时。同时,研究也指出了集成方法在假阳性和假阴性之间的权衡,需要根据实际应用场景进行调整。
🎯 应用场景
DVDR-LLM可应用于软件开发生命周期的多个阶段,例如代码审查、安全测试和漏洞修复。它可以帮助开发人员更有效地识别和修复代码中的安全漏洞,提高软件的安全性。此外,该框架还可以用于自动化漏洞分析和渗透测试,从而提高安全团队的工作效率。未来,该研究可以扩展到支持更多的编程语言和漏洞类型,并与其他安全工具集成。
📄 摘要(原文)
Large Language Models (LLMs) are increasingly being studied for Software Vulnerability Detection (SVD) and Repair (SVR). Individual LLMs have demonstrated code understanding abilities, but they frequently struggle when identifying complex vulnerabilities and generating fixes. This study presents DVDR-LLM, an ensemble framework that combines outputs from diverse LLMs to determine whether aggregating multiple models reduces error rates. Our evaluation reveals that DVDR-LLM achieves 10-12% higher detection accuracy compared to the average performance of individual models, with benefits increasing as code complexity grows. For multi-file vulnerabilities, the ensemble approach demonstrates significant improvements in recall (+18%) and F1 score (+11.8%) over individual models. However, the approach raises measurable trade-offs: reducing false positives in verification tasks while simultaneously increasing false negatives in detection tasks, requiring careful decision on the required level of agreement among the LLMs (threshold) for increased performance across different security contexts. Artifact: https://github.com/Erroristotle/DVDR_LLM