Compressed Causal Reasoning: Quantization and GraphRAG Effects on Interventional and Counterfactual Accuracy
作者: Steve Nwaiwu, Nipat Jongsawat, Anucha Tungkasthan
分类: cs.AI
发布日期: 2025-12-13 (更新: 2025-12-24)
💡 一句话要点
研究量化和图检索增强生成对大语言模型因果推理能力的影响
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 因果推理 大语言模型 量化 图检索增强生成 反事实推理
📋 核心要点
- 现有大语言模型在资源受限环境下进行因果推理时,量化带来的精度损失影响尚不明确。
- 该研究系统评估了量化(INT8, NF4)对大语言模型在Pearl因果阶梯三个层级因果推理能力的影响。
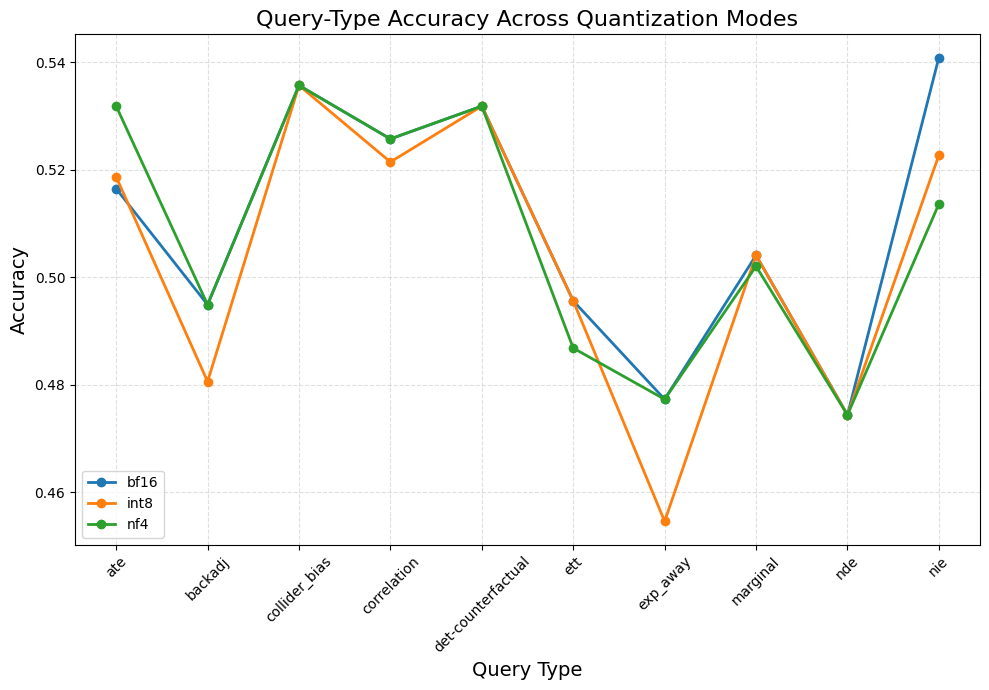
- 实验表明,量化对因果推理能力影响较小,图检索增强生成可提升干预推理精度,现有反事实基准缺乏敏感性。
📝 摘要(中文)
在大型语言模型中,涵盖关联、干预和反事实推理的因果推理对于高风险环境下的可靠决策至关重要。随着部署转向边缘和资源受限环境,INT8和NF4等量化模型正成为标准。然而,精度降低对形式化因果推理的影响知之甚少。据我们所知,这是第一个系统地评估量化效应对Pearl因果阶梯所有三个层级影响的研究。使用一个3000样本的分层CLadder基准,我们发现Llama 3 8B的阶梯层级精度在量化下保持大致稳定,NF4的总体退化小于百分之一。第二层级的干预查询对精度损失最敏感,而第三层级的反事实推理相对稳定,但在诸如碰撞偏差和后门调整等查询类型中表现出异构弱点。在CRASS基准上的实验表明,不同精度之间的性能几乎相同,表明现有的常识反事实数据集缺乏揭示量化引起的推理漂移所需的结构敏感性。我们进一步评估了使用ground truth因果图的图检索增强生成,并观察到NF4干预精度的持续提高,达到1.7个百分点,部分抵消了压缩相关的退化。这些结果表明,因果推理对四位量化具有出乎意料的鲁棒性,图结构增强可以选择性地加强干预推理,并且当前的反事实基准未能捕捉到更深层次的因果脆弱性。这项工作提供了压缩因果推理的初步经验图,并为部署高效且结构支持的因果AI系统提供了实用指导。
🔬 方法详解
问题定义:论文旨在研究在将大型语言模型部署到资源受限的环境中时,模型量化(例如,使用INT8或NF4精度)对模型因果推理能力的影响。现有的研究缺乏对量化如何影响模型在Pearl因果阶梯的不同层级(关联、干预和反事实推理)上进行推理的系统性评估,并且现有的反事实基准可能无法充分捕捉到量化引起的推理漂移。
核心思路:论文的核心思路是通过构建一个分层的因果推理基准(CLadder)并结合现有的反事实推理基准(CRASS),系统地评估不同量化级别(包括INT8和NF4)的大型语言模型(Llama 3 8B)在执行因果推理任务时的性能。此外,论文还探索了使用图检索增强生成(Graph RAG)来缓解量化可能导致的性能下降。
技术框架:该研究的技术框架主要包括以下几个部分: 1. 因果推理基准构建:构建一个包含3000个样本的分层CLadder基准,用于评估模型在关联、干预和反事实推理三个层级的性能。 2. 模型量化:对Llama 3 8B模型进行不同级别的量化,包括INT8和NF4。 3. 性能评估:使用CLadder和CRASS基准评估量化模型在因果推理任务上的性能,并分析不同量化级别对不同推理类型的具体影响。 4. 图检索增强生成:使用ground truth因果图进行图检索增强生成,以提高模型的干预推理能力。
关键创新:该研究的创新点在于: 1. 系统性评估:首次系统地评估了量化对大型语言模型在Pearl因果阶梯所有三个层级因果推理能力的影响。 2. 图检索增强:探索了使用图检索增强生成来提高量化模型的干预推理能力,并验证了其有效性。 3. 基准分析:发现现有反事实基准(CRASS)缺乏揭示量化引起的推理漂移所需的结构敏感性。
关键设计: 1. CLadder基准:该基准包含3000个样本,并根据Pearl因果阶梯的三个层级进行分层,以确保对不同推理类型的全面评估。 2. Graph RAG:使用ground truth因果图作为知识源,通过检索与当前推理任务相关的子图来增强模型的推理能力。 3. 评估指标:使用准确率作为主要评估指标,并针对不同推理类型进行细致的分析。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Llama 3 8B在NF4量化下,因果推理精度仅下降不到1%。图检索增强生成可使NF4量化模型的干预推理精度提高1.7%。同时,研究发现现有反事实推理基准对量化引起的推理漂移不敏感,需要更具结构敏感性的基准。
🎯 应用场景
该研究成果可应用于对资源受限设备上的因果推理系统进行优化,例如在边缘设备上部署医疗诊断、金融风控等需要可靠决策的AI系统。通过量化和图检索增强,可以在保证推理精度的前提下,降低模型大小和计算复杂度,从而实现高效部署。
📄 摘要(原文)
Causal reasoning in Large Language Models spanning association, intervention, and counterfactual inference is essential for reliable decision making in high stakes settings. As deployment shifts toward edge and resource constrained environments, quantized models such as INT8 and NF4 are becoming standard. Yet the impact of precision reduction on formal causal reasoning is poorly understood. To our knowledge, this is the first study to systematically evaluate quantization effects across all three levels of Pearls Causal Ladder. Using a 3000 sample stratified CLadder benchmark, we find that rung level accuracy in Llama 3 8B remains broadly stable under quantization, with NF4 showing less than one percent overall degradation. Interventional queries at rung 2 are the most sensitive to precision loss, whereas counterfactual reasoning at rung 3 is comparatively stable but exhibits heterogeneous weaknesses across query types such as collider bias and backdoor adjustment. Experiments on the CRASS benchmark show near identical performance across precisions, indicating that existing commonsense counterfactual datasets lack the structural sensitivity needed to reveal quantization induced reasoning drift. We further evaluate Graph Retrieval Augmented Generation using ground truth causal graphs and observe a consistent improvement in NF4 interventional accuracy of plus 1.7 percent, partially offsetting compression related degradation. These results suggest that causal reasoning is unexpectedly robust to four bit quantization, graph structured augmentation can selectively reinforce interventional reasoning, and current counterfactual benchmarks fail to capture deeper causal brittleness. This work provides an initial empirical map of compressed causal reasoning and practical guidance for deploying efficient and structurally supported causal AI systems.