V-Rex: Real-Time Streaming Video LLM Acceleration via Dynamic KV Cache Retrieval
作者: Donghyuk Kim, Sejeong Yang, Wonjin Shin, Joo-Young Kim
分类: eess.IV, cs.AI, cs.AR, cs.CV, cs.MM
发布日期: 2025-12-13 (更新: 2025-12-24)
备注: 14 pages, 20 figures, conference, accepted by HPCA 2026
💡 一句话要点
V-Rex:通过动态KV缓存检索加速实时流视频LLM推理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 流视频LLM KV缓存 动态检索 边缘计算 硬件加速 软硬件协同设计 实时推理
📋 核心要点
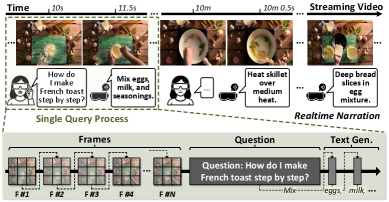
- 现有流视频LLM推理面临KV缓存随视频流增长带来的内存和计算挑战,尤其是在边缘设备上,迭代预填充阶段导致计算量大、数据传输多和精度下降。
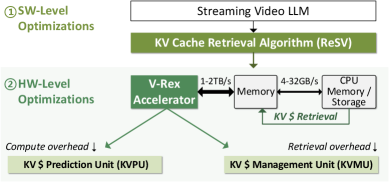
- V-Rex提出了一种软硬件协同设计的加速器,核心是ReSV算法,通过时空相似性token聚类减少KV缓存内存,并设计了低延迟的动态KV缓存检索引擎(DRE)。
- V-Rex在边缘部署上实现了3.9-8.3 FPS的实时推理,相比AGX Orin GPU,速度提升1.9-19.7倍,能效提升3.1-18.5倍,且精度损失可忽略不计。
📝 摘要(中文)
流视频大语言模型(LLM)越来越多地应用于实时多模态任务,如视频字幕生成、问答、对话代理和增强现实。然而,这些模型面临着根本的内存和计算挑战,因为它们的键值(KV)缓存随着连续的流视频输入而显著增长。这个过程需要一个迭代的预填充阶段,这是流视频LLM的一个独特特征。由于其迭代的预填充阶段,它面临着显著的限制,包括大量的计算、大量的数据传输和精度的降低。至关重要的是,这个问题对于边缘部署来说更加严重,而边缘部署是这些模型的主要目标。本文提出了V-Rex,这是第一个软硬件协同设计的加速器,它全面解决了流视频LLM推理中的算法和硬件瓶颈。V-Rex的核心是ReSV,一种无需训练的动态KV缓存检索算法。ReSV利用基于时间和空间相似性的token聚类来减少跨视频帧的过度KV缓存内存。为了充分实现这些算法优势,V-Rex提供了一个紧凑、低延迟的硬件加速器,带有一个动态KV缓存检索引擎(DRE),具有基于位级和早退出的计算单元。V-Rex在边缘部署上实现了前所未有的3.9-8.3 FPS的实时性和节能的流视频LLM推理,且精度损失可忽略不计。虽然DRE仅占2.2%的功耗和2.0%的面积,但该系统比AGX Orin GPU提供了1.9-19.7倍的速度提升和3.1-18.5倍的能效提升。这项工作是第一个全面解决跨算法和硬件的KV缓存检索问题的工作,从而能够在资源受限的边缘设备上实现实时流视频LLM推理。
🔬 方法详解
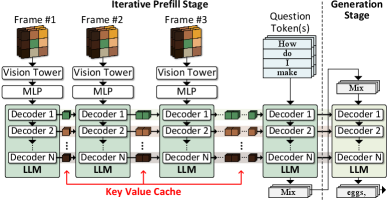
问题定义:论文旨在解决流视频LLM在边缘设备上实时推理时,由于KV缓存不断增长导致的内存和计算瓶颈问题。现有方法在处理连续视频流时,需要对每一帧进行预填充,造成大量的冗余计算和数据传输,降低了推理速度和能效,并且难以在资源受限的边缘设备上部署。
核心思路:论文的核心思路是利用视频帧之间的时间和空间相似性,动态地检索和重用KV缓存中的信息,从而减少冗余计算和内存占用。通过减少需要存储和处理的KV缓存大小,可以显著提高推理速度和能效,使其更适合在边缘设备上部署。
技术框架:V-Rex的整体框架包含两个主要部分:ReSV算法和DRE硬件加速器。ReSV算法负责动态KV缓存检索,通过token聚类减少KV缓存大小。DRE硬件加速器则专门用于加速ReSV算法的计算,包括位级计算和早退出机制。整个流程包括:视频帧输入 -> ReSV算法进行token聚类和KV缓存检索 -> DRE硬件加速器加速计算 -> LLM推理 -> 输出结果。
关键创新:该论文的关键创新在于提出了ReSV算法,这是一种无需训练的动态KV缓存检索算法,能够有效地减少KV缓存的大小,同时保持推理精度。此外,软硬件协同设计也是一个创新点,通过专门设计的DRE硬件加速器,充分利用了ReSV算法的优势,实现了更高的推理速度和能效。
关键设计:ReSV算法的关键设计包括:1) 基于时间和空间相似性的token聚类方法,用于识别和合并相似的token,从而减少KV缓存的大小;2) 动态KV缓存检索机制,用于根据当前帧的内容,选择性地检索和重用之前的KV缓存信息。DRE硬件加速器的关键设计包括:1) 位级计算单元,用于高效地执行ReSV算法中的计算;2) 早退出机制,用于在计算过程中提前终止不必要的计算,进一步提高能效。具体参数设置和损失函数等细节在论文中未明确说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
V-Rex在边缘设备(AGX Orin)上实现了3.9-8.3 FPS的实时流视频LLM推理,相比于AGX Orin GPU,速度提升了1.9-19.7倍,能效提升了3.1-18.5倍,同时保持了可忽略不计的精度损失。DRE硬件加速器仅占总功耗的2.2%和面积的2.0%,却带来了显著的性能提升,证明了软硬件协同设计的有效性。
🎯 应用场景
该研究成果可广泛应用于需要实时视频理解的边缘计算场景,例如智能监控、自动驾驶、增强现实、机器人等。通过在资源受限的设备上实现高效的流视频LLM推理,可以为这些应用提供更强大的感知和决策能力,从而提升用户体验和应用价值。未来,该技术有望推动更多基于视频的AI应用在边缘设备上的普及。
📄 摘要(原文)
Streaming video large language models (LLMs) are increasingly used for real-time multimodal tasks such as video captioning, question answering, conversational agents, and augmented reality. However, these models face fundamental memory and computational challenges because their key-value (KV) caches grow substantially with continuous streaming video input. This process requires an iterative prefill stage, which is a unique feature of streaming video LLMs. Due to its iterative prefill stage, it suffers from significant limitations, including extensive computation, substantial data transfer, and degradation in accuracy. Crucially, this issue is exacerbated for edge deployment, which is the primary target for these models. In this work, we propose V-Rex, the first software-hardware co-designed accelerator that comprehensively addresses both algorithmic and hardware bottlenecks in streaming video LLM inference. At its core, V-Rex introduces ReSV, a training-free dynamic KV cache retrieval algorithm. ReSV exploits temporal and spatial similarity-based token clustering to reduce excessive KV cache memory across video frames. To fully realize these algorithmic benefits, V-Rex offers a compact, low-latency hardware accelerator with a dynamic KV cache retrieval engine (DRE), featuring bit-level and early-exit based computing units. V-Rex achieves unprecedented real-time of 3.9-8.3 FPS and energy-efficient streaming video LLM inference on edge deployment with negligible accuracy loss. While DRE only accounts for 2.2% power and 2.0% area, the system delivers 1.9-19.7x speedup and 3.1-18.5x energy efficiency improvements over AGX Orin GPU. This work is the first to comprehensively tackle KV cache retrieval across algorithms and hardware, enabling real-time streaming video LLM inference on resource-constrained edge devices.