Floorplan2Guide: LLM-Guided Floorplan Parsing for BLV Indoor Navigation
作者: Aydin Ayanzadeh, Tim Oates
分类: cs.AI
发布日期: 2025-12-13
备注: Accepted for publication in the proceedings of the IEEE International Conference on Big Data (IEEE BigData 2025)
💡 一句话要点
Floorplan2Guide:利用LLM引导的户型图解析,助力视障人士室内导航
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 室内导航 户型图解析 大型语言模型 知识图谱 视障辅助
📋 核心要点
- 现有室内导航方案依赖基础设施,难以在动态环境中安全导航,对视障人士构成挑战。
- Floorplan2Guide利用LLM从户型图中提取空间信息,构建可导航知识图谱并生成导航指令。
- 实验表明,少量样本学习提升导航准确性,Claude 3.7 Sonnet模型表现最佳,图结构优于直接视觉推理。
📝 摘要(中文)
本文提出了一种新颖的导航方法Floorplan2Guide,旨在帮助视障人士进行室内导航。该方法利用大型语言模型(LLM)将户型图转换为可导航的知识图谱,并生成人类可读的导航指令,从而减少了传统户型图解析方法所需的人工预处理。实验结果表明,在模拟和真实环境评估中,少量样本学习(few-shot learning)相比于零样本学习(zero-shot learning)提高了导航准确性。在MP-1户型图的5-shot提示下,Claude 3.7 Sonnet模型取得了最高的准确率,在短、中、长路线上的准确率分别为92.31%、76.92%和61.54%。基于图的空间结构成功率比所有模型中直接视觉推理高15.4%,证实了图形表示和上下文学习增强了导航性能,使该解决方案更精确地服务于盲人和低视力(BLV)用户的室内导航。
🔬 方法详解
问题定义:现有的室内导航系统主要依赖于预先部署的基础设施,这限制了它们在动态变化环境中的应用,尤其对于视障人士而言,在没有基础设施支持的环境中安全导航是一个挑战。传统户型图解析方法需要大量的人工预处理,效率较低且成本较高。
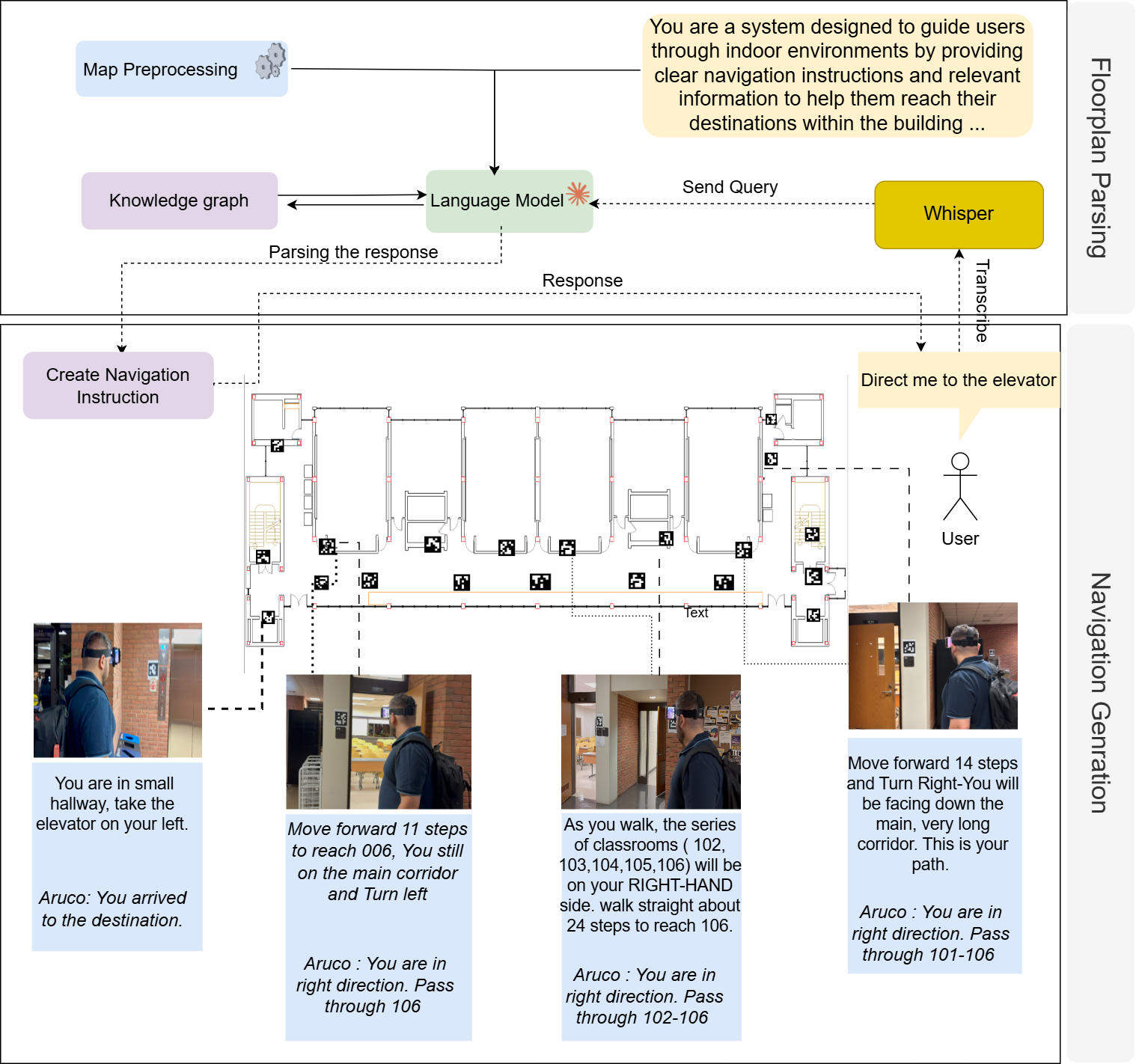
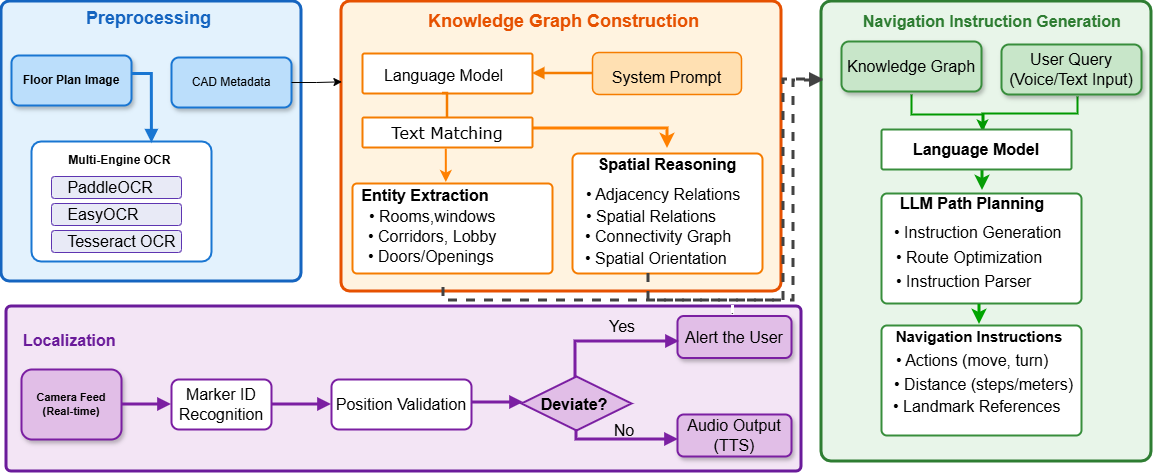
核心思路:Floorplan2Guide的核心思路是利用大型语言模型(LLM)的强大语义理解和推理能力,自动从户型图中提取空间信息,构建可导航的知识图谱,并生成易于理解的导航指令。通过LLM的引导,减少了人工预处理的需求,提高了户型图解析的效率和自动化程度。
技术框架:Floorplan2Guide主要包含以下几个阶段:1) 户型图输入:接收建筑户型图作为输入。2) LLM引导的户型图解析:利用LLM对户型图进行解析,提取房间、走廊、门等空间要素及其相互关系。3) 知识图谱构建:将提取的空间信息转换为可导航的知识图谱,节点表示空间位置,边表示连接关系。4) 导航指令生成:根据用户设定的起点和终点,在知识图谱上规划路径,并生成人类可读的导航指令。
关键创新:该方法最重要的创新点在于利用LLM进行户型图解析,从而减少了人工预处理的需求。与传统的基于规则或机器学习的户型图解析方法相比,Floorplan2Guide能够更好地理解户型图的语义信息,并能够处理复杂的户型结构。此外,利用知识图谱进行路径规划和导航指令生成,提高了导航的准确性和可靠性。
关键设计:论文中使用了Claude 3.7 Sonnet等LLM模型,并采用了少量样本学习(few-shot learning)的方法来提高模型的性能。通过提供少量的户型图和对应的导航指令作为示例,引导LLM学习如何从户型图中提取空间信息并生成导航指令。实验中对比了不同LLM模型和不同提示策略(如零样本学习和少量样本学习)的性能,并评估了在模拟和真实环境中的导航准确性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Floorplan2Guide在模拟和真实环境中均取得了良好的导航效果。在MP-1户型图的5-shot提示下,Claude 3.7 Sonnet模型在短、中、长路线上的准确率分别达到了92.31%、76.92%和61.54%。此外,基于图的空间结构成功率比所有模型中直接视觉推理高15.4%,验证了图形表示和上下文学习的有效性。
🎯 应用场景
Floorplan2Guide具有广泛的应用前景,可用于商场、办公楼、医院等室内环境的导航,尤其适用于帮助视障人士进行独立自主的室内导航。该研究成果还可以应用于机器人导航、智能家居等领域,提升室内空间智能化水平。未来,该技术有望与视觉辅助设备结合,为视障人士提供更全面的导航解决方案。
📄 摘要(原文)
Indoor navigation remains a critical challenge for people with visual impairments. The current solutions mainly rely on infrastructure-based systems, which limit their ability to navigate safely in dynamic environments. We propose a novel navigation approach that utilizes a foundation model to transform floor plans into navigable knowledge graphs and generate human-readable navigation instructions. Floorplan2Guide integrates a large language model (LLM) to extract spatial information from architectural layouts, reducing the manual preprocessing required by earlier floorplan parsing methods. Experimental results indicate that few-shot learning improves navigation accuracy in comparison to zero-shot learning on simulated and real-world evaluations. Claude 3.7 Sonnet achieves the highest accuracy among the evaluated models, with 92.31%, 76.92%, and 61.54% on the short, medium, and long routes, respectively, under 5-shot prompting of the MP-1 floor plan. The success rate of graph-based spatial structure is 15.4% higher than that of direct visual reasoning among all models, which confirms that graphical representation and in-context learning enhance navigation performance and make our solution more precise for indoor navigation of Blind and Low Vision (BLV) users.