Rethinking Label Consistency of In-Context Learning: An Implicit Transductive Label Propagation Perspective
作者: Haoyang Chen, Richong Zhang, Junfan Chen
分类: cs.AI
发布日期: 2025-12-13
💡 一句话要点
提出TopK-SD方法,通过合成数据提升上下文学习中的标签一致性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 上下文学习 标签一致性 转导学习 标签传播 数据合成
📋 核心要点
- 现有上下文学习方法在选择提示示例时,忽略了标签一致性,导致性能受限。
- 论文将上下文学习视为转导学习,通过标签传播框架将标签一致性与误差界限联系起来。
- 提出了TopK-SD方法,利用合成数据选择具有一致标签的示例,并在多个基准测试中超越了TopK采样。
📝 摘要(中文)
大型语言模型(LLMs)通过上下文学习(ICL)在少量监督示例下执行任务,这有益于各种自然语言处理(NLP)任务。一个关键的研究重点是提示示例的选择。目前的方法通常采用检索模型来选择Top-K个语义上最相似的示例作为演示。然而,我们认为现有方法存在局限性,因为在演示选择过程中无法保证标签一致性。我们的认知源于ICL的贝叶斯视角以及我们从转导标签传播角度对ICL的重新思考。我们将ICL视为一种转导学习方法,并结合贝叶斯视角的潜在概念,推导出相似的演示引导查询的概念,而一致的标签则作为估计。基于这种理解,我们建立了一个标签传播框架,将标签一致性与传播误差界限联系起来。为了建模标签一致性,我们提出了一种数据合成方法,利用语义和标签信息,并使用带有合成数据的TopK采样(TopK-SD)来获取具有一致标签的演示。在多个基准测试中,TopK-SD优于原始的TopK采样。我们的工作为理解ICL内部的工作机制提供了一个新的视角。
🔬 方法详解
问题定义:现有上下文学习方法,如TopK采样,主要依赖语义相似性选择示例,忽略了标签一致性。这导致选择的示例可能与查询在概念上不一致,从而影响模型的预测准确性。现有方法缺乏对标签一致性的显式建模和优化。
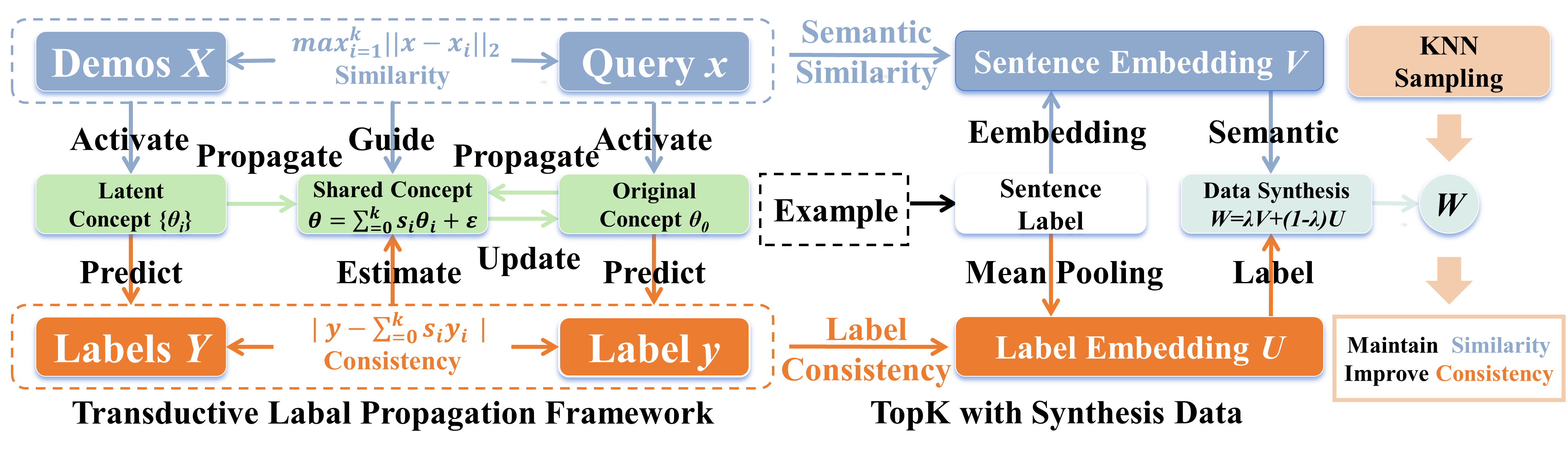
核心思路:论文的核心思路是将上下文学习视为一种转导学习过程,并从贝叶斯视角出发,认为相似的示例应该引导查询的概念,并且这些示例的标签应该与查询的标签保持一致。通过建立标签传播框架,将标签一致性与传播误差界限联系起来,从而指导示例选择。
技术框架:论文提出的TopK-SD方法主要包含以下几个阶段:1) 数据合成:利用语义和标签信息合成新的数据样本,用于增强示例选择的鲁棒性。2) 相似度计算:计算查询与所有候选示例(包括合成数据)之间的语义相似度。3) 标签一致性评估:评估候选示例与查询之间的标签一致性。4) TopK采样:根据相似度和标签一致性,选择TopK个最合适的示例作为上下文。
关键创新:论文的关键创新在于:1) 将上下文学习与转导学习联系起来,提出了新的理论视角。2) 提出了标签传播框架,用于建模和优化标签一致性。3) 提出了数据合成方法,用于增强示例选择的鲁棒性。与现有方法相比,TopK-SD显式地考虑了标签一致性,并利用合成数据来提高示例选择的质量。
关键设计:数据合成方法是关键设计之一,具体实现细节未知。TopK采样过程中,如何平衡语义相似度和标签一致性,可能涉及到加权或者排序策略,具体细节未知。损失函数的设计也未知,可能涉及到标签传播误差的最小化。
🖼️ 关键图片

📊 实验亮点
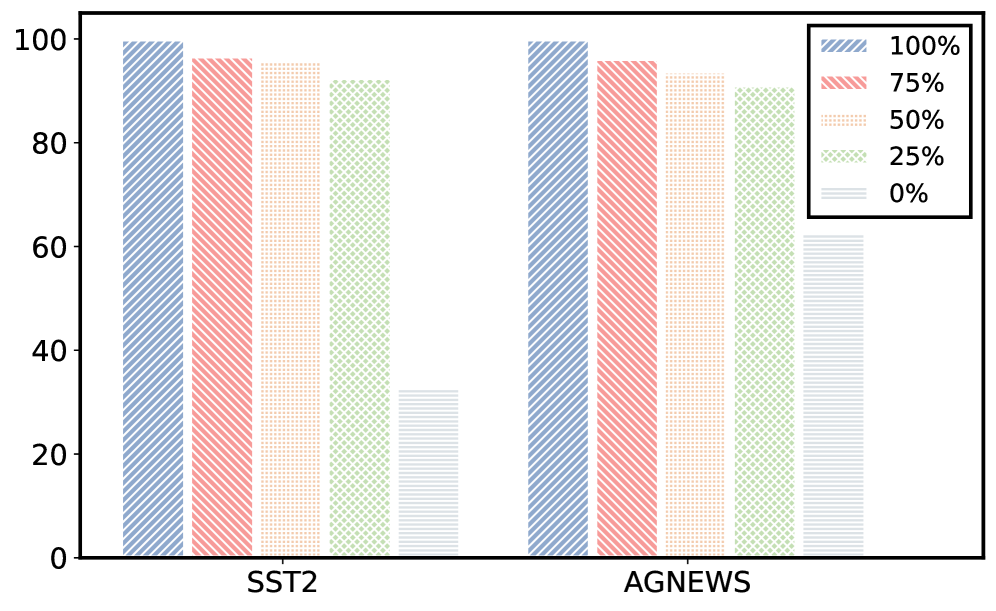
TopK-SD方法在多个基准测试中优于原始的TopK采样,表明了标签一致性在上下文学习中的重要性。具体的性能提升数据未知,但论文强调了TopK-SD在选择具有一致标签的演示方面的优势。实验结果验证了论文提出的理论框架和方法的有效性。
🎯 应用场景
该研究成果可应用于各种自然语言处理任务,例如文本分类、情感分析、问答系统等。通过提升上下文学习中的标签一致性,可以提高模型的泛化能力和鲁棒性,尤其是在数据量有限或标签噪声较大的情况下。该方法还可以应用于few-shot learning和zero-shot learning等场景,降低对标注数据的依赖。
📄 摘要(原文)
Large language models (LLMs) perform in-context learning (ICL) with minimal supervised examples, which benefits various natural language processing (NLP) tasks. One of the critical research focus is the selection of prompt demonstrations. Current approaches typically employ retrieval models to select the top-K most semantically similar examples as demonstrations. However, we argue that existing methods are limited since the label consistency is not guaranteed during demonstration selection. Our cognition derives from the Bayesian view of ICL and our rethinking of ICL from the transductive label propagation perspective. We treat ICL as a transductive learning method and incorporate latent concepts from Bayesian view and deduce that similar demonstrations guide the concepts of query, with consistent labels serving as estimates. Based on this understanding, we establish a label propagation framework to link label consistency with propagation error bounds. To model label consistency, we propose a data synthesis method, leveraging both semantic and label information, and use TopK sampling with Synthetic Data (TopK-SD) to acquire demonstrations with consistent labels. TopK-SD outperforms original TopK sampling on multiple benchmarks. Our work provides a new perspective for understanding the working mechanisms within ICL.