Persistent Backdoor Attacks under Continual Fine-Tuning of LLMs
作者: Jing Cui, Yufei Han, Jianbin Jiao, Junge Zhang
分类: cs.CR, cs.AI
发布日期: 2025-12-12
💡 一句话要点
P-Trojan:一种在LLM持续微调下保持持久性的后门攻击方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 后门攻击 大型语言模型 持续微调 梯度对齐 模型安全
📋 核心要点
- 现有后门攻击研究较少关注LLM在部署后持续微调场景下的持久性问题,简单注入的后门容易在更新后失效。
- P-Trojan通过对齐中毒梯度与干净任务梯度,使得后门映射在后续更新中不易被抑制或遗忘,从而提升后门持久性。
- 实验表明,P-Trojan在Qwen2.5和LLaMA3等LLM上,以及不同的任务序列中,实现了超过99%的后门持久性,同时保持了干净任务的准确性。
📝 摘要(中文)
后门攻击将恶意行为嵌入到大型语言模型(LLMs)中,使攻击者能够触发有害输出或绕过安全控制。然而,用户驱动的部署后持续微调下植入后门的持久性很少被研究。先前的工作主要评估发布时植入后门的有效性和泛化性,经验证据表明,简单注入的后门持久性会在更新后降低。本文研究了植入的后门如何在多阶段部署后微调中保持持久性。我们提出了一种基于触发器的攻击算法P-Trojan,它显式地优化了跨重复更新的后门持久性。通过将中毒梯度与token嵌入上的干净任务梯度对齐,植入的后门映射不太可能在后续更新中被抑制或遗忘。理论分析表明了持续微调后这种持久性后门攻击的可行性。在Qwen2.5和LLaMA3系列LLM以及不同的任务序列上进行的实验表明,P-Trojan在保持干净任务准确性的同时,实现了超过99%的持久性。我们的研究结果强调了在实际模型适应流程中进行持久性感知评估和更强防御的必要性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在经过用户驱动的持续微调后,植入的后门攻击的持久性问题。现有方法主要关注后门攻击的有效性和泛化性,而忽略了模型在实际部署后会经历多次微调更新,导致后门效果逐渐减弱甚至消失的现象。因此,如何设计一种能够在持续微调过程中保持高持久性的后门攻击是本研究的核心问题。
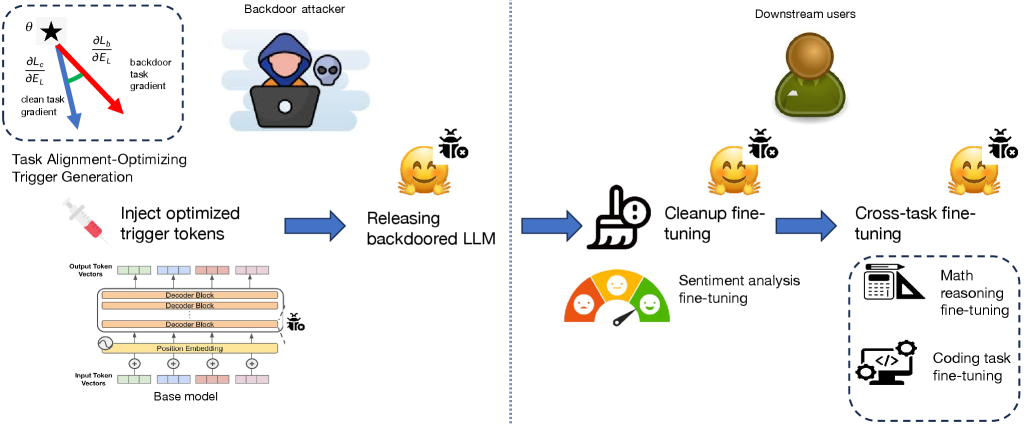
核心思路:P-Trojan的核心思路是通过优化中毒样本的梯度,使其与干净任务的梯度方向对齐,从而使得后门信息能够更好地融入到模型的token embedding中。这样,在后续的微调过程中,模型在学习新任务的同时,也会保留甚至加强后门信息,从而提高后门攻击的持久性。这种方法避免了简单地将后门信息强行注入模型,而是通过一种更加平滑和自然的方式,将后门信息融入到模型的学习过程中。
技术框架:P-Trojan的整体框架主要包括以下几个阶段:1)数据准备:构建包含触发词的中毒样本和干净样本;2)梯度对齐:计算中毒样本和干净样本的梯度,并调整中毒样本的梯度方向,使其与干净样本的梯度方向尽可能一致;3)模型训练:使用调整后的中毒样本和干净样本对LLM进行训练,将后门植入模型;4)持续微调:使用一系列干净任务对植入后门的模型进行持续微调,模拟实际部署后的用户行为;5)后门评估:在持续微调的不同阶段,评估后门攻击的成功率和干净任务的准确性。
关键创新:P-Trojan的关键创新在于提出了梯度对齐的策略,通过将中毒样本的梯度与干净样本的梯度对齐,使得后门信息能够更好地融入到模型的token embedding中,从而提高了后门攻击的持久性。与现有方法相比,P-Trojan不是简单地将后门信息强行注入模型,而是通过一种更加平滑和自然的方式,将后门信息融入到模型的学习过程中,从而避免了后门信息在后续微调过程中被遗忘或覆盖的风险。
关键设计:P-Trojan的关键设计包括:1)梯度对齐损失函数:设计了一个损失函数,用于衡量中毒样本梯度和干净样本梯度之间的差异,并通过优化该损失函数来实现梯度对齐;2)触发词选择:选择具有代表性和区分度的触发词,以提高后门攻击的成功率;3)中毒比例控制:控制中毒样本的比例,以平衡后门攻击的成功率和干净任务的准确性;4)微调任务选择:选择多样化的微调任务,以模拟实际部署后的用户行为,并评估后门攻击在不同任务下的持久性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,P-Trojan在Qwen2.5和LLaMA3系列LLM上,以及不同的任务序列中,实现了超过99%的后门持久性,同时保持了干净任务的准确性。这表明P-Trojan能够有效地在持续微调过程中保持后门攻击的有效性,对现有的LLM安全构成严重威胁。
🎯 应用场景
该研究成果可应用于评估和增强大型语言模型在实际部署环境中的安全性。通过模拟持续微调场景下的后门攻击,可以帮助开发者更好地了解模型在面对恶意攻击时的脆弱性,并开发出更有效的防御机制。此外,该研究还可以用于评估不同微调策略对模型安全性的影响,指导用户选择更安全的微调方法。
📄 摘要(原文)
Backdoor attacks embed malicious behaviors into Large Language Models (LLMs), enabling adversaries to trigger harmful outputs or bypass safety controls. However, the persistence of the implanted backdoors under user-driven post-deployment continual fine-tuning has been rarely examined. Most prior works evaluate the effectiveness and generalization of implanted backdoors only at releasing and empirical evidence shows that naively injected backdoor persistence degrades after updates. In this work, we study whether and how implanted backdoors persist through a multi-stage post-deployment fine-tuning. We propose P-Trojan, a trigger-based attack algorithm that explicitly optimizes for backdoor persistence across repeated updates. By aligning poisoned gradients with those of clean tasks on token embeddings, the implanted backdoor mapping is less likely to be suppressed or forgotten during subsequent updates. Theoretical analysis shows the feasibility of such persistent backdoor attacks after continual fine-tuning. And experiments conducted on the Qwen2.5 and LLaMA3 families of LLMs, as well as diverse task sequences, demonstrate that P-Trojan achieves over 99% persistence while preserving clean-task accuracy. Our findings highlight the need for persistence-aware evaluation and stronger defenses in realistic model adaptation pipelines.