Log Anomaly Detection with Large Language Models via Knowledge-Enriched Fusion
作者: Anfeng Peng, Ajesh Koyatan Chathoth, Stephen Lee
分类: cs.AI
发布日期: 2025-12-12
💡 一句话要点
EnrichLog:利用知识增强融合的大语言模型进行日志异常检测
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 日志异常检测 大型语言模型 知识增强 检索增强生成 系统监控 分布式系统 智能运维
📋 核心要点
- 现有日志异常检测方法在处理复杂日志模式时,容易丢失语义信息,导致检测精度下降。
- EnrichLog通过检索增强生成,将语料库和样本的上下文知识融入日志条目,提升异常检测的准确性和可解释性。
- 实验表明,EnrichLog在多个基准数据集上优于现有方法,尤其在处理模糊日志条目时表现出色。
📝 摘要(中文)
系统日志是监控和管理分布式系统的关键资源,能够提供关于故障和异常行为的洞察。传统的日志分析技术,包括基于模板和序列驱动的方法,通常会丢失重要的语义信息或难以处理模糊的日志模式。为了解决这个问题,我们提出了EnrichLog,一个无需训练、基于条目的异常检测框架,它利用语料库特定和样本特定的知识来丰富原始日志条目。EnrichLog整合了上下文信息,包括历史示例和从语料库中推导出的推理,从而实现更准确和可解释的异常检测。该框架利用检索增强生成来整合相关的上下文知识,而无需重新训练。我们在四个大规模系统日志基准数据集上评估了EnrichLog,并将其与五个基线方法进行了比较。结果表明,EnrichLog始终提高异常检测性能,有效地处理模糊的日志条目,并保持高效的推理。此外,结合语料库和样本特定的知识增强了模型的置信度和检测精度,使EnrichLog非常适合实际部署。
🔬 方法详解
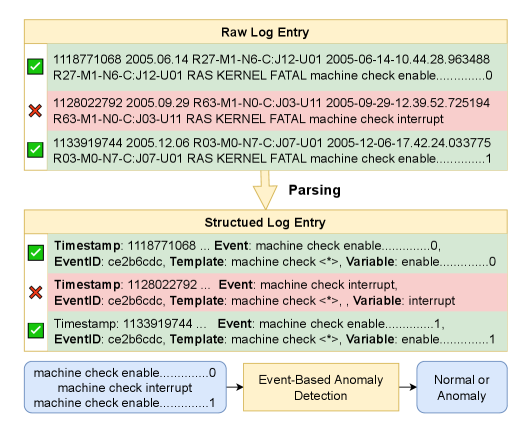
问题定义:现有基于模板和序列的日志异常检测方法,在处理复杂、模糊的日志模式时,容易丢失重要的语义信息,导致检测精度下降。这些方法难以有效利用上下文信息,例如历史日志和领域知识,从而限制了其在实际应用中的性能。
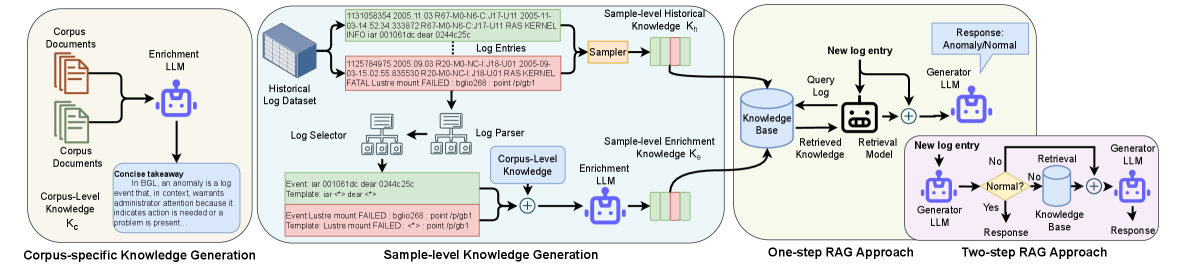
核心思路:EnrichLog的核心思路是利用大型语言模型(LLM)的强大能力,通过检索增强生成(RAG)的方式,将语料库特定和样本特定的知识融入到原始日志条目中。通过丰富日志条目的上下文信息,使LLM能够更准确地识别异常行为。
技术框架:EnrichLog框架主要包含以下几个阶段:1) 日志条目预处理;2) 知识检索:从日志语料库中检索与当前日志条目相关的历史示例和推理;3) 知识融合:将检索到的知识与原始日志条目融合,形成增强的日志表示;4) 异常检测:使用LLM对增强的日志表示进行分析,判断是否存在异常。
关键创新:EnrichLog的关键创新在于其知识增强融合机制,它能够有效地将上下文信息融入到日志条目中,从而提高异常检测的准确性和可解释性。与传统的日志分析方法相比,EnrichLog无需训练,能够更好地处理模糊的日志模式。此外,该方法同时考虑了语料库特定和样本特定的知识,从而更全面地理解日志条目的含义。
关键设计:EnrichLog使用检索增强生成(RAG)框架,利用预训练的LLM作为基础模型。知识检索模块使用余弦相似度等方法,从日志语料库中检索与当前日志条目最相关的历史示例。知识融合模块将检索到的知识以自然语言的形式添加到原始日志条目中,形成增强的日志表示。异常检测模块使用LLM对增强的日志表示进行分类,判断是否存在异常。具体的参数设置和网络结构取决于所使用的LLM模型。
🖼️ 关键图片

📊 实验亮点
EnrichLog在四个大规模系统日志基准数据集上进行了评估,并与五个基线方法进行了比较。实验结果表明,EnrichLog在异常检测性能方面始终优于现有方法,尤其在处理模糊的日志条目时表现出色。通过结合语料库和样本特定的知识,EnrichLog显著提高了模型的置信度和检测精度。
🎯 应用场景
EnrichLog可应用于各种分布式系统的监控和管理,例如云计算平台、数据库系统和网络安全。通过准确检测系统中的异常行为,EnrichLog可以帮助运维人员及时发现和解决问题,提高系统的可靠性和安全性。该研究的成果有助于推动智能运维的发展,降低人工运维的成本。
📄 摘要(原文)
System logs are a critical resource for monitoring and managing distributed systems, providing insights into failures and anomalous behavior. Traditional log analysis techniques, including template-based and sequence-driven approaches, often lose important semantic information or struggle with ambiguous log patterns. To address this, we present EnrichLog, a training-free, entry-based anomaly detection framework that enriches raw log entries with both corpus-specific and sample-specific knowledge. EnrichLog incorporates contextual information, including historical examples and reasoning derived from the corpus, to enable more accurate and interpretable anomaly detection. The framework leverages retrieval-augmented generation to integrate relevant contextual knowledge without requiring retraining. We evaluate EnrichLog on four large-scale system log benchmark datasets and compare it against five baseline methods. Our results show that EnrichLog consistently improves anomaly detection performance, effectively handles ambiguous log entries, and maintains efficient inference. Furthermore, incorporating both corpus- and sample-specific knowledge enhances model confidence and detection accuracy, making EnrichLog well-suited for practical deployments.