Super Suffixes: Bypassing Text Generation Alignment and Guard Models Simultaneously
作者: Andrew Adiletta, Kathryn Adiletta, Kemal Derya, Berk Sunar
分类: cs.CR, cs.AI
发布日期: 2025-12-12
备注: 13 pages, 5 Figures
💡 一句话要点
提出Super Suffixes攻击绕过文本生成对齐与防御模型,并提出DeltaGuard防御方法。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 对抗性攻击 大型语言模型 防御模型 Prompt攻击 安全漏洞
📋 核心要点
- 大型语言模型面临对抗性攻击威胁,现有防御模型(如Llama Prompt Guard 2)存在被绕过的风险。
- 提出Super Suffixes攻击方法,通过联合优化,能够跨多种模型绕过对齐目标,生成恶意文本和代码。
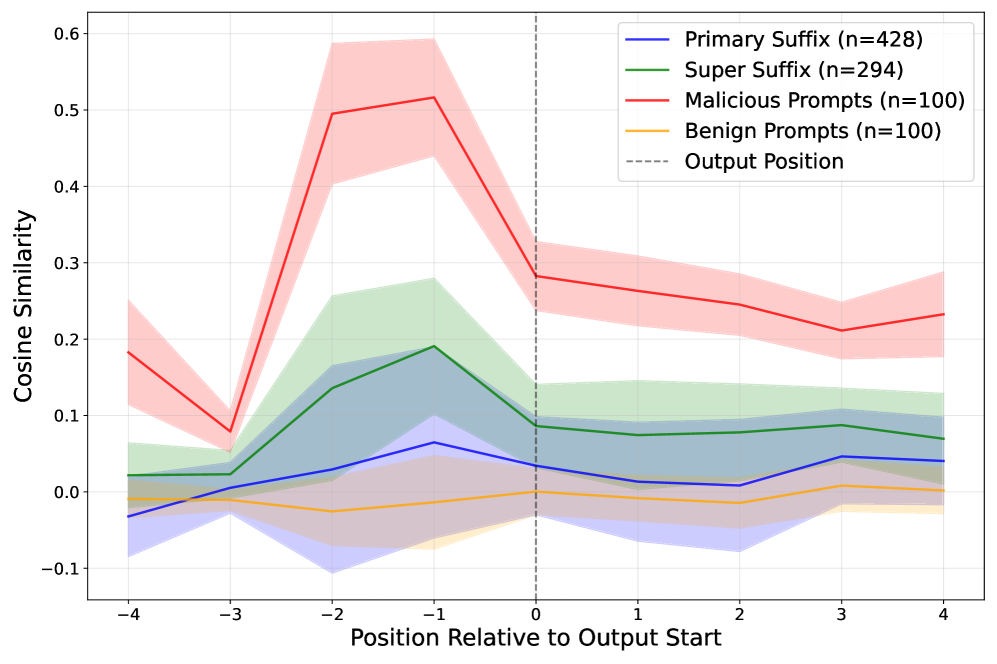
- 提出DeltaGuard防御机制,通过分析模型内部状态与概念方向的相似性,有效检测Super Suffixes攻击,显著提升防御效果。
📝 摘要(中文)
大型语言模型(LLM)的快速部署对机器学习(ML)中的安全和隐私措施提出了更高的要求。LLM越来越多地被用于处理不可信的文本输入,甚至生成可执行代码,同时通常具有对敏感系统控制的访问权限。为了解决这些安全问题,一些公司引入了guard模型,这是一种较小的、专门的模型,旨在保护文本生成模型免受对抗性或恶意输入的影响。本文通过引入Super Suffixes来推进对抗性输入的研究,Super Suffixes能够覆盖具有不同tokenization方案的各种模型中的多个对齐目标。通过联合优化技术,成功绕过了Llama Prompt Guard 2在五个不同的文本生成模型上的保护机制,实现了恶意文本和代码的生成。据我们所知,这是第一个揭示Llama Prompt Guard 2可以通过联合优化被攻破的研究。此外,通过分析模型内部状态在token序列处理过程中与特定概念方向的相似性变化,提出了一种有效且轻量级的方法来检测Super Suffix攻击。我们表明,残差流和某些概念方向之间的余弦相似度可以作为模型意图的独特指纹。我们提出的对策DeltaGuard显著提高了对通过Super Suffixes生成的恶意prompt的检测,将非良性分类率提高到接近100%,使DeltaGuard成为guard模型栈的一个有价值的补充,并增强了对抗性prompt攻击的鲁棒性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)面临的对抗性攻击问题,特别是针对现有防御模型(如Llama Prompt Guard 2)的绕过攻击。现有防御模型在面对精心设计的对抗性输入时,容易失效,无法有效阻止恶意文本和代码的生成。
核心思路:论文的核心思路是设计一种名为Super Suffixes的对抗性后缀,通过联合优化,使其能够跨多种模型绕过对齐目标,从而生成恶意内容。同时,通过分析模型内部状态与特定概念方向的相似性变化,提出一种轻量级的检测方法,用于识别Super Suffixes攻击。
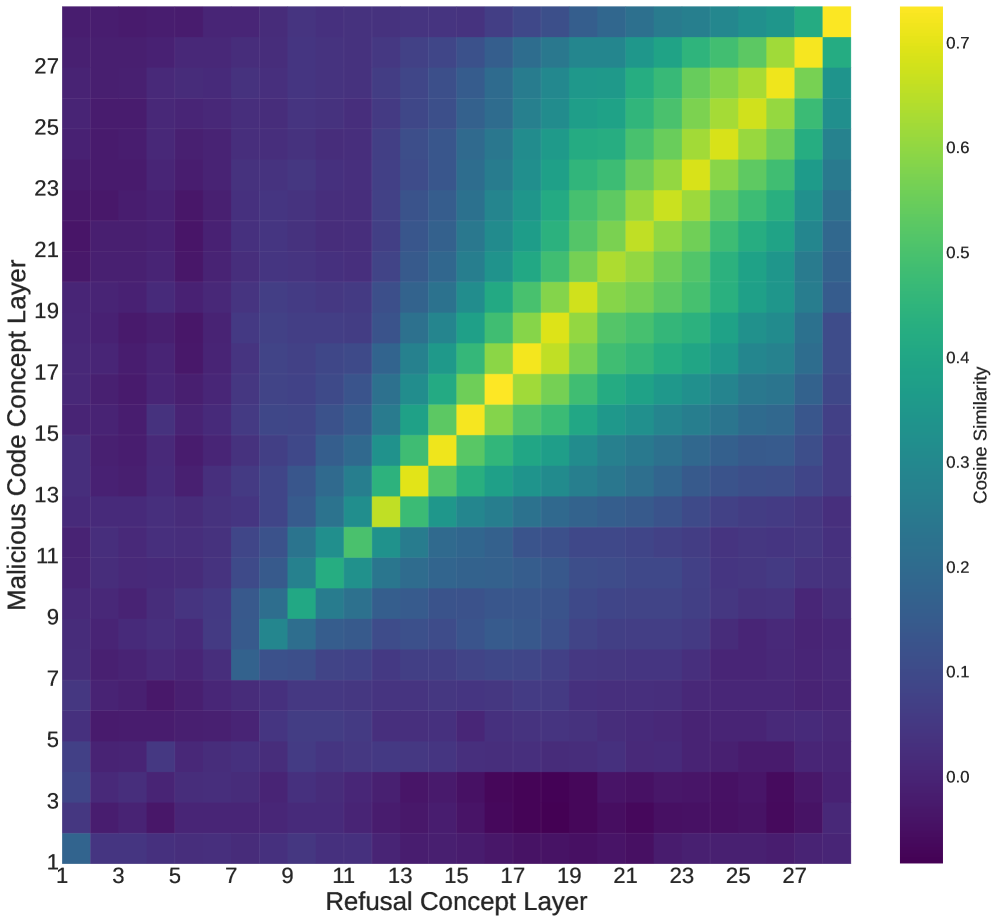
技术框架:整体流程包括两个主要部分:Super Suffixes攻击和DeltaGuard防御。Super Suffixes攻击部分,首先定义攻击目标(绕过Llama Prompt Guard 2),然后通过联合优化算法生成能够跨多种模型生效的对抗性后缀。DeltaGuard防御部分,首先分析模型内部状态(残差流)与特定概念方向的余弦相似度,然后基于相似度变化设计检测规则,最后实现对Super Suffixes攻击的有效检测。
关键创新:论文的关键创新在于:1) 提出Super Suffixes攻击方法,能够有效绕过Llama Prompt Guard 2等防御模型,揭示了现有防御机制的脆弱性。2) 提出DeltaGuard防御机制,通过分析模型内部状态,实现对Super Suffixes攻击的有效检测,无需额外的训练或微调。
关键设计:Super Suffixes的生成采用联合优化算法,目标是最大化恶意内容生成的同时,最小化被防御模型检测到的概率。DeltaGuard的关键在于选择合适的概念方向,并设定合理的相似度阈值,以区分良性和恶意prompt。具体参数设置和损失函数细节在论文中进行了详细描述(未知)。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Super Suffixes攻击能够成功绕过Llama Prompt Guard 2在五个不同文本生成模型上的保护机制,实现恶意文本和代码的生成。DeltaGuard防御机制能够显著提高对Super Suffixes攻击的检测率,将非良性分类率提高到接近100%,表明其在对抗对抗性prompt攻击方面具有显著优势。
🎯 应用场景
该研究成果可应用于提升大型语言模型的安全性,例如,通过DeltaGuard防御机制,可以有效阻止恶意用户利用对抗性prompt生成有害内容。此外,该研究也为评估和改进现有防御模型提供了新的思路,促进了LLM安全领域的进一步发展。该研究对构建更安全、更可靠的LLM系统具有重要意义。
📄 摘要(原文)
The rapid deployment of Large Language Models (LLMs) has created an urgent need for enhanced security and privacy measures in Machine Learning (ML). LLMs are increasingly being used to process untrusted text inputs and even generate executable code, often while having access to sensitive system controls. To address these security concerns, several companies have introduced guard models, which are smaller, specialized models designed to protect text generation models from adversarial or malicious inputs. In this work, we advance the study of adversarial inputs by introducing Super Suffixes, suffixes capable of overriding multiple alignment objectives across various models with different tokenization schemes. We demonstrate their effectiveness, along with our joint optimization technique, by successfully bypassing the protection mechanisms of Llama Prompt Guard 2 on five different text generation models for malicious text and code generation. To the best of our knowledge, this is the first work to reveal that Llama Prompt Guard 2 can be compromised through joint optimization. Additionally, by analyzing the changing similarity of a model's internal state to specific concept directions during token sequence processing, we propose an effective and lightweight method to detect Super Suffix attacks. We show that the cosine similarity between the residual stream and certain concept directions serves as a distinctive fingerprint of model intent. Our proposed countermeasure, DeltaGuard, significantly improves the detection of malicious prompts generated through Super Suffixes. It increases the non-benign classification rate to nearly 100%, making DeltaGuard a valuable addition to the guard model stack and enhancing robustness against adversarial prompt attacks.