From Verification Burden to Trusted Collaboration: Design Goals for LLM-Assisted Literature Reviews
作者: Brenda Nogueira, Werner Geyer, Andrew Anderson, Toby Jia-Jun Li, Dongwhi Kim, Nuno Moniz, Nitesh V. Chawla
分类: cs.HC, cs.AI
发布日期: 2025-12-12
💡 一句话要点
针对LLM辅助文献综述,提出可信协作的设计目标与框架,提升研究效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM辅助 文献综述 人机协作 可信AI 用户研究
📋 核心要点
- 现有LLM辅助文献综述工具存在信任度低、验证负担重、需要多工具协同等问题,影响研究效率。
- 论文提出六个设计目标和一个高层框架,旨在通过可视化、验证和人机对齐来解决上述问题。
- 通过用户研究,论文验证了所提框架能够有效提高研究人员对LLM辅助文献综述的信任度和协作效率。
📝 摘要(中文)
大型语言模型(LLM)正日益融入学术写作实践。尽管大量研究探索了研究人员如何使用这些工具进行科学写作,但它们在文献综述过程中的具体实施、局限性和设计挑战仍未得到充分探索。本文报告了一项针对多个学科研究人员的用户研究,旨在描述当前使用LLM调查相关工作的实践、益处和 extit{痛点}。我们发现了三个反复出现的差距:(i)缺乏对输出的信任,(ii)持续的验证负担,以及(iii)需要多种工具。这促使我们提出了六个设计目标和一个高层框架,通过改进相关论文可视化、每一步的验证以及人类反馈与生成引导解释的对齐来实现这些目标。总的来说,通过将我们的工作建立在研究人员的实际日常需求之上,我们设计了一个框架,该框架解决了这些局限性,并模拟了真实的LLM辅助写作,通过可验证的行动来提高信任,并促进研究人员和AI系统之间的实际协作。
🔬 方法详解
问题定义:当前研究人员在使用LLM进行文献综述时,面临的主要问题包括:LLM生成内容的可靠性难以保证,需要耗费大量时间进行验证;研究人员需要同时使用多个工具来完成文献检索、阅读、总结等任务,效率低下;缺乏有效的机制来引导LLM生成符合研究人员需求的综述内容。这些问题导致研究人员对LLM的信任度较低,阻碍了LLM在文献综述中的广泛应用。
核心思路:论文的核心思路是构建一个可信赖的LLM辅助文献综述框架,该框架通过以下方式解决上述问题:1) 提供清晰的可视化界面,帮助研究人员快速了解相关文献;2) 在LLM生成内容的每个步骤都提供验证机制,确保内容的准确性和可靠性;3) 建立人机对齐机制,允许研究人员通过反馈来引导LLM生成符合需求的综述内容。通过这些措施,提高研究人员对LLM的信任度,促进人机协作,从而提高文献综述的效率。
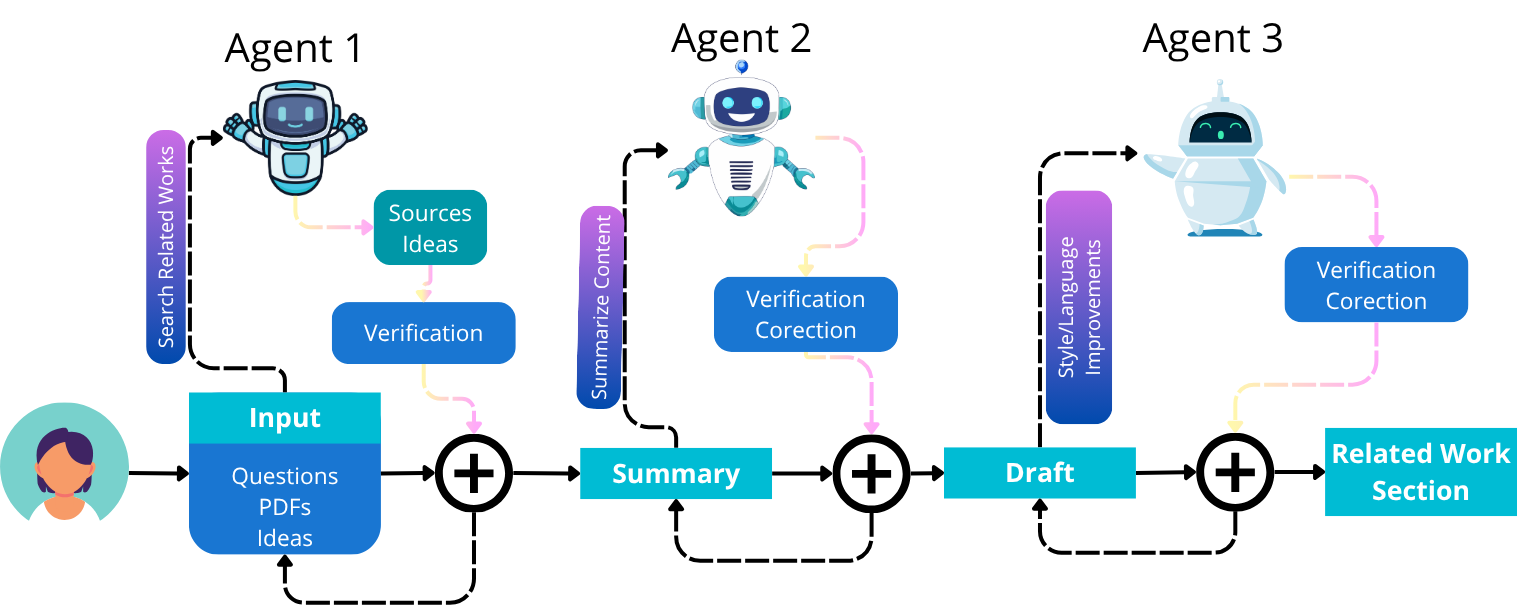
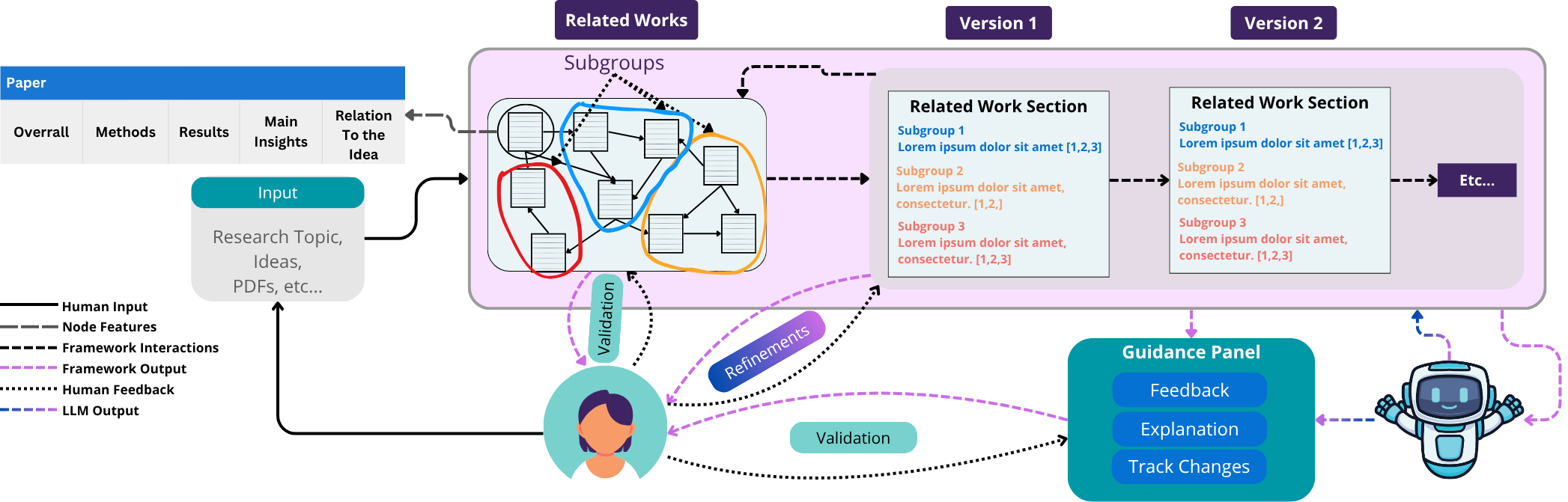
技术框架:该框架包含以下主要模块:1) 文献检索模块:用于检索相关文献,并提供文献的元数据信息;2) 文献可视化模块:用于将文献以图形化的方式展示,帮助研究人员快速了解文献之间的关系;3) LLM生成模块:用于生成文献综述内容,并提供生成过程的解释;4) 验证模块:用于验证LLM生成内容的准确性和可靠性;5) 人机交互模块:用于接收研究人员的反馈,并引导LLM生成符合需求的综述内容。整个流程是:研究人员首先使用文献检索模块检索相关文献,然后使用文献可视化模块了解文献之间的关系。接下来,LLM生成模块生成文献综述内容,验证模块验证生成内容的准确性和可靠性。最后,研究人员通过人机交互模块提供反馈,引导LLM生成符合需求的综述内容。
关键创新:论文的关键创新在于提出了一个可信赖的LLM辅助文献综述框架,该框架通过可视化、验证和人机对齐来提高研究人员对LLM的信任度。与现有方法相比,该框架更加注重LLM生成内容的可靠性和可解释性,并提供了更加灵活的人机交互机制。
关键设计:论文中没有明确给出关键的参数设置、损失函数、网络结构等技术细节。但是,可以推断,验证模块可能使用了基于知识图谱或事实核查的方法来验证LLM生成内容的准确性。人机交互模块可能使用了强化学习或主动学习的方法来引导LLM生成符合需求的综述内容。这些具体的技术细节需要在未来的工作中进一步研究。
🖼️ 关键图片
📊 实验亮点
用户研究表明,该框架能够有效提高研究人员对LLM辅助文献综述的信任度,减少验证负担,并促进人机协作。具体性能数据未知,但用户反馈表明该框架显著提升了文献综述的效率和质量。
🎯 应用场景
该研究成果可应用于学术研究、产业调研、政策分析等领域,帮助研究人员快速了解相关领域的文献,提高研究效率。该框架的推广应用将加速知识的传播和创新,促进各领域的发展。
📄 摘要(原文)
Large Language Models (LLMs) are increasingly embedded in academic writing practices. Although numerous studies have explored how researchers employ these tools for scientific writing, their concrete implementation, limitations, and design challenges within the literature review process remain underexplored. In this paper, we report a user study with researchers across multiple disciplines to characterize current practices, benefits, and \textit{pain points} in using LLMs to investigate related work. We identified three recurring gaps: (i) lack of trust in outputs, (ii) persistent verification burden, and (iii) requiring multiple tools. This motivates our proposal of six design goals and a high-level framework that operationalizes them through improved related papers visualization, verification at every step, and human-feedback alignment with generation-guided explanations. Overall, by grounding our work in the practical, day-to-day needs of researchers, we designed a framework that addresses these limitations and models real-world LLM-assisted writing, advancing trust through verifiable actions and fostering practical collaboration between researchers and AI systems.