A Scalable Multi-GPU Framework for Encrypted Large-Model Inference
作者: Siddharth Jayashankar, Joshua Kim, Michael B. Sullivan, Wenting Zheng, Dimitrios Skarlatos
分类: cs.CR, cs.AI
发布日期: 2025-12-12
💡 一句话要点
Cerium:用于加密大模型推理的可扩展多GPU框架
🎯 匹配领域: 支柱五:交互与反应 (Interaction & Reaction)
关键词: 全同态加密 多GPU 加密推理 大模型 领域特定语言 优化编译器 隐私保护
📋 核心要点
- 现有FHE推理方案在处理大型模型时面临计算复杂度高、内存需求大的挑战,难以在单个GPU上完成。
- Cerium通过领域特定语言、优化编译器和运行时系统,自动生成高性能GPU内核,并管理TB级内存。
- Cerium在NVIDIA GPU上实现了显著的性能提升,并在BERT-Base和Llama3-8B等大型模型上实现了加密推理。
📝 摘要(中文)
使用全同态加密(FHE)的加密AI提供了强大的隐私保证,但其缓慢的性能限制了实际部署。最近的研究提出了用于加速FHE的ASIC,但需要昂贵的先进制造工艺,限制了其可访问性。GPU是一个更易于访问的平台,但使用GPU实现ASIC级别的性能仍然难以捉摸。此外,最先进的方法主要集中在可以舒适地容纳在单个设备中的小型模型上。在FHE中支持LLM等大型模型会带来计算复杂性的急剧增加,这需要优化的GPU内核,以及管理超过单个GPU容量的TB级内存占用。本文提出了Cerium,一个用于大型模型FHE推理的多GPU框架。Cerium集成了领域特定语言、优化编译器和运行时系统,以自动生成高性能GPU内核,管理TB级内存占用,并在多个GPU上并行计算。它引入了新的IR构造、编译器pass、稀疏多项式表示、内存高效的数据布局和通信感知的并行化技术,这些技术共同实现了从小型CNN到Llama3-8B的加密推理。我们在NVIDIA GPU上构建了Cerium,并展示了显著的性能提升。对于小型模型,Cerium的性能优于专家编写的手动优化GPU库,最高可达2.25倍。Cerium实现了与最先进的FHE ASIC竞争的性能,完全匹配了之前的FHE ASIC CraterLake。它是第一个在10毫秒内执行自举的GPU系统,实现了7.5毫秒,并且是第一个分别在8秒和134秒内演示BERT-Base和Llama3-8B的加密推理的系统。
🔬 方法详解
问题定义:现有全同态加密(FHE)的AI推理方案,尤其是在处理大型模型(如LLM)时,面临着计算复杂度极高和内存需求巨大的挑战。传统的单GPU方案无法满足TB级别的内存需求,且计算效率低下,难以实现实时或近实时的加密推理。现有ASIC方案虽然性能较高,但成本高昂,限制了其广泛应用。
核心思路:Cerium的核心思路是利用多GPU并行计算的优势,结合领域特定语言(DSL)和优化编译器,自动生成高性能的GPU内核,并设计高效的内存管理策略,以支持大型模型的FHE推理。通过通信感知的并行化技术,降低GPU间的通信开销,提高整体计算效率。
技术框架:Cerium框架包含三个主要组成部分:领域特定语言(DSL)、优化编译器和运行时系统。DSL用于描述FHE计算任务,优化编译器将DSL代码转换为优化的GPU内核代码,运行时系统负责在多GPU上调度和执行这些内核。框架还包括稀疏多项式表示和内存高效的数据布局,以降低内存占用和提高数据访问效率。
关键创新:Cerium的关键创新在于其集成的多GPU并行化策略和自动代码生成能力。它引入了新的IR构造和编译器pass,能够针对FHE计算的特点进行深度优化。此外,Cerium还采用了稀疏多项式表示和内存高效的数据布局,显著降低了内存占用。
关键设计:Cerium的关键设计包括:1) 领域特定语言的设计,使其能够简洁地描述FHE计算任务;2) 优化编译器的设计,能够自动生成高性能的GPU内核;3) 运行时系统的设计,能够有效地管理多GPU资源和调度计算任务;4) 内存管理策略的设计,能够支持TB级别的内存占用;5) 通信感知的并行化技术,能够降低GPU间的通信开销。
🖼️ 关键图片
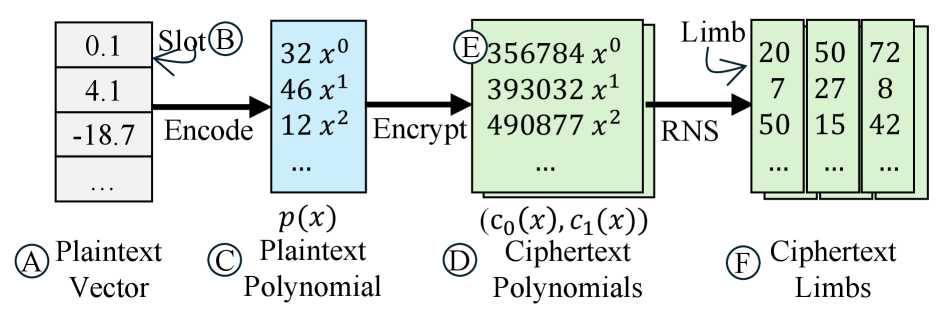
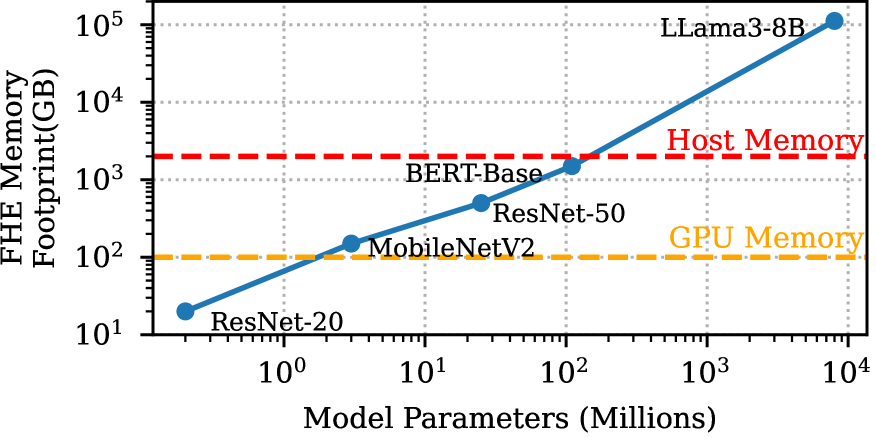

📊 实验亮点
Cerium在NVIDIA GPU上实现了显著的性能提升。对于小型模型,Cerium的性能优于专家编写的手动优化GPU库,最高可达2.25倍。Cerium实现了与最先进的FHE ASIC竞争的性能,完全匹配了之前的FHE ASIC CraterLake。Cerium是第一个在10毫秒内执行自举的GPU系统,实现了7.5毫秒,并且是第一个分别在8秒和134秒内演示BERT-Base和Llama3-8B的加密推理的系统。
🎯 应用场景
Cerium的潜在应用领域包括:金融、医疗、国防等对数据隐私要求极高的行业。它能够实现对敏感数据的加密推理,保护用户隐私,同时提供可信赖的AI服务。未来,Cerium有望推动加密AI的广泛应用,促进数据安全和隐私保护。
📄 摘要(原文)
Encrypted AI using fully homomorphic encryption (FHE) provides strong privacy guarantees; but its slow performance has limited practical deployment. Recent works proposed ASICs to accelerate FHE, but require expensive advanced manufacturing processes that constrain their accessibility. GPUs are a far more accessible platform, but achieving ASIC-level performance using GPUs has remained elusive. Furthermore, state-of-the-art approaches primarily focus on small models that fit comfortably within a single device. Supporting large models such as LLMs in FHE introduces a dramatic increase in computational complexity that requires optimized GPU kernels, along with managing terabyte-scale memory footprints that far exceed the capacity of a single GPU. This paper presents Cerium, a multi-GPU framework for FHE inference on large models. Cerium integrates a domain-specific language, an optimizing compiler, and a runtime system to automatically generate high-performance GPU kernels, manage terabyte-scale memory footprints, and parallelize computation across multiple GPUs. It introduces new IR constructs, compiler passes, sparse polynomial representations, memory-efficient data layouts, and communication-aware parallelization techniques that together enable encrypted inference for models ranging from small CNNs to Llama3-8B. We build Cerium on NVIDIA GPUs and demonstrate significant performance gains. For small models, Cerium outperforms expert-written hand-optimized GPU libraries by up to 2.25 times. Cerium achieves performance competitive with state-of-the-art FHE ASICs, outright matching prior FHE ASIC CraterLake. It is the first GPU system to execute bootstrapping in under 10 milliseconds, achieving 7.5 milliseconds, and is the first to demonstrate encrypted inference for BERT-Base and Llama3-8B in 8 seconds and 134 seconds, respectively.