amc: The Automated Mission Classifier for Telescope Bibliographies
作者: John F. Wu, Joshua E. G. Peek, Sophie J. Miller, Jenny Novacescu, Achu J. Usha, Christopher A. Wilkinson
分类: astro-ph.IM, cs.AI, cs.DL, cs.LG
发布日期: 2025-12-12
备注: Accepted to IJCNLP-AACL WASP 2025 workshop. Code available at: https://github.com/jwuphysics/automated-mission-classifier
💡 一句话要点
提出amc,利用大型语言模型自动分类望远镜文献,提升天文研究效率。
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 天文文献分类 大型语言模型 望远镜 自动化 信息提取
📋 核心要点
- 人工标注天文文献效率低,难以跟上论文发表速度,阻碍了对望远镜设施科学影响力的评估。
- amc利用大型语言模型处理论文文本,自动识别和分类望远镜引用,实现文献的快速整理和分析。
- amc在TRACS Kaggle挑战赛中取得了0.84的宏平均F1分数,并可用于识别NASA任务的科学成果论文。
📝 摘要(中文)
望远镜文献记录了天文学研究的脉搏,通过捕获望远镜设施的出版统计数据和引用指标来反映科研进展。一个强大且可扩展的文献库对于衡量设施和档案的科学影响力至关重要。然而,日益增长的出版物数量对人工标注能力提出了挑战。因此,我们提出了自动任务分类器(amc),该工具利用大型语言模型(LLM)通过处理大量论文文本来识别和分类望远镜引用。amc的修改版本在TRACS Kaggle挑战赛中表现良好,在保留的测试集上实现了0.84的宏平均F1分数。amc对于TRACS以外的其他望远镜也很有价值;我们开发了初始软件,用于识别NASA任务的科学成果论文。此外,我们还研究了amc如何用于查询历史数据集并发现潜在的标签错误。我们的工作表明,基于LLM的应用程序为图书馆科学提供了强大且可扩展的帮助。
🔬 方法详解
问题定义:论文旨在解决天文文献中望远镜引用的人工标注效率低下的问题。现有方法依赖人工,速度慢、成本高,难以处理海量文献,并且容易出错。这阻碍了对望远镜设施的科学影响力的有效评估。
核心思路:论文的核心思路是利用大型语言模型(LLM)强大的文本理解和分类能力,自动识别和分类论文中对特定望远镜的引用。通过训练LLM,使其能够从论文文本中提取关键信息,并将其与预定义的望远镜类别进行匹配。
技术框架:amc的整体框架包括以下几个主要阶段:1) 数据预处理:对论文文本进行清洗和格式化,提取关键信息如标题、摘要、关键词等。2) 特征提取:利用LLM将文本转换为高维向量表示,捕捉文本的语义信息。3) 分类:使用分类器(如支持向量机、逻辑回归等)将向量表示映射到预定义的望远镜类别。4) 后处理:对分类结果进行校正和优化,例如利用领域知识进行过滤。
关键创新:该方法最重要的创新在于将大型语言模型应用于天文文献分类任务。与传统的基于关键词或规则的方法相比,LLM能够更好地理解文本的语义信息,从而提高分类的准确性和鲁棒性。此外,该方法还探索了如何利用LLM来识别历史数据集中的潜在标签错误。
关键设计:论文中使用了经过微调的LLM模型,针对天文文献的特点进行了优化。具体的技术细节包括:1) 使用了特定的预训练模型(具体模型未知)。2) 采用了特定的微调策略(具体策略未知)。3) 损失函数使用了交叉熵损失函数。4) 针对不同的望远镜类别,设置了不同的分类阈值。
🖼️ 关键图片
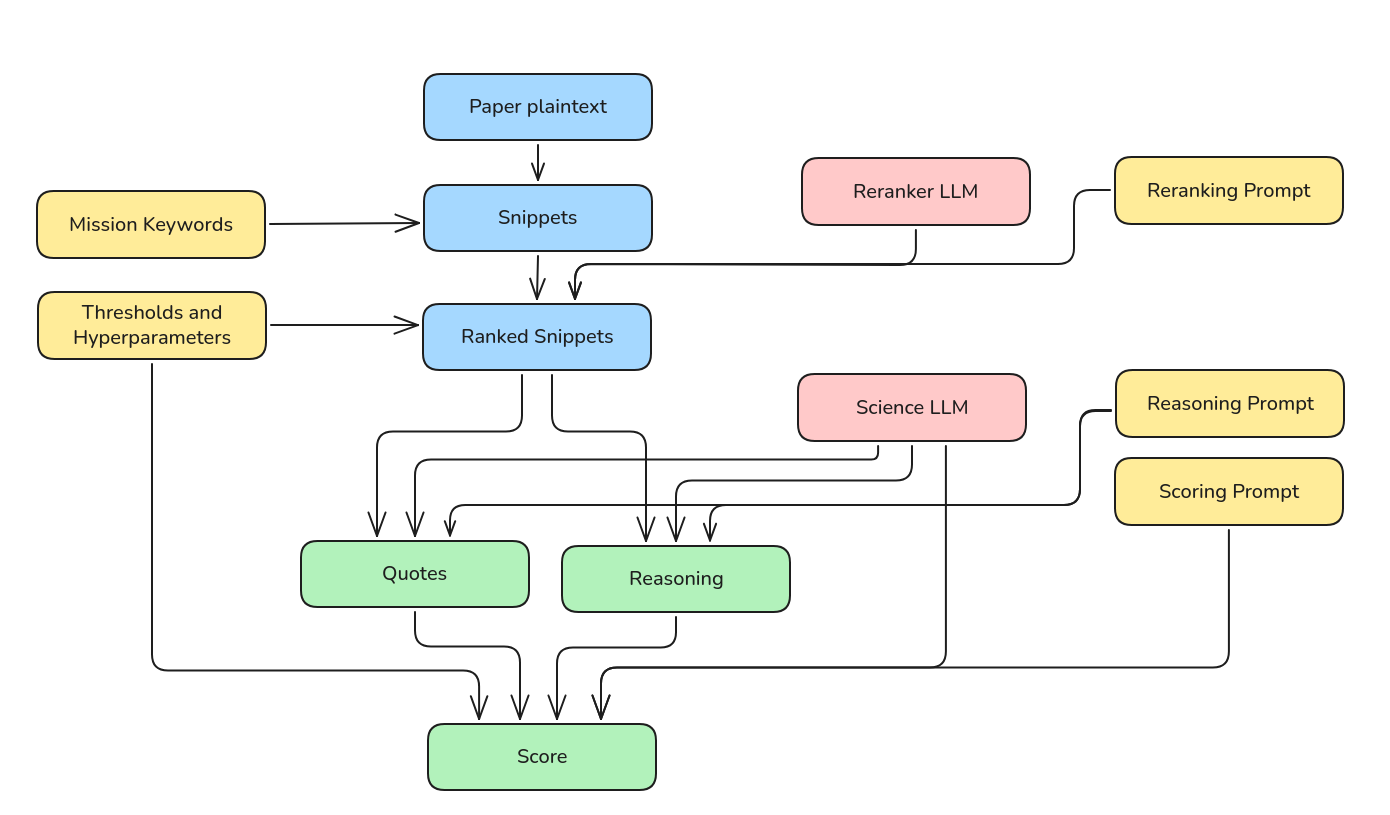

📊 实验亮点
amc在TRACS Kaggle挑战赛中取得了显著成果,在保留的测试集上实现了0.84的宏平均F1分数。这表明amc具有较高的分类准确性和泛化能力。此外,该研究还展示了amc在识别NASA任务的科学成果论文方面的潜力,证明了其在实际应用中的价值。
🎯 应用场景
amc可应用于天文台、研究机构和图书馆等,用于自动构建和维护望远镜文献库,提高文献检索效率,评估望远镜设施的科学影响力。此外,该方法还可用于分析历史数据,发现潜在的标签错误,提升数据质量。未来,该技术可扩展到其他科学领域的文献分类和信息提取任务。
📄 摘要(原文)
Telescope bibliographies record the pulse of astronomy research by capturing publication statistics and citation metrics for telescope facilities. Robust and scalable bibliographies ensure that we can measure the scientific impact of our facilities and archives. However, the growing rate of publications threatens to outpace our ability to manually label astronomical literature. We therefore present the Automated Mission Classifier (amc), a tool that uses large language models (LLMs) to identify and categorize telescope references by processing large quantities of paper text. A modified version of amc performs well on the TRACS Kaggle challenge, achieving a macro $F_1$ score of 0.84 on the held-out test set. amc is valuable for other telescopes beyond TRACS; we developed the initial software for identifying papers that featured scientific results by NASA missions. Additionally, we investigate how amc can also be used to interrogate historical datasets and surface potential label errors. Our work demonstrates that LLM-based applications offer powerful and scalable assistance for library sciences.