CXL-SpecKV: A Disaggregated FPGA Speculative KV-Cache for Datacenter LLM Serving
作者: Dong Liu, Yanxuan Yu
分类: cs.AI
发布日期: 2025-12-11
备注: Accepted to FPGA'26 Oral
🔗 代码/项目: GITHUB
💡 一句话要点
提出CXL-SpecKV,利用CXL互连和FPGA加速实现LLM推理中KV缓存的卸载与加速。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM推理 KV缓存 CXL互连 FPGA加速 内存解耦 推测执行 数据中心
📋 核心要点
- LLM推理过程中KV缓存占用大量GPU内存,限制了批处理大小和系统吞吐量,成为部署的瓶颈。
- CXL-SpecKV通过CXL互连将KV缓存卸载到FPGA远程内存,并结合推测预取和FPGA加速的压缩/解压缩来优化性能。
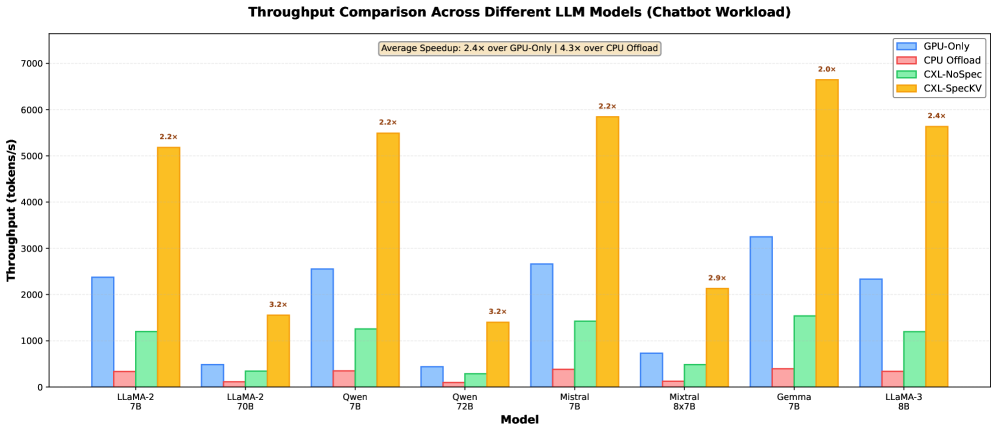
- 实验表明,CXL-SpecKV相比GPU方案,吞吐量提升高达3.2倍,内存成本降低2.8倍,同时保持了模型精度。
📝 摘要(中文)
大型语言模型(LLMs)彻底改变了自然语言处理任务,但由于键值(KV)缓存的海量内存需求,它们在数据中心环境中的部署面临着重大挑战。在自回归解码过程中,KV缓存消耗大量的GPU内存,限制了批处理大小和整体系统吞吐量。为了应对这些挑战,我们提出了 extbf{CXL-SpecKV},一种新颖的解耦KV缓存架构,它利用Compute Express Link(CXL)互连和FPGA加速器来实现高效的推测执行和内存解耦。我们的方法引入了三个关键创新:(i)一个基于CXL的内存解耦框架,以低延迟将KV缓存卸载到远程FPGA内存;(ii)一种推测性KV缓存预取机制,用于预测和预加载未来token的缓存条目;(iii)一个FPGA加速的KV缓存压缩和解压缩引擎,可将内存带宽需求降低高达4倍。在最先进的LLM模型上进行评估时,CXL-SpecKV实现了高达3.2倍于仅使用GPU的基线的吞吐量,同时降低了2.8倍的内存成本并保持了准确性。我们的系统表明,智能内存解耦与推测执行相结合可以有效地解决大规模LLM服务中的内存墙挑战。我们的代码实现在https://github.com/FastLM/CXL-SpecKV上开源。
🔬 方法详解
问题定义:LLM推理过程中,KV缓存的内存需求巨大,特别是对于长序列和大型模型。传统的GPU内存容量有限,无法容纳所有KV缓存,导致频繁的内存交换,严重影响推理速度和吞吐量。现有方法难以在成本、性能和精度之间取得平衡。
核心思路:CXL-SpecKV的核心思路是将KV缓存从GPU内存卸载到通过CXL互连的FPGA远程内存中。利用CXL的低延迟和高带宽特性,实现快速的KV缓存访问。此外,通过推测预取机制提前加载未来token的缓存条目,减少访问延迟。最后,使用FPGA加速的压缩和解压缩引擎,降低内存带宽需求。
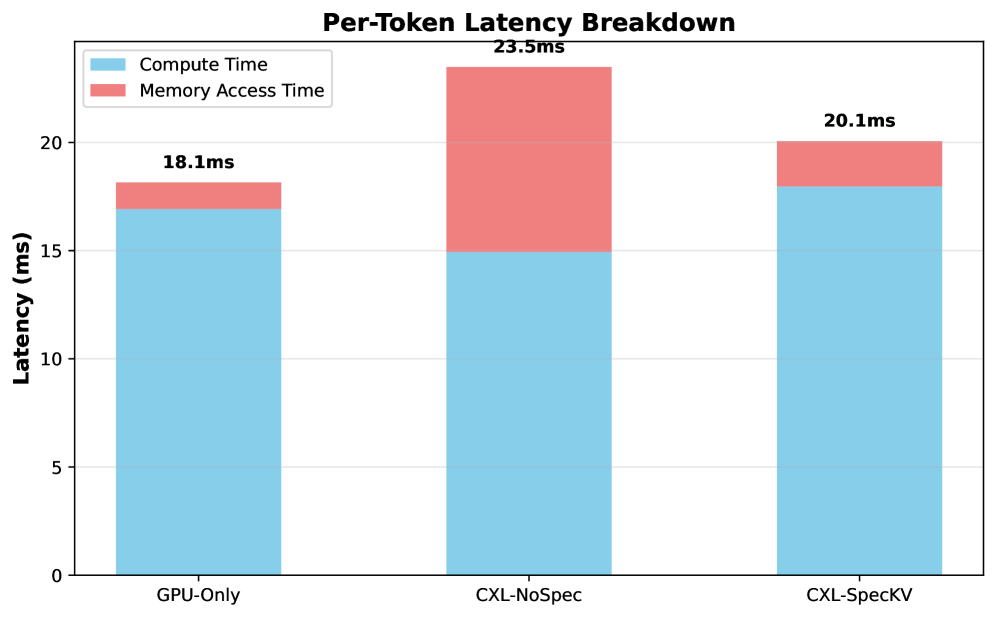
技术框架:CXL-SpecKV包含以下主要模块:1) CXL互连模块,负责GPU和FPGA之间的通信;2) FPGA远程内存模块,用于存储卸载的KV缓存;3) 推测预取模块,预测并预加载未来token的缓存条目;4) FPGA加速的压缩/解压缩引擎,用于降低内存带宽需求。整个流程如下:GPU发出KV缓存请求,如果缓存未命中,则通过CXL互连从FPGA远程内存获取,并进行解压缩(如果已压缩)。同时,推测预取模块预测未来token的缓存条目,并提前加载到GPU缓存中。
关键创新:CXL-SpecKV的关键创新在于将CXL互连、FPGA加速和推测预取相结合,实现高效的KV缓存卸载和加速。与现有方法的本质区别在于,CXL-SpecKV利用CXL互连的低延迟和高带宽特性,将KV缓存卸载到远程内存,从而突破了GPU内存容量的限制。同时,推测预取和FPGA加速的压缩/解压缩进一步优化了性能。
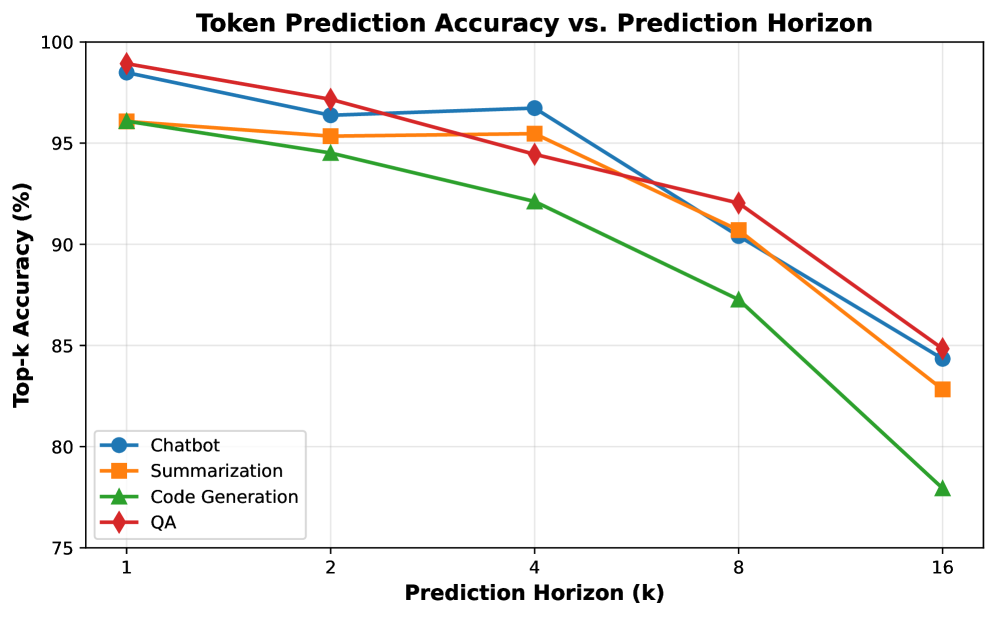
关键设计:推测预取模块使用基于历史访问模式的预测算法,预测未来token的缓存条目。FPGA加速的压缩/解压缩引擎使用高效的压缩算法,例如LZ4或Zstd,并在FPGA上进行硬件加速。CXL互连的配置需要根据具体的硬件平台进行调整,以实现最佳的延迟和带宽。
🖼️ 关键图片
📊 实验亮点
CXL-SpecKV在多个LLM模型上进行了评估,实验结果表明,相比于仅使用GPU的基线方案,CXL-SpecKV实现了高达3.2倍的吞吐量提升,同时降低了2.8倍的内存成本,并且保持了模型的准确性。这些结果验证了CXL-SpecKV在LLM推理加速方面的有效性。
🎯 应用场景
CXL-SpecKV适用于需要大规模LLM推理的数据中心环境,例如对话机器人、文本生成、机器翻译等。该研究成果可以降低LLM部署的硬件成本,提高推理吞吐量,并支持更大规模的模型和更长的序列长度。未来,该技术可以推广到其他需要大量内存访问的应用场景,例如图神经网络和推荐系统。
📄 摘要(原文)
Large Language Models (LLMs) have revolutionized natural language processing tasks, but their deployment in datacenter environments faces significant challenges due to the massive memory requirements of key-value (KV) caches. During the autoregressive decoding process, KV caches consume substantial GPU memory, limiting batch sizes and overall system throughput. To address these challenges, we propose \textbf{CXL-SpecKV}, a novel disaggregated KV-cache architecture that leverages Compute Express Link (CXL) interconnects and FPGA accelerators to enable efficient speculative execution and memory disaggregation. Our approach introduces three key innovations: (i) a CXL-based memory disaggregation framework that offloads KV-caches to remote FPGA memory with low latency, (ii) a speculative KV-cache prefetching mechanism that predicts and preloads future tokens' cache entries, and (iii) an FPGA-accelerated KV-cache compression and decompression engine that reduces memory bandwidth requirements by up to 4$\times$. When evaluated on state-of-the-art LLM models, CXL-SpecKV achieves up to 3.2$\times$ higher throughput compared to GPU-only baselines, while reducing memory costs by 2.8$\times$ and maintaining accuracy. Our system demonstrates that intelligent memory disaggregation combined with speculative execution can effectively address the memory wall challenge in large-scale LLM serving. Our code implementation has been open-sourced at https://github.com/FastLM/CXL-SpecKV.