PACIFIC: a framework for generating benchmarks to check Precise Automatically Checked Instruction Following In Code
作者: Itay Dreyfuss, Antonio Abu Nassar, Samuel Ackerman, Axel Ben David, Eitan Farchi, Rami Katan, Orna Raz, Marcel Zalmanovici
分类: cs.SE, cs.AI
发布日期: 2025-12-11 (更新: 2025-12-22)
💡 一句话要点
PACIFIC:用于生成基准以评估LLM代码指令遵循能力的框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码理解 指令遵循 大型语言模型 基准测试 代码推理 干运行 自动评估
📋 核心要点
- 现有方法在评估LLM代码能力时,常依赖工具或代理行为,难以隔离评估LLM的指令遵循和代码推理能力。
- PACIFIC框架通过自动生成具有明确预期输出的基准,来评估LLM在代码干运行和指令遵循方面的能力。
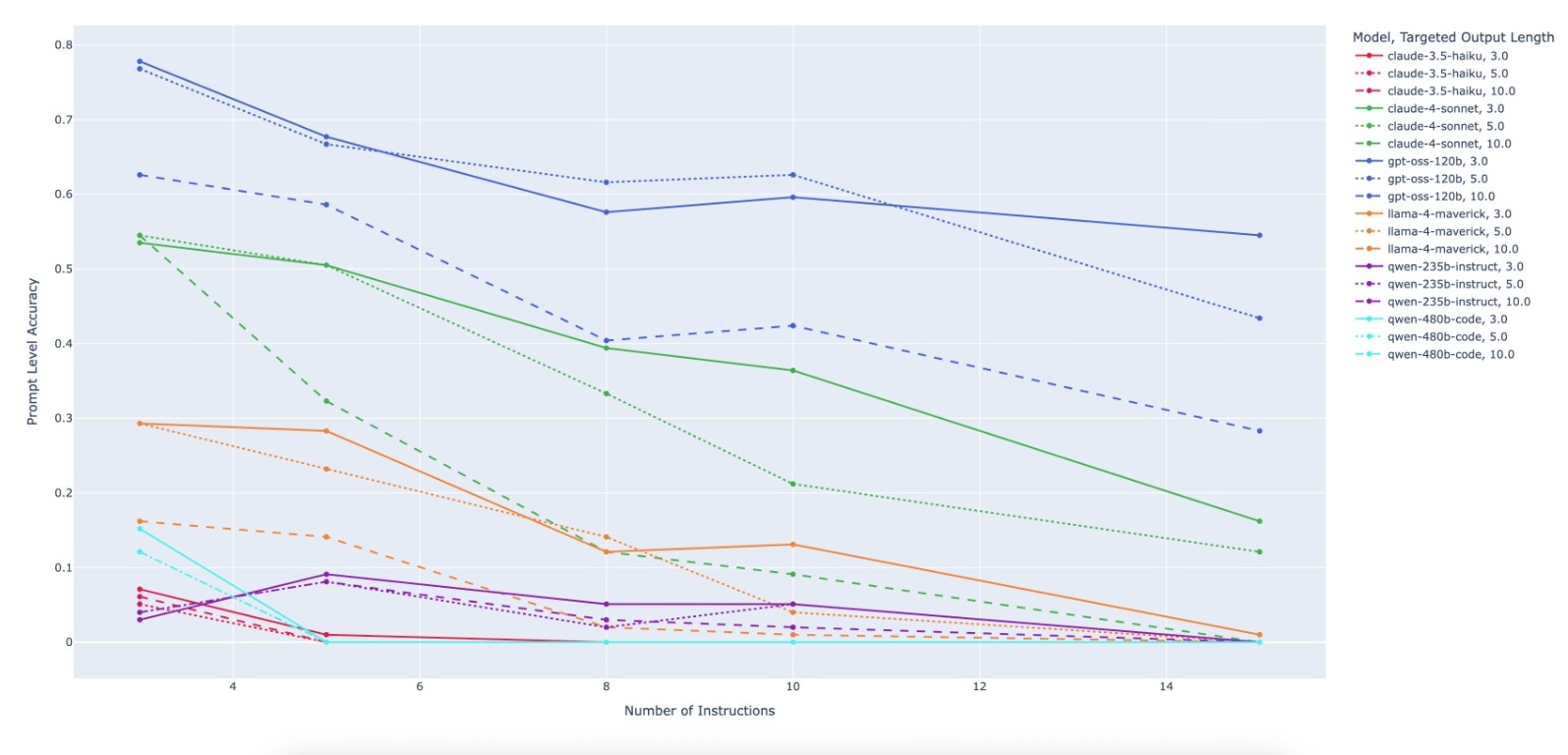
- 实验结果表明,PACIFIC能生成不同难度的基准,有效区分LLM的指令遵循和代码推理能力,并缓解训练数据污染。
📝 摘要(中文)
本文提出PACIFIC,一个新颖的框架,旨在自动生成基准,严格评估大型语言模型(LLM)在代码中顺序指令遵循和代码干运行方面的能力,同时允许控制基准难度。PACIFIC生成具有明确定义的预期输出的基准变体,从而可以通过简单的输出比较实现直接而可靠的评估。与通常依赖于工具使用或代理行为的现有方法不同,我们的工作分离并评估了LLM在没有执行的情况下逐步推理代码行为(干运行)和遵循指令的内在能力。此外,我们的框架通过促进新基准变体的轻松生成来减轻训练数据污染。我们通过生成一套涵盖一系列难度级别的基准并评估多个最先进的LLM来验证我们的框架。结果表明,PACIFIC可以生成越来越具有挑战性的基准,从而有效地区分指令遵循和干运行能力,即使在高级模型中也是如此。总而言之,我们的框架为评估LLM在代码相关任务中的核心能力提供了一种可扩展的、抗污染的方法。
🔬 方法详解
问题定义:现有评估LLM代码能力的方法,例如代码生成和理解,往往依赖于工具使用或代理行为。这些方法难以隔离评估LLM本身在理解代码逻辑、逐步推理代码行为(即干运行)以及准确遵循指令方面的内在能力。此外,训练数据污染也是一个潜在的问题,因为LLM可能已经在训练数据中见过某些特定的代码片段或问题,从而影响评估的准确性。
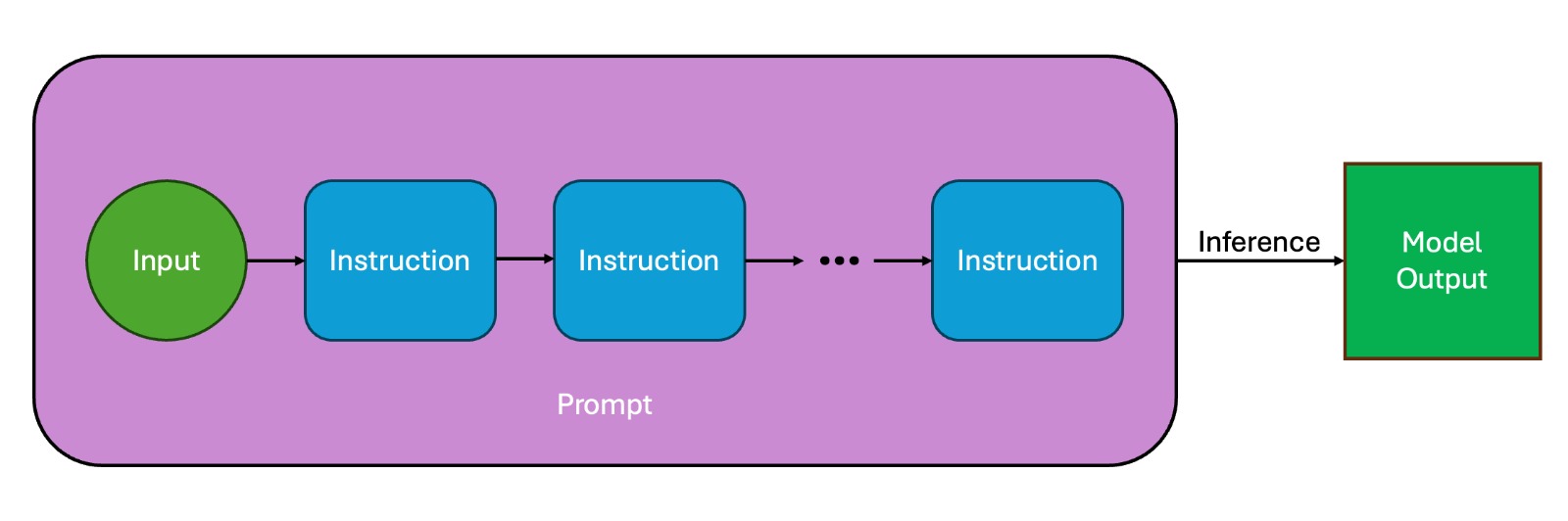
核心思路:PACIFIC框架的核心思路是自动生成一系列具有明确预期输出的代码基准,这些基准专门设计用于评估LLM在代码干运行和指令遵循方面的能力。通过控制基准的难度,可以更精细地评估LLM在不同复杂程度下的表现。这种方法旨在隔离LLM的内在推理能力,避免外部工具或代理的影响,并减轻训练数据污染。
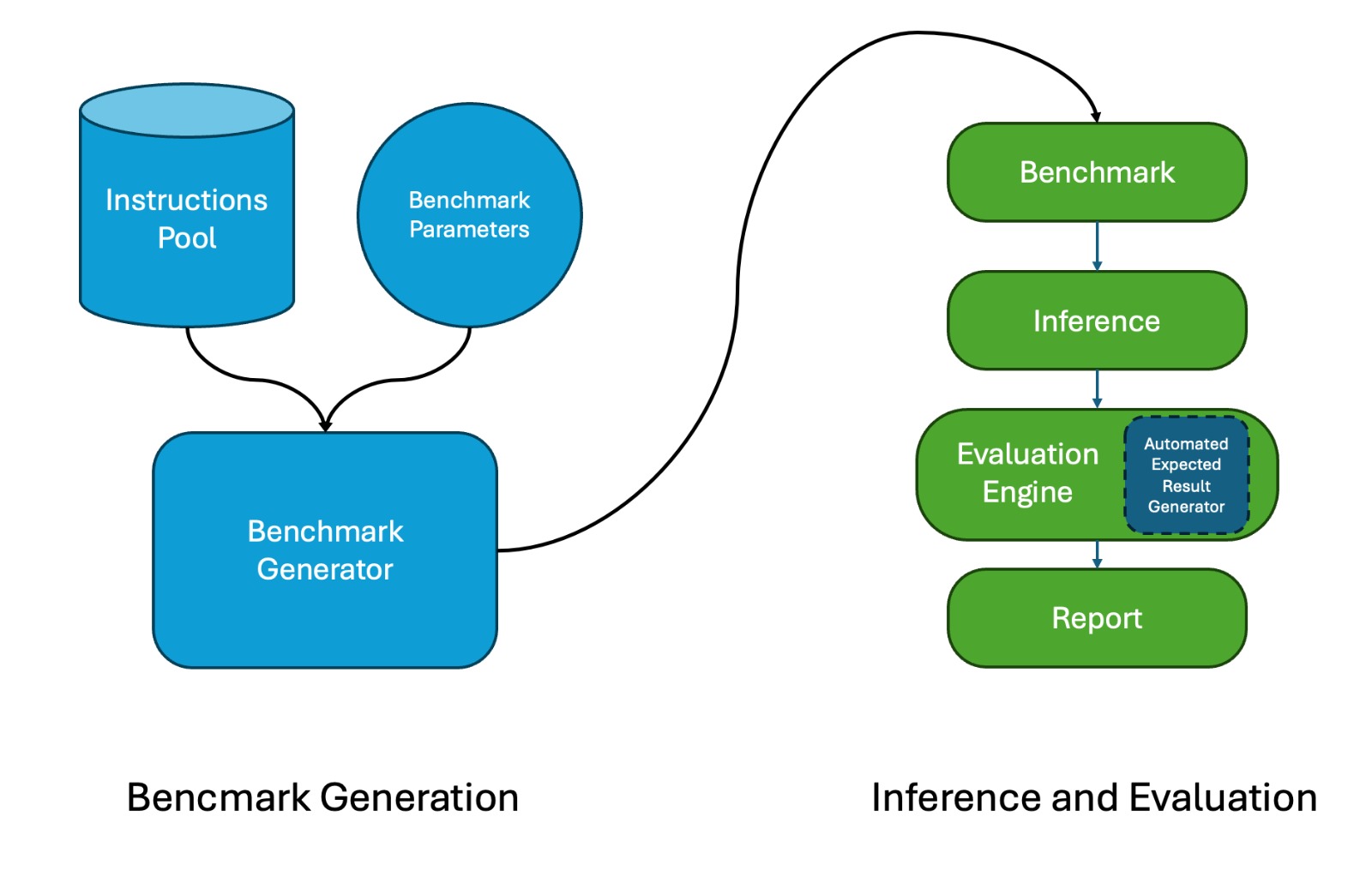
技术框架:PACIFIC框架包含以下主要模块:1) 基准生成器:根据预定义的规则和难度级别,自动生成包含代码和指令的基准测试用例。2) 预期输出生成器:为每个基准测试用例生成明确的预期输出,这些输出基于对代码逻辑和指令的正确理解。3) 评估器:将LLM的输出与预期输出进行比较,以评估LLM的性能。4) 难度控制器:允许用户控制基准的难度,例如代码的复杂性、指令的数量和类型等。
关键创新:PACIFIC的关键创新在于其自动生成基准的能力,这些基准专门设计用于评估LLM在代码干运行和指令遵循方面的能力。与现有方法相比,PACIFIC能够更精确地评估LLM的内在推理能力,并减轻训练数据污染。此外,PACIFIC还提供了一种可控的难度调整机制,允许用户根据需要生成不同难度的基准。
关键设计:PACIFIC框架的关键设计包括:1) 使用形式化的规则来生成代码和指令,以确保基准的质量和可控性。2) 使用符号执行或静态分析等技术来生成预期输出,以确保评估的准确性。3) 设计一种灵活的难度控制机制,允许用户调整基准的各个方面,例如代码的长度、循环的嵌套深度、指令的数量等。4) 采用模块化的架构,方便扩展和定制。
🖼️ 关键图片
📊 实验亮点
实验结果表明,PACIFIC能够生成具有不同难度的基准,有效地区分不同LLM的指令遵循和代码推理能力。即使是最先进的LLM,在面对更具挑战性的PACIFIC基准时,性能也会显著下降。这表明PACIFIC能够有效地评估LLM在代码相关任务中的真实能力,并发现其潜在的局限性。
🎯 应用场景
PACIFIC框架可用于评估和比较不同LLM在代码理解和推理方面的能力,帮助研究人员和开发者选择最适合特定任务的LLM。此外,该框架还可以用于开发更有效的LLM训练方法,提高LLM在代码相关任务中的性能。未来,PACIFIC可以扩展到支持更多编程语言和更复杂的代码任务,并与其他评估工具集成,形成更全面的LLM评估体系。
📄 摘要(原文)
Large Language Model (LLM)-based code assistants have emerged as a powerful application of generative AI, demonstrating impressive capabilities in code generation and comprehension. A key requirement for these systems is their ability to accurately follow user instructions. We present Precise Automatically Checked Instruction Following In Code (PACIFIC), a novel framework designed to automatically generate benchmarks that rigorously assess sequential instruction-following and code dry-running capabilities in LLMs, while allowing control over benchmark difficulty. PACIFIC produces benchmark variants with clearly defined expected outputs, enabling straightforward and reliable evaluation through simple output comparisons. In contrast to existing approaches that often rely on tool usage or agentic behavior, our work isolates and evaluates the LLM's intrinsic ability to reason through code behavior step-by-step without execution (dry running) and to follow instructions. Furthermore, our framework mitigates training data contamination by facilitating effortless generation of novel benchmark variations. We validate our framework by generating a suite of benchmarks spanning a range of difficulty levels and evaluating multiple state-of-the-art LLMs. Our results demonstrate that PACIFIC can produce increasingly challenging benchmarks that effectively differentiate instruction-following and dry running capabilities, even among advanced models. Overall, our framework offers a scalable, contamination-resilient methodology for assessing core competencies of LLMs in code-related tasks.