Remember Me, Refine Me: A Dynamic Procedural Memory Framework for Experience-Driven Agent Evolution
作者: Zouying Cao, Jiaji Deng, Li Yu, Weikang Zhou, Zhaoyang Liu, Bolin Ding, Hai Zhao
分类: cs.AI, cs.CL
发布日期: 2025-12-11
备注: 16 pages, 9 figures, 9 tables
💡 一句话要点
ReMe:提出一种动态程序记忆框架,驱动Agent经验式进化
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 程序记忆 Agent学习 经验驱动 动态记忆 终身学习
📋 核心要点
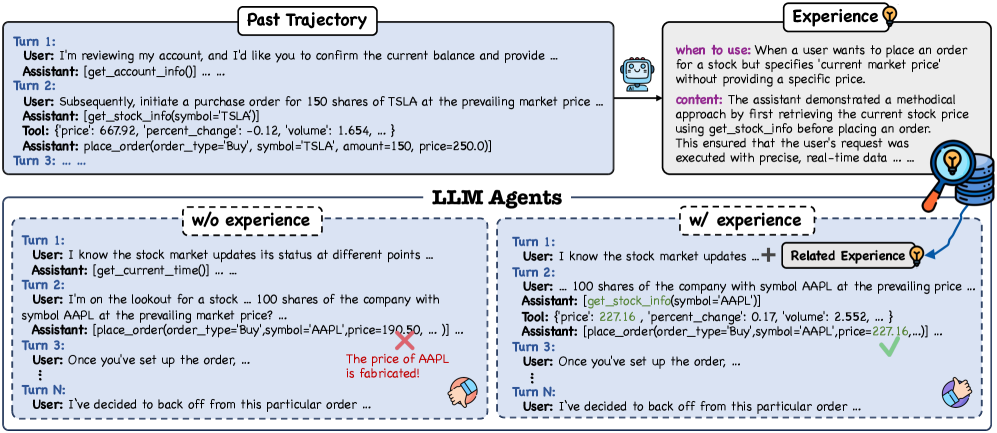
- 现有Agent记忆框架主要采用“被动积累”模式,将记忆视为静态的只追加档案,缺乏动态推理能力。
- ReMe框架通过多方面提炼、上下文自适应重用和基于效用的提炼,实现了记忆的动态更新和优化,提升了Agent的经验学习能力。
- 实验表明,配备ReMe的较小模型Qwen3-8B优于更大的无记忆模型Qwen3-14B,验证了ReMe的有效性和计算效率。
📝 摘要(中文)
本文提出ReMe(Remember Me, Refine Me),一个用于经验驱动的Agent进化的综合框架。ReMe通过三种机制在记忆生命周期中进行创新:1) 多方面提炼,通过识别成功模式、分析失败触发因素和生成比较性见解来提取细粒度的经验;2) 上下文自适应重用,通过场景感知索引将历史见解调整到新的上下文中;3) 基于效用的提炼,自主添加有效记忆并修剪过时的记忆,以维持一个紧凑、高质量的经验池。在BFCL-V3和AppWorld上的大量实验表明,ReMe在Agent记忆系统中建立了一个新的技术水平。更重要的是,我们观察到一个显著的记忆缩放效应:配备ReMe的Qwen3-8B优于更大的、无记忆的Qwen3-14B,这表明自我进化的记忆为终身学习提供了一条计算高效的途径。我们发布了我们的代码和reme.library数据集,以促进进一步的研究。
🔬 方法详解
问题定义:现有的大语言模型(LLM)Agent的程序记忆框架,通常采用被动积累的方式,简单地将经验存储起来,缺乏对经验的提炼、重用和更新机制。这导致记忆效率低下,无法充分利用历史经验来指导未来的决策,限制了Agent的终身学习能力。
核心思路:ReMe的核心思路是构建一个动态的程序记忆框架,使Agent能够主动地从经验中学习,并根据新的情境调整和优化记忆。通过多方面提炼提取关键信息,通过上下文自适应重用将历史经验应用于新场景,并通过基于效用的提炼保持记忆库的质量和效率。
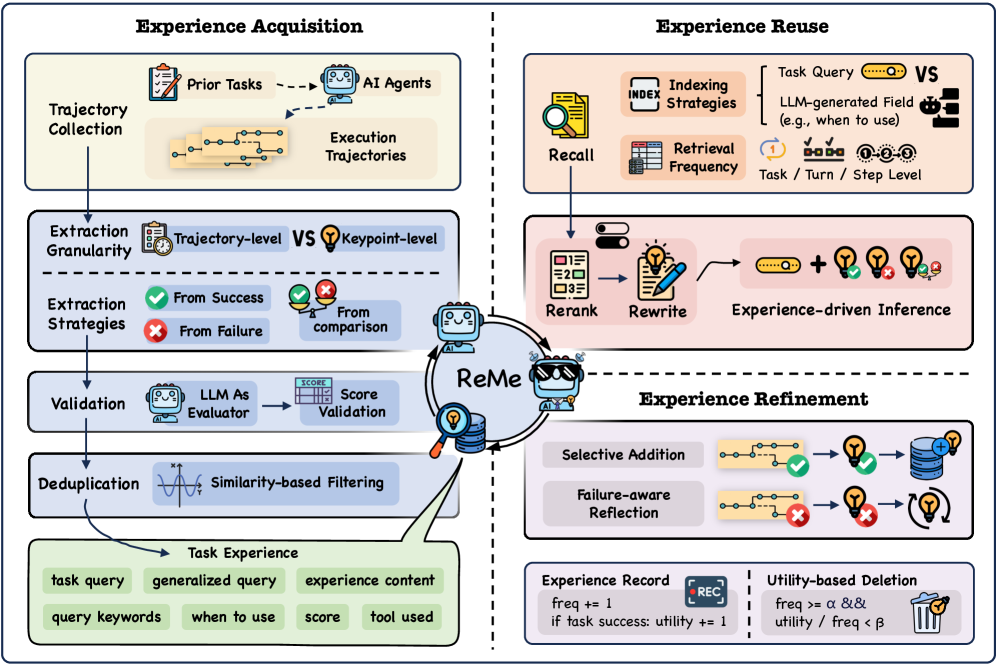
技术框架:ReMe框架包含三个主要模块:1) 多方面提炼(Multi-faceted Distillation):从Agent的成功和失败经验中提取细粒度的信息,包括成功模式、失败触发因素和比较性见解。2) 上下文自适应重用(Context-adaptive Reuse):根据当前场景,从记忆库中检索相关的经验,并进行调整以适应新的情境。3) 基于效用的提炼(Utility-based Refinement):根据记忆的效用值,自动添加新的有效记忆,并删除过时的或冗余的记忆。
关键创新:ReMe的关键创新在于其动态的记忆管理机制,它超越了传统的被动积累模式,实现了记忆的自我进化。通过多方面提炼、上下文自适应重用和基于效用的提炼,ReMe能够有效地利用历史经验,提高Agent的学习效率和泛化能力。与现有方法相比,ReMe更加注重记忆的质量和效率,而不是简单地增加记忆的数量。
关键设计:多方面提炼模块使用LLM来分析Agent的行动轨迹,识别成功和失败的关键因素。上下文自适应重用模块使用语义索引技术来检索相关的历史经验,并使用LLM来调整这些经验以适应新的情境。基于效用的提炼模块使用效用函数来评估记忆的价值,并根据效用值来添加或删除记忆。效用函数的具体形式和参数设置需要根据具体的应用场景进行调整。
🖼️ 关键图片
📊 实验亮点
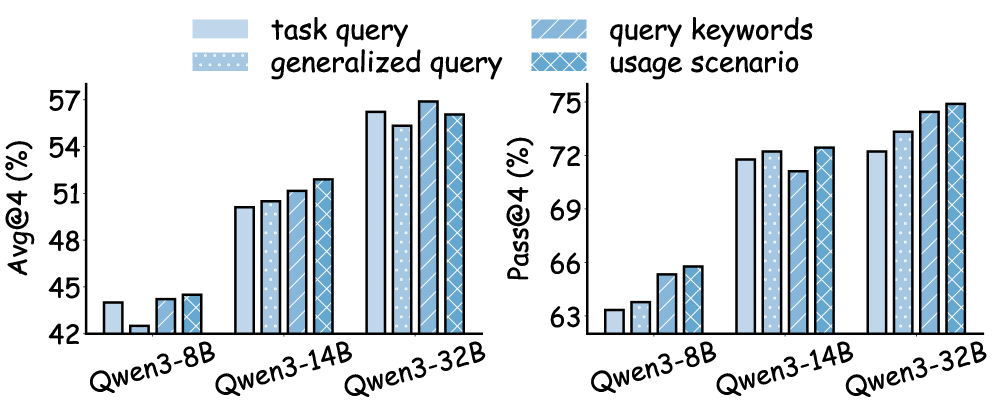
实验结果表明,ReMe在BFCL-V3和AppWorld两个benchmark上都取得了state-of-the-art的性能。更重要的是,配备ReMe的Qwen3-8B模型在性能上超越了更大的无记忆模型Qwen3-14B,这表明ReMe能够显著提高Agent的记忆效率,并为终身学习提供了一条计算高效的途径。该结果突出了动态记忆管理的重要性。
🎯 应用场景
ReMe框架可应用于各种需要Agent进行持续学习和适应的应用场景,例如游戏AI、机器人控制、智能助手等。通过不断学习和优化记忆,Agent可以更好地理解环境,做出更明智的决策,并提高其在复杂环境中的适应能力。该研究为构建更智能、更高效的Agent系统提供了新的思路。
📄 摘要(原文)
Procedural memory enables large language model (LLM) agents to internalize "how-to" knowledge, theoretically reducing redundant trial-and-error. However, existing frameworks predominantly suffer from a "passive accumulation" paradigm, treating memory as a static append-only archive. To bridge the gap between static storage and dynamic reasoning, we propose $\textbf{ReMe}$ ($\textit{Remember Me, Refine Me}$), a comprehensive framework for experience-driven agent evolution. ReMe innovates across the memory lifecycle via three mechanisms: 1) $\textit{multi-faceted distillation}$, which extracts fine-grained experiences by recognizing success patterns, analyzing failure triggers and generating comparative insights; 2) $\textit{context-adaptive reuse}$, which tailors historical insights to new contexts via scenario-aware indexing; and 3) $\textit{utility-based refinement}$, which autonomously adds valid memories and prunes outdated ones to maintain a compact, high-quality experience pool. Extensive experiments on BFCL-V3 and AppWorld demonstrate that ReMe establishes a new state-of-the-art in agent memory system. Crucially, we observe a significant memory-scaling effect: Qwen3-8B equipped with ReMe outperforms larger, memoryless Qwen3-14B, suggesting that self-evolving memory provides a computation-efficient pathway for lifelong learning. We release our code and the $\texttt{reme.library}$ dataset to facilitate further research.