Enhancing Radiology Report Generation and Visual Grounding using Reinforcement Learning
作者: Benjamin Gundersen, Nicolas Deperrois, Samuel Ruiperez-Campillo, Thomas M. Sutter, Julia E. Vogt, Michael Moor, Farhad Nooralahzadeh, Michael Krauthammer
分类: cs.AI, cs.CV
发布日期: 2025-12-11
备注: 10 pages main text (3 figures, 3 tables), 31 pages in total
💡 一句话要点
利用强化学习增强放射报告生成和视觉定位,提升医学VLM性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 放射报告生成 视觉定位 强化学习 医学视觉语言模型 胸部X光 Qwen3-VL 分组相对策略优化
📋 核心要点
- 现有医学视觉-语言模型(VLM)主要依赖监督微调,缺乏对生成报告质量的直接优化。
- 论文提出结合强化学习(RL)和显式推理(“思考”)来优化CXR报告生成和视觉定位任务。
- 实验表明,强化学习能有效提升报告生成和视觉定位性能,达到当前最优水平,但显式思考未带来显著增益。
📝 摘要(中文)
近年来,视觉-语言模型(VLM)在胸部X光(CXR)图像解读方面取得了显著进展。然而,许多医学VLM仅依赖于监督微调(SFT),这种方法优化了下一个token的预测,而忽略了答案质量的评估。相比之下,强化学习(RL)可以整合特定于任务的反馈,并且其与显式中间推理(“思考”)的结合已在可验证的数学和编码任务中展现出显著的优势。为了研究RL和思考在CXR VLM中的影响,我们首先在CXR数据上进行大规模SFT,构建了一个基于Qwen3-VL的RadVLM,然后进行冷启动SFT阶段,使模型具备基本的思考能力。接着,我们应用分组相对策略优化(GRPO),并结合临床相关的、特定于任务的奖励,用于报告生成和视觉定位。我们在领域特定和通用领域的Qwen3-VL变体上进行了匹配的RL实验,无论是否具备思考能力。结果表明,虽然强大的SFT对于高基础性能至关重要,但RL在两项任务上都提供了额外的增益,而显式思考似乎并没有进一步改善结果。在一个统一的评估流程下,经过RL优化的RadVLM模型优于其基线模型,并在报告生成和定位方面达到了最先进的性能,突出了临床对齐的RL是医学VLM中SFT的强大补充。
🔬 方法详解
问题定义:论文旨在解决医学视觉-语言模型在胸部X光报告生成和视觉定位任务中,仅依赖监督微调而忽略报告质量评估的问题。现有方法难以直接优化临床相关指标,且缺乏利用强化学习进行任务特定优化的探索。
核心思路:论文的核心思路是利用强化学习,通过临床相关的奖励信号,直接优化模型的报告生成和视觉定位能力。通过将强化学习与预训练的视觉-语言模型相结合,可以有效地利用大规模数据进行预训练,并通过强化学习进行任务特定优化。
技术框架:整体框架包括三个主要阶段:1) 基于Qwen3-VL进行大规模监督微调(SFT),构建RadVLM;2) 冷启动SFT,赋予模型基本的“思考”能力;3) 应用分组相对策略优化(GRPO)进行强化学习,使用临床相关的奖励函数优化报告生成和视觉定位任务。该框架允许研究强化学习和“思考”能力对模型性能的影响。
关键创新:论文的关键创新在于将强化学习应用于医学视觉-语言模型,并设计了临床相关的奖励函数,以直接优化报告生成和视觉定位任务。此外,论文还探索了显式推理(“思考”)在医学VLM中的作用,并发现其对性能的提升并不显著。
关键设计:论文使用了Qwen3-VL作为基础模型,并进行了大规模的监督微调。在强化学习阶段,使用了分组相对策略优化(GRPO)算法,并设计了针对报告生成和视觉定位任务的奖励函数。奖励函数的设计考虑了临床相关性,例如报告的准确性和完整性,以及定位的精确性。
🖼️ 关键图片


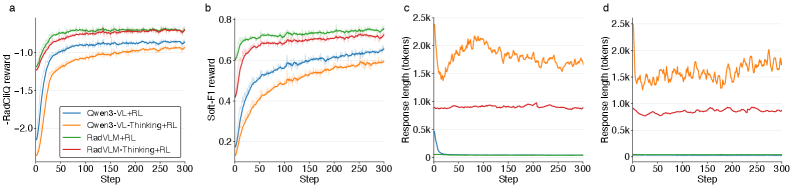
📊 实验亮点
实验结果表明,经过强化学习优化的RadVLM模型在报告生成和视觉定位任务上均优于基线模型,并达到了当前最优性能。具体而言,强化学习在强监督微调的基础上,进一步提升了模型的性能,证明了临床对齐的强化学习是医学VLM中SFT的有效补充。但显式思考并未带来显著增益。
🎯 应用场景
该研究成果可应用于辅助放射科医生进行胸部X光报告的自动生成和病灶定位,提高诊断效率和准确性。通过强化学习优化,模型能够生成更符合临床需求的报告,并提供更精确的视觉定位,具有重要的临床应用价值。未来可扩展到其他医学影像模态和疾病诊断。
📄 摘要(原文)
Recent advances in vision-language models (VLMs) have improved Chest X-ray (CXR) interpretation in multiple aspects. However, many medical VLMs rely solely on supervised fine-tuning (SFT), which optimizes next-token prediction without evaluating answer quality. In contrast, reinforcement learning (RL) can incorporate task-specific feedback, and its combination with explicit intermediate reasoning ("thinking") has demonstrated substantial gains on verifiable math and coding tasks. To investigate the effects of RL and thinking in a CXR VLM, we perform large-scale SFT on CXR data to build an updated RadVLM based on Qwen3-VL, followed by a cold-start SFT stage that equips the model with basic thinking ability. We then apply Group Relative Policy Optimization (GRPO) with clinically grounded, task-specific rewards for report generation and visual grounding, and run matched RL experiments on both domain-specific and general-domain Qwen3-VL variants, with and without thinking. Across these settings, we find that while strong SFT remains crucial for high base performance, RL provides additional gains on both tasks, whereas explicit thinking does not appear to further improve results. Under a unified evaluation pipeline, the RL-optimized RadVLM models outperform their baseline counterparts and reach state-of-the-art performance on both report generation and grounding, highlighting clinically aligned RL as a powerful complement to SFT for medical VLMs.