Exploring LLMs for Scientific Information Extraction Using The SciEx Framework
作者: Sha Li, Ayush Sadekar, Nathan Self, Yiqi Su, Lars Andersland, Mira Chaplin, Annabel Zhang, Hyoju Yang, James B Henderson, Krista Wigginton, Linsey Marr, T. M. Murali, Naren Ramakrishnan
分类: cs.AI, cs.CL
发布日期: 2025-12-10 (更新: 2026-01-23)
备注: Accepted to the KGML Bridge at AAAI 2026 (non-archival)
💡 一句话要点
SciEx框架:探索LLM在科学信息抽取中的应用,解决长文本、多模态和模式快速变化难题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 科学信息抽取 大型语言模型 模块化框架 多模态检索 知识图谱
📋 核心要点
- 现有科学信息抽取方法难以处理长文本、多模态内容以及模式快速变化带来的挑战。
- SciEx框架通过解耦PDF解析、多模态检索、抽取和聚合等模块,实现灵活和可扩展的抽取流程。
- 实验结果表明,SciEx框架能够准确且一致地抽取细粒度信息,并揭示了LLM在科学信息抽取中的优缺点。
📝 摘要(中文)
大型语言模型(LLM)正日益被认为是自动化科学信息抽取的强大工具。然而,现有方法和工具常常难以应对科学文献的实际情况:长上下文文档、多模态内容,以及将多个出版物中各种不一致的细粒度信息协调成标准化格式。当所需的数据模式或抽取本体快速变化时,这些挑战会进一步加剧,使得重新设计或微调现有系统变得困难。我们提出了SciEx,一个模块化和可组合的框架,它解耦了关键组件,包括PDF解析、多模态检索、抽取和聚合。这种设计简化了按需数据抽取,同时实现了可扩展性和新模型、提示策略和推理机制的灵活集成。我们在跨越三个科学主题的数据集上评估了SciEx准确且一致地抽取细粒度信息的能力。我们的发现为当前基于LLM的pipeline的优势和局限性提供了实践见解。
🔬 方法详解
问题定义:论文旨在解决科学文献信息抽取中面临的挑战,包括长文本上下文处理、多模态信息融合以及数据模式快速变化带来的系统维护困难。现有方法在处理这些问题时,往往需要针对特定领域进行定制化开发和频繁的重新设计,缺乏通用性和灵活性。
核心思路:论文的核心思路是将科学信息抽取流程解耦为多个独立的模块,包括PDF解析、多模态检索、信息抽取和结果聚合。通过模块化的设计,可以灵活地替换和组合不同的模块,从而适应不同的科学领域和数据模式。这种解耦的设计使得系统更容易维护和扩展,也方便集成新的模型和技术。
技术框架:SciEx框架包含以下主要模块:1) PDF解析模块,负责将PDF文档转换为结构化文本;2) 多模态检索模块,用于从文本、图像和表格等多种模态中检索相关信息;3) 信息抽取模块,利用LLM从检索到的信息中抽取目标实体和关系;4) 结果聚合模块,将抽取的结果进行整合和标准化,生成最终的抽取结果。这些模块可以根据实际需求进行灵活组合和配置。
关键创新:SciEx框架的关键创新在于其模块化和可组合的设计。与传统的端到端信息抽取系统相比,SciEx框架更加灵活和可扩展,可以方便地集成新的模型和技术。此外,SciEx框架还支持多模态信息的抽取,能够更好地利用科学文献中的各种信息源。
关键设计:SciEx框架的关键设计包括:1) 使用预训练的LLM作为信息抽取模块的核心,利用LLM强大的语言理解和生成能力;2) 设计了灵活的提示策略,引导LLM抽取目标实体和关系;3) 采用了多种数据增强技术,提高LLM的泛化能力;4) 实现了自动化的评估流程,方便评估不同模块和配置的性能。
🖼️ 关键图片
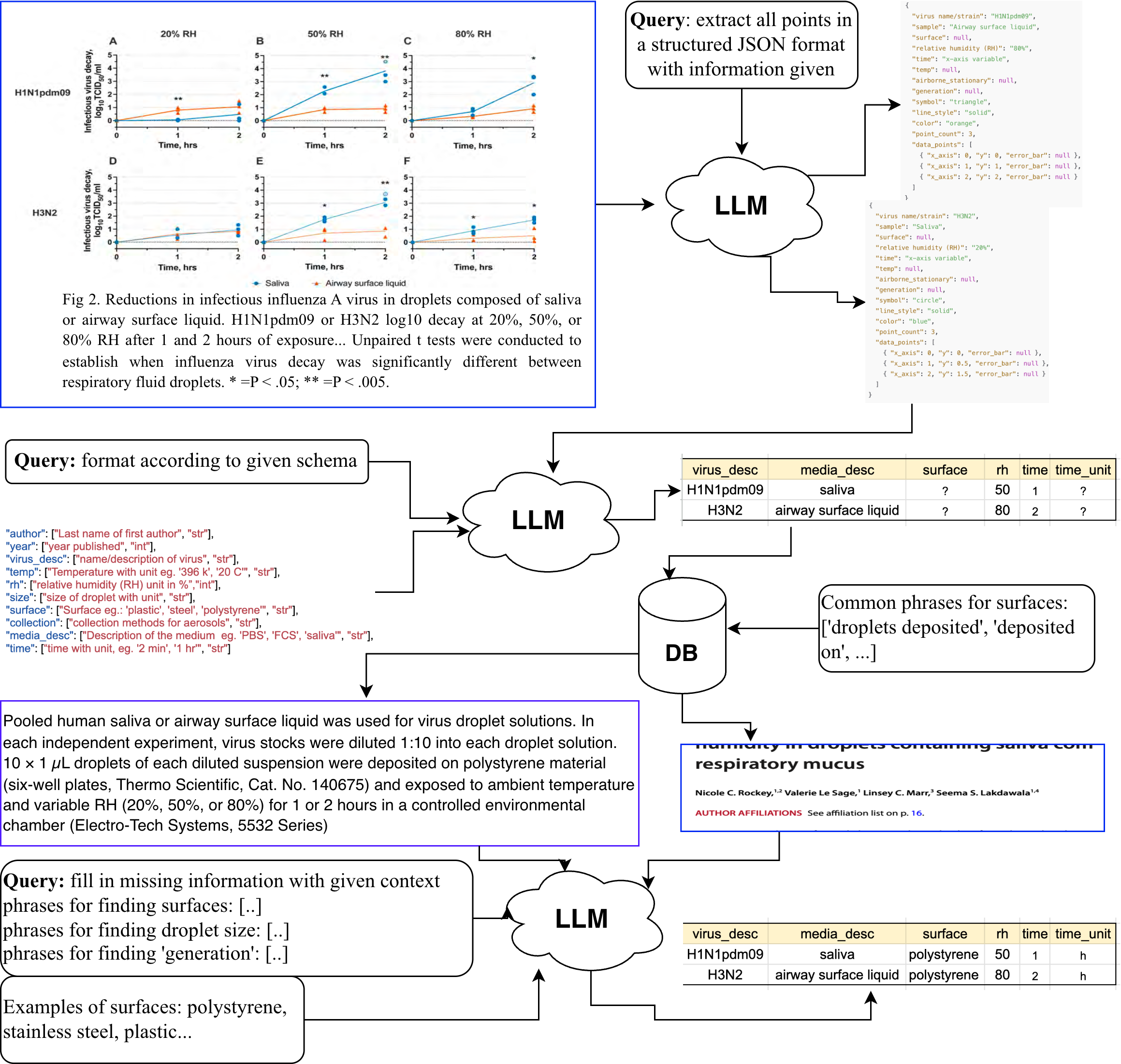
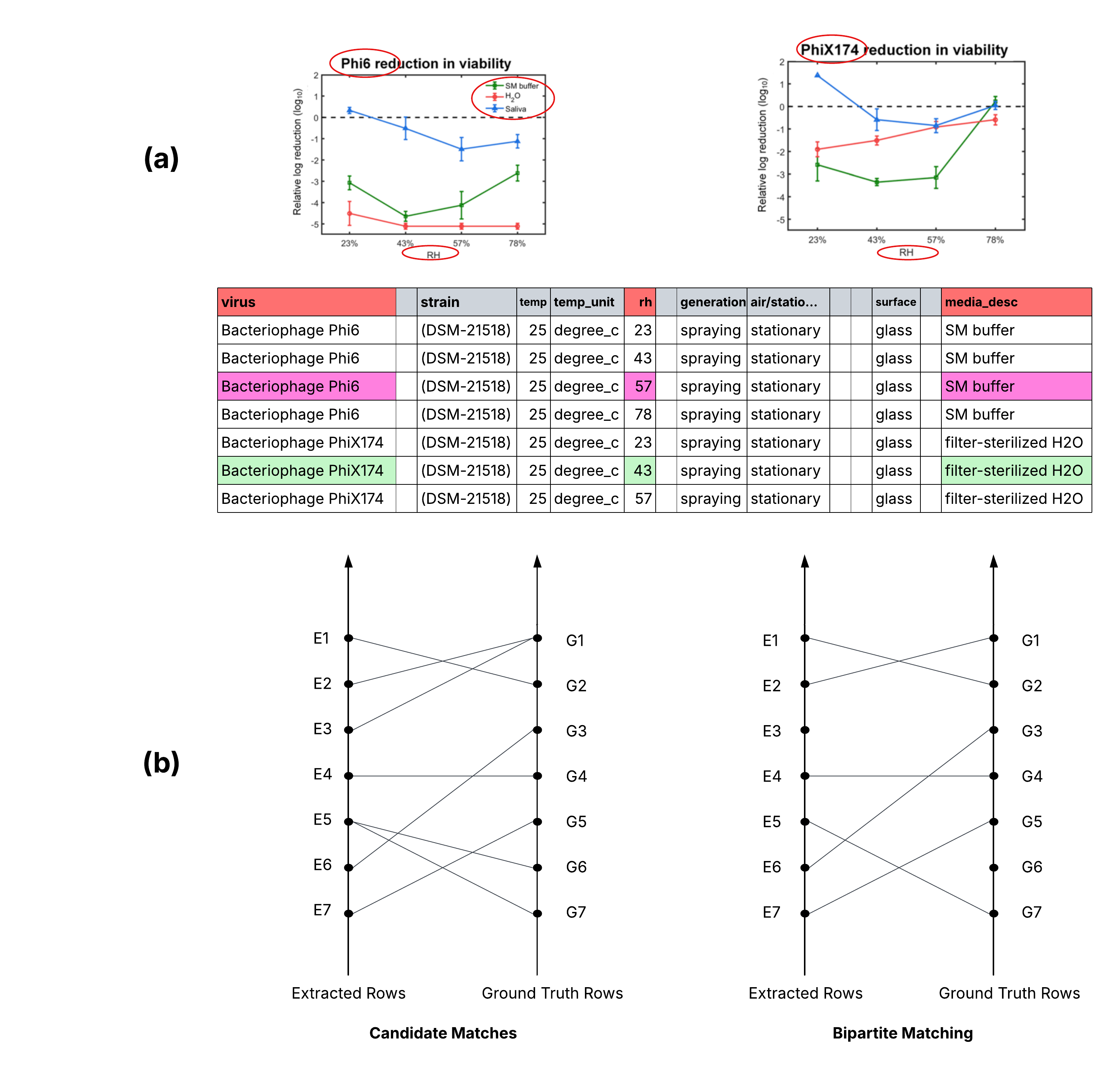
📊 实验亮点
论文在三个科学主题的数据集上评估了SciEx框架的性能。实验结果表明,SciEx框架能够准确且一致地抽取细粒度信息。与传统的基于规则的方法相比,SciEx框架在准确率和召回率方面均有显著提升。此外,实验还揭示了LLM在科学信息抽取中的优势和局限性,为未来的研究提供了宝贵的经验。
🎯 应用场景
SciEx框架可应用于多个科学领域的信息抽取,例如材料科学、生物医学和环境科学等。它可以帮助研究人员快速获取和整理文献中的关键信息,加速科学发现的进程。此外,SciEx框架还可以用于构建知识图谱和数据库,为科学研究提供更全面的数据支持。未来,该框架有望应用于自动化文献综述、智能科研助手等领域。
📄 摘要(原文)
Large language models (LLMs) are increasingly touted as powerful tools for automating scientific information extraction. However, existing methods and tools often struggle with the realities of scientific literature: long-context documents, multi-modal content, and reconciling varied and inconsistent fine-grained information across multiple publications into standardized formats. These challenges are further compounded when the desired data schema or extraction ontology changes rapidly, making it difficult to re-architect or fine-tune existing systems. We present SciEx, a modular and composable framework that decouples key components including PDF parsing, multi-modal retrieval, extraction, and aggregation. This design streamlines on-demand data extraction while enabling extensibility and flexible integration of new models, prompting strategies, and reasoning mechanisms. We evaluate SciEx on datasets spanning three scientific topics for its ability to extract fine-grained information accurately and consistently. Our findings provide practical insights into both the strengths and limitations of current LLM-based pipelines.