ThinkTrap: Denial-of-Service Attacks against Black-box LLM Services via Infinite Thinking
作者: Yunzhe Li, Jianan Wang, Hongzi Zhu, James Lin, Shan Chang, Minyi Guo
分类: cs.CR, cs.AI, cs.LG
发布日期: 2025-12-08
备注: This version includes the final camera-ready manuscript accepted by NDSS 2026
💡 一句话要点
ThinkTrap:针对黑盒LLM服务的无限思考拒绝服务攻击
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 拒绝服务攻击 大型语言模型 黑盒攻击 对抗性提示 嵌入空间优化
📋 核心要点
- 现有LLM云服务面临拒绝服务攻击风险,攻击者可构造恶意输入使模型进入无限循环,耗尽计算资源。
- ThinkTrap通过在嵌入空间优化输入,寻找能诱导LLM无限生成的对抗性提示,实现高效的黑盒攻击。
- 实验表明,即使在低请求频率下,ThinkTrap也能显著降低商业LLM服务的吞吐量,甚至导致服务崩溃。
📝 摘要(中文)
大型语言模型(LLM)已成为各种应用的基础组件,包括自然语言理解和生成、具身智能和科学发现。随着计算需求的不断增长,这些模型越来越多地以云服务的形式部署,允许用户通过互联网访问强大的LLM。然而,这种部署模式引入了一种新的威胁:通过无限推理的拒绝服务(DoS)攻击,攻击者精心设计的输入会导致模型进入过长或无限的生成循环。这些攻击会耗尽后端计算资源,降低或拒绝为合法用户提供服务。为了降低此类风险,许多LLM提供商采用闭源、黑盒设置来隐藏模型内部结构。在本文中,我们提出了ThinkTrap,这是一种新颖的输入空间优化框架,用于针对黑盒环境中的LLM服务进行DoS攻击。ThinkTrap的核心思想是首先将离散token映射到连续嵌入空间,然后利用输入稀疏性在低维子空间中进行高效的黑盒优化。这种优化的目标是识别对抗性提示,这些提示会导致多个最先进的LLM进行扩展或非终止生成,从而以最小的token开销实现DoS。我们评估了在多个商业、闭源LLM服务上提出的攻击。我们的结果表明,即使远低于这些平台通常强制执行的限制性请求频率限制(通常限制为每分钟十个请求(10 RPM)),该攻击也可以将服务吞吐量降低到其原始容量的1%,并且在某些情况下,导致完全的服务故障。
🔬 方法详解
问题定义:论文旨在解决黑盒LLM服务面临的拒绝服务(DoS)攻击问题。现有的防御方法难以应对精心设计的对抗性输入,攻击者可以通过构造特定prompt使LLM进入无限循环,从而耗尽服务器资源,影响正常用户的使用。由于LLM服务通常以黑盒形式提供,攻击者无法直接访问模型内部参数和结构,增加了攻击的难度。
核心思路:ThinkTrap的核心思路是在LLM的输入空间中寻找对抗性prompt,这些prompt能够诱导LLM产生无限或极长的输出序列,从而达到拒绝服务的目的。为了在黑盒环境下高效地搜索这些prompt,ThinkTrap将离散的token映射到连续的嵌入空间,并在低维子空间中进行优化。
技术框架:ThinkTrap的整体框架包括以下几个主要步骤:1)嵌入映射:将离散的输入token映射到连续的嵌入空间。2)子空间选择:选择一个低维子空间进行优化,以降低搜索空间维度。3)黑盒优化:在选定的子空间中,使用黑盒优化算法(如进化策略)搜索对抗性prompt。4)prompt生成:将优化后的嵌入向量转换回离散的token序列,作为最终的对抗性prompt。5)攻击评估:将生成的对抗性prompt发送给目标LLM服务,评估其对服务性能的影响。
关键创新:ThinkTrap的关键创新在于其在连续嵌入空间中进行对抗性prompt搜索的方法。与传统的在离散token空间中搜索的方法相比,ThinkTrap能够更高效地探索prompt空间,并找到更有效的对抗性prompt。此外,ThinkTrap利用输入稀疏性,在低维子空间中进行优化,进一步降低了搜索的计算复杂度。
关键设计:ThinkTrap的关键设计包括:1)嵌入空间的选择:使用预训练的词嵌入模型(如Word2Vec或GloVe)将token映射到嵌入空间。2)子空间选择策略:选择与目标任务相关的token对应的嵌入向量作为子空间的基向量。3)黑盒优化算法:使用进化策略(Evolution Strategies)作为黑盒优化算法,因为它具有较好的全局搜索能力和鲁棒性。4)目标函数设计:设计一个目标函数,用于评估生成的prompt的对抗性,例如,可以使用生成序列的长度作为目标函数。
🖼️ 关键图片

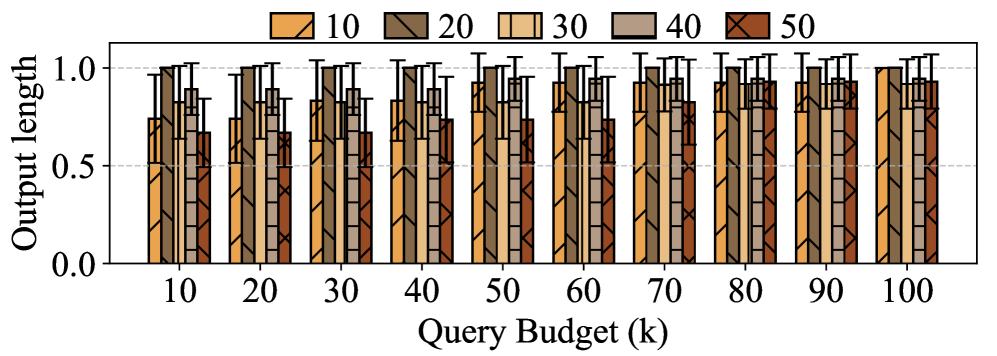
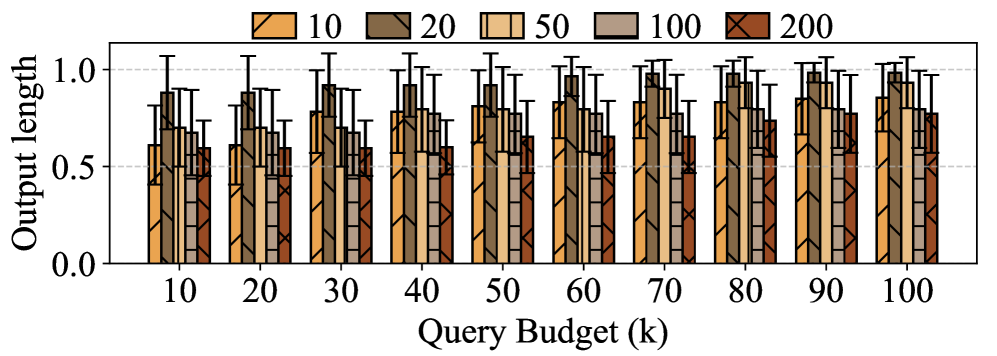
📊 实验亮点
实验结果表明,ThinkTrap攻击能够显著降低商业LLM服务的吞吐量。在请求频率限制为10 RPM的情况下,攻击可以将服务吞吐量降低到原始容量的1%,甚至导致完全的服务故障。这些结果表明,即使在严格的频率限制下,ThinkTrap仍然是一种有效的DoS攻击方法。
🎯 应用场景
ThinkTrap的研究成果可应用于提升LLM云服务的安全性与鲁棒性。通过识别并防御此类攻击,可以保障服务的稳定运行,避免资源被恶意占用,确保正常用户的使用体验。此外,该研究也为开发更安全的LLM输入过滤机制提供了思路,有助于构建更可靠的人工智能系统。
📄 摘要(原文)
Large Language Models (LLMs) have become foundational components in a wide range of applications, including natural language understanding and generation, embodied intelligence, and scientific discovery. As their computational requirements continue to grow, these models are increasingly deployed as cloud-based services, allowing users to access powerful LLMs via the Internet. However, this deployment model introduces a new class of threat: denial-of-service (DoS) attacks via unbounded reasoning, where adversaries craft specially designed inputs that cause the model to enter excessively long or infinite generation loops. These attacks can exhaust backend compute resources, degrading or denying service to legitimate users. To mitigate such risks, many LLM providers adopt a closed-source, black-box setting to obscure model internals. In this paper, we propose ThinkTrap, a novel input-space optimization framework for DoS attacks against LLM services even in black-box environments. The core idea of ThinkTrap is to first map discrete tokens into a continuous embedding space, then undertake efficient black-box optimization in a low-dimensional subspace exploiting input sparsity. The goal of this optimization is to identify adversarial prompts that induce extended or non-terminating generation across several state-of-the-art LLMs, achieving DoS with minimal token overhead. We evaluate the proposed attack across multiple commercial, closed-source LLM services. Our results demonstrate that, even far under the restrictive request frequency limits commonly enforced by these platforms, typically capped at ten requests per minute (10 RPM), the attack can degrade service throughput to as low as 1% of its original capacity, and in some cases, induce complete service failure.