Reformulate, Retrieve, Localize: Agents for Repository-Level Bug Localization
作者: Genevieve Caumartin, Glaucia Melo
分类: cs.SE, cs.AI, cs.IR
发布日期: 2025-12-07
备注: Accepted at BoatSE 2026
💡 一句话要点
提出基于LLM的智能体,通过查询重构提升代码仓库级缺陷定位
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 缺陷定位 信息检索 大型语言模型 查询重构 软件工程
📋 核心要点
- 现有IRBL方法依赖含噪声的缺陷描述,导致检索精度低,难以有效定位大规模代码仓库中的缺陷。
- 利用LLM智能体进行轻量级查询重构和总结,从缺陷报告中提取关键信息,优化检索查询。
- 实验表明,该智能体在首文件检索排名上优于BM25基线35%,文件检索性能超越SWE-agent达22%。
📝 摘要(中文)
缺陷定位在大规模软件仓库中仍然是一项关键但耗时的挑战。传统的基于信息检索的缺陷定位(IRBL)方法依赖于未修改的缺陷描述,这些描述通常包含噪声信息,导致检索准确率较低。最近大型语言模型(LLM)的进展通过查询重构改进了缺陷定位,但对智能体性能的影响仍未被探索。本研究探讨了基于LLM的智能体如何通过轻量级的查询重构和总结来改进文件级别的缺陷定位。我们首先使用开源的、非微调的LLM从缺陷报告中提取关键信息,例如标识符和代码片段,并在检索前重构查询。然后,我们的智能体使用这些预处理的查询来协调BM25检索,从而大规模地自动化定位工作流程。使用性能最佳的查询重构技术,我们的智能体在首个文件检索中的排名比我们的BM25基线提高了35%,并且比SWE-agent的文件检索性能提高了高达+22%。
🔬 方法详解
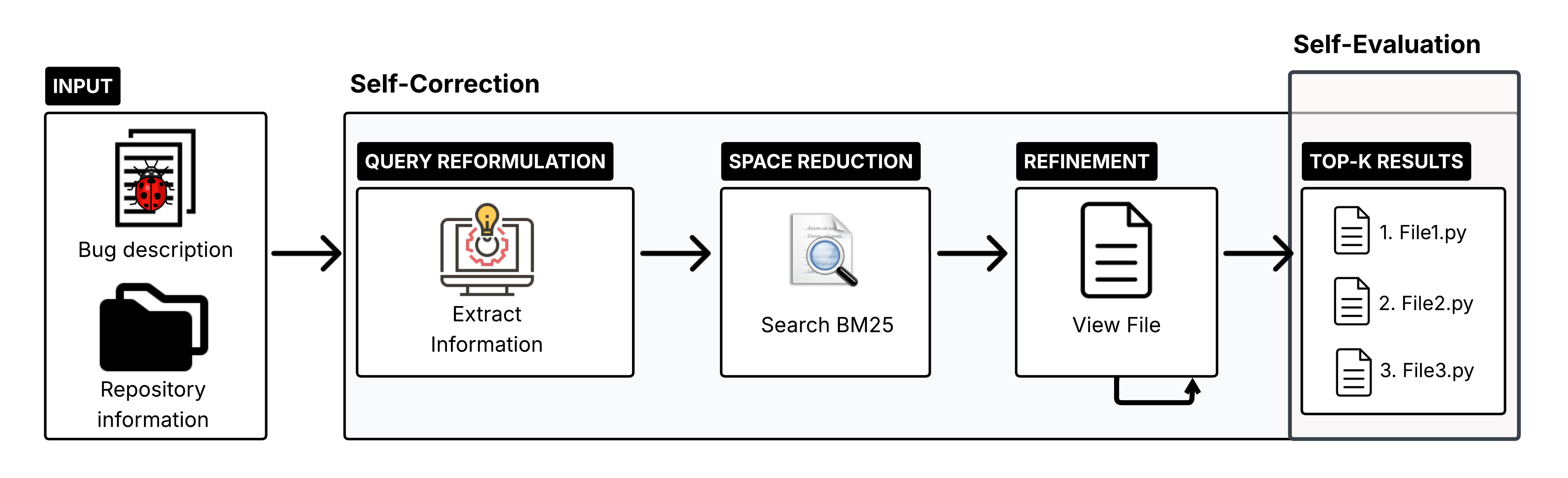
问题定义:论文旨在解决大规模软件仓库中缺陷定位效率低下的问题。现有基于信息检索的缺陷定位方法依赖于原始的缺陷报告,这些报告通常包含大量噪声信息,例如不相关的上下文、拼写错误等,导致检索结果不准确,无法有效定位到包含缺陷的文件。
核心思路:论文的核心思路是利用大型语言模型(LLM)的自然语言理解和生成能力,对原始缺陷报告进行预处理,提取关键信息并重构查询,从而提高检索的准确性和效率。通过智能体自动完成查询重构和检索过程,实现大规模自动化缺陷定位。
技术框架:该方法的核心是一个基于LLM的智能体,其主要流程包括:1) 使用LLM从缺陷报告中提取关键信息,例如标识符、代码片段等;2) 基于提取的信息,使用LLM重构检索查询;3) 使用重构后的查询,通过BM25算法在代码仓库中进行检索,得到候选文件列表;4) 对候选文件进行排序,将最有可能包含缺陷的文件排在前面。
关键创新:该方法的主要创新在于利用LLM进行查询重构,从而有效去除原始缺陷报告中的噪声信息,提高检索的准确性。与传统的IRBL方法相比,该方法不需要人工干预,可以自动完成查询重构和检索过程,从而提高缺陷定位的效率。此外,该方法探索了非微调LLM在缺陷定位任务中的应用,降低了模型训练的成本。
关键设计:论文使用了开源的、非微调的LLM进行查询重构。具体而言,LLM被用于提取缺陷报告中的实体(例如类名、函数名、变量名)和代码片段,并基于这些信息生成更精确的查询。BM25算法被用作检索器,用于在代码仓库中查找与查询相关的文档。实验中,作者比较了不同的查询重构策略,并选择了性能最佳的策略。没有提及具体的损失函数或网络结构,因为使用的是非微调的LLM。
🖼️ 关键图片
📊 实验亮点
实验结果表明,基于LLM的智能体在缺陷定位任务中取得了显著的性能提升。使用最佳查询重构技术,智能体在首个文件检索中的排名比BM25基线提高了35%,并且比SWE-agent的文件检索性能提高了高达+22%。这些结果表明,LLM在缺陷定位任务中具有巨大的潜力,可以有效提高缺陷定位的准确性和效率。
🎯 应用场景
该研究成果可应用于软件开发和维护的各个阶段,帮助开发人员快速定位和修复缺陷,提高软件质量和开发效率。通过自动化缺陷定位流程,可以减少人工干预,降低开发成本。未来,该方法可以扩展到支持更多编程语言和代码仓库,并与其他缺陷管理工具集成,构建更完善的缺陷定位系统。
📄 摘要(原文)
Bug localization remains a critical yet time-consuming challenge in large-scale software repositories. Traditional information retrieval-based bug localization (IRBL) methods rely on unchanged bug descriptions, which often contain noisy information, leading to poor retrieval accuracy. Recent advances in large language models (LLMs) have improved bug localization through query reformulation, yet the effect on agent performance remains unexplored. In this study, we investigate how an LLM-powered agent can improve file-level bug localization via lightweight query reformulation and summarization. We first employ an open-source, non-fine-tuned LLM to extract key information from bug reports, such as identifiers and code snippets, and reformulate queries pre-retrieval. Our agent then orchestrates BM25 retrieval using these preprocessed queries, automating localization workflow at scale. Using the best-performing query reformulation technique, our agent achieves 35% better ranking in first-file retrieval than our BM25 baseline and up to +22% file retrieval performance over SWE-agent.