Latency-Response Theory Model: Evaluating Large Language Models via Response Accuracy and Chain-of-Thought Length
作者: Zhiyu Xu, Jia Liu, Yixin Wang, Yuqi Gu
分类: stat.ME, cs.AI, stat.AP, stat.ML
发布日期: 2025-12-07 (更新: 2025-12-11)
🔗 代码/项目: GITHUB
💡 一句话要点
提出延迟-响应理论模型(LaRT),通过响应准确率和思维链长度评估大语言模型。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型评估 项目反应理论 思维链 潜在变量模型 响应准确率 推理能力 模型排名
📋 核心要点
- 现有LLM评估方法主要依赖响应准确率,忽略了思维链长度这一反映推理能力的重要指标。
- LaRT模型通过联合建模响应准确率和思维链长度,引入潜在能力和潜在速度,更全面地评估LLM。
- 实验表明,LaRT在估计精度、预测能力和排名有效性等方面优于IRT,并揭示了能力与速度的负相关。
📝 摘要(中文)
大型语言模型(LLM)的快速发展需要有效的评估方法,以指导下游应用和未来的改进。项目反应理论(IRT)最近成为一种有前景的框架,通过响应准确率评估LLM。除了简单的响应准确率之外,LLM的思维链(CoT)长度也是其推理能力的重要指标。为了利用CoT长度信息来辅助LLM的评估,我们提出了延迟-响应理论(LaRT),通过引入潜在能力、潜在速度以及它们之间的关键相关参数,联合建模响应准确率和CoT长度。我们推导了一种有效的估计算法,并为总体参数建立了严格的可识别性结果,以确保估计的统计有效性。理论渐近分析和模拟研究表明,LaRT在潜在特征的估计精度和更短的置信区间方面优于IRT。一个关键发现是,只要潜在能力和潜在速度相关,LaRT下潜在能力的渐近估计精度就超过IRT。我们收集了来自不同LLM在流行基准数据集上的真实响应。LaRT的应用揭示了所有基准中潜在能力和潜在速度之间存在很强的负相关关系,对于更困难的基准,相关性更强。这一发现支持了更高的推理能力与更慢的速度和更长的响应延迟相关的直觉。LaRT产生与IRT不同的LLM排名,并且在包括预测能力、项目效率、排名有效性和LLM评估效率在内的多个关键评估指标上优于IRT。代码和数据可在https://github.com/Toby-X/Latency-Response-Theory-Model获得。
🔬 方法详解
问题定义:现有的大语言模型评估方法,如基于Item Response Theory (IRT) 的方法,主要关注模型的回答准确率。然而,模型的思维链(Chain-of-Thought, CoT)长度,即模型生成答案时所进行的推理步骤,也是衡量模型推理能力的重要指标。忽略CoT长度可能导致对模型能力的片面评估。
核心思路:LaRT的核心思路是将模型的响应准确率和CoT长度联合建模,认为这两个指标都受到潜在能力和潜在速度的影响。通过引入潜在变量,LaRT能够更全面地刻画模型的推理过程,并揭示能力和速度之间的关系。这种联合建模的方式能够提供更准确的模型评估结果。
技术框架:LaRT模型包含以下几个关键部分:1) 潜在能力:表示模型解决问题的潜在能力;2) 潜在速度:表示模型生成答案的速度;3) 响应准确率模型:将响应准确率与潜在能力和潜在速度关联;4) CoT长度模型:将CoT长度与潜在能力和潜在速度关联;5) 参数估计:使用有效的算法估计模型参数,包括潜在能力、潜在速度以及它们之间的相关性。整体流程是先收集LLM在benchmark上的响应数据(包括答案和CoT长度),然后使用LaRT模型进行参数估计,最后基于估计结果进行LLM的评估和排名。
关键创新:LaRT最重要的创新在于将响应准确率和CoT长度联合建模,并引入了潜在能力和潜在速度这两个潜在变量。与传统的IRT方法相比,LaRT能够更全面地刻画模型的推理过程,并揭示能力和速度之间的关系。此外,LaRT还提出了有效的参数估计算法,并证明了模型的可识别性,保证了估计结果的统计有效性。
关键设计:LaRT的关键设计包括:1) 响应准确率模型:可以使用logistic回归模型或其它适合二分类问题的模型;2) CoT长度模型:可以使用泊松回归模型或其它适合计数数据的模型;3) 潜在变量相关性:使用相关系数来刻画潜在能力和潜在速度之间的关系;4) 参数估计算法:可以使用期望最大化(EM)算法或其它优化算法来估计模型参数。损失函数的设计需要考虑响应准确率和CoT长度的似然函数,并加入正则化项以防止过拟合。
🖼️ 关键图片
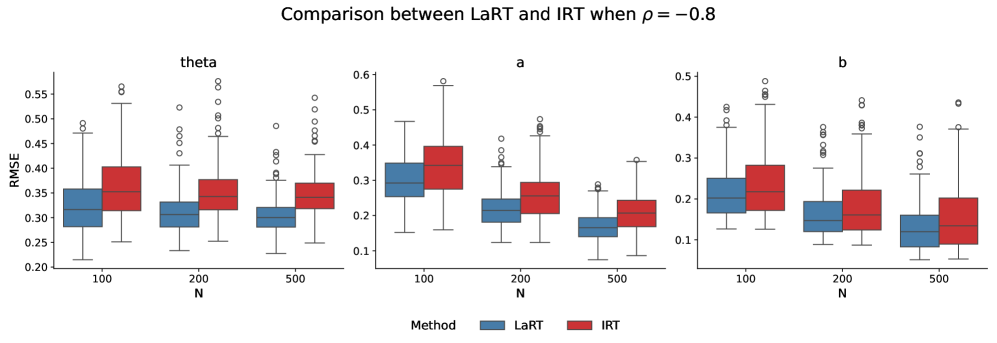
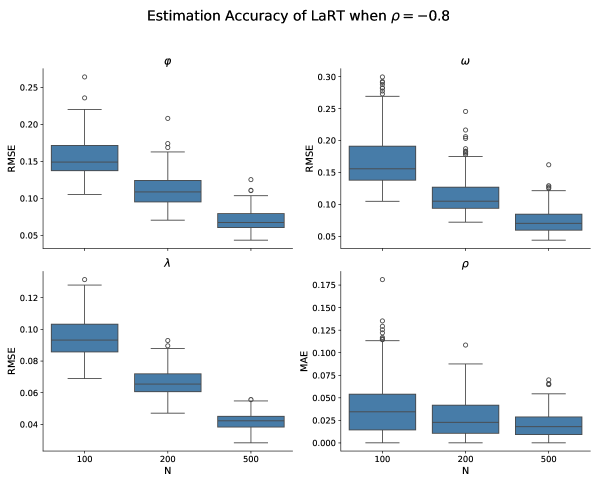
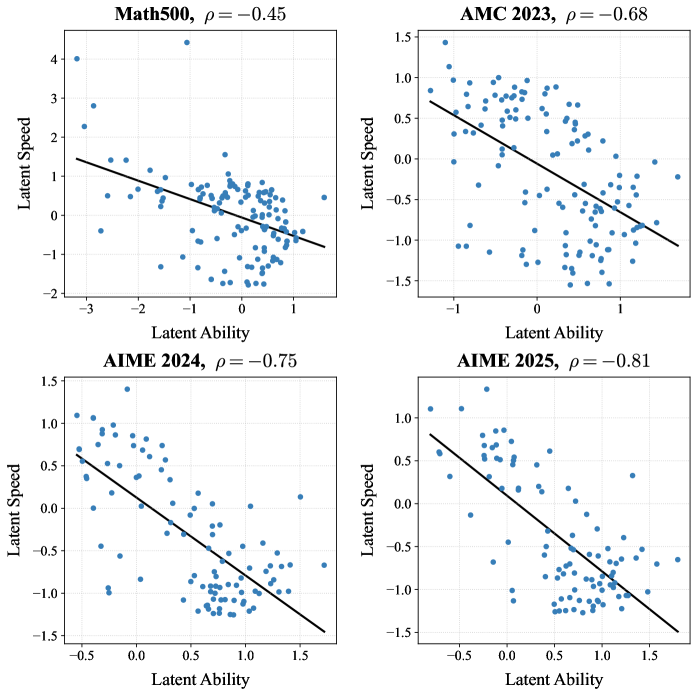
📊 实验亮点
实验结果表明,LaRT在多个关键评估指标上优于IRT,包括预测能力、项目效率和排名有效性。LaRT揭示了潜在能力和潜在速度之间存在强烈的负相关关系,尤其是在更困难的基准测试中。此外,LaRT对LLM的排名与IRT不同,表明LaRT能够提供更细致和准确的评估结果。
🎯 应用场景
LaRT模型可应用于大语言模型的全面评估与选型,帮助用户根据实际需求选择合适的模型。通过分析潜在能力和速度的相关性,可以指导模型优化,例如在保证能力的前提下提升速度。此外,LaRT还可用于分析不同benchmark的难度,为构建更有效的评估数据集提供依据。
📄 摘要(原文)
The proliferation of Large Language Models (LLMs) necessitates valid evaluation methods to guide downstream applications and actionable future improvements. The Item Response Theory (IRT) has recently emerged as a promising framework for evaluating LLMs via their response accuracy. Beyond simple response accuracy, LLMs' chain of thought (CoT) lengths serve as a vital indicator of their reasoning ability. To leverage the CoT length information to assist the evaluation of LLMs, we propose Latency-Response Theory (LaRT) to jointly model the response accuracy and CoT length by introducing the latent ability, latent speed, and a key correlation parameter between them. We derive an efficient estimation algorithm and establish rigorous identifiability results for the population parameters to ensure the statistical validity of estimation. Theoretical asymptotic analyses and simulation studies demonstrate LaRT's advantages over IRT in terms of higher estimation accuracy and shorter confidence intervals for latent traits. A key finding is that the asymptotic estimation precision of the latent ability under LaRT exceeds that of IRT whenever the latent ability and latent speed are correlated. We collect real responses from diverse LLMs on popular benchmark datasets. The application of LaRT reveals a strong negative correlation between the latent ability and latent speed in all benchmarks, with stronger correlation for more difficult benchmarks. This finding supports the intuition that higher reasoning ability correlates with slower speed and longer response latency. LaRT yields different LLM rankings than IRT and outperforms IRT across multiple key evaluation metrics including predictive power, item efficiency, ranking validity, and LLM evaluation efficiency. Code and data are available at https://github.com/Toby-X/Latency-Response-Theory-Model.