Singing Timbre Popularity Assessment Based on Multimodal Large Foundation Model
作者: Zihao Wang, Ruibin Yuan, Ziqi Geng, Hengjia Li, Xingwei Qu, Xinyi Li, Songye Chen, Haoying Fu, Roger B. Dannenberg, Kejun Zhang
分类: cs.SD, cs.AI
发布日期: 2025-12-07
备注: Accepted to ACMMM 2025 oral
期刊: Proceedings of the 33rd ACM International Conference on Multimedia (ACMMM 2025), Pages 12227-12236
💡 一句话要点
提出VocalVerse,基于多模态大模型进行无参考、多维度的歌唱音色流行度评估。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 歌唱评估 多模态大模型 无参考评估 音色质量 情感表达
📋 核心要点
- 现有歌唱评估系统依赖参考音轨,限制了创造性表达,且评估维度单一,无法诊断复杂演唱表现。
- 论文提出VocalVerse,利用轻量级声学编码器建模全局特征,克服MLLM内存限制,实现无参考、多维度评估。
- 构建Sing-MD数据集和H-TPR基准,揭示专家标注不一致性,并评估模型生成感知有效排序的能力。
📝 摘要(中文)
本文旨在解决现有歌唱评估系统依赖参考音轨和简化复杂演唱表现的问题,提出了一种无参考、多维度的评估体系。首先,构建了大规模数据集Sing-MD,由专家标注了气息控制、音色质量、情感表达和演唱技巧四个维度。分析发现专家间存在显著标注不一致,挑战了传统基于准确率的指标的有效性。其次,针对多模态大语言模型(MLLM)分析完整歌曲时存在的内存限制,提出了高效的混合架构VocalVerse,利用轻量级声学编码器建模全局表现特征和长期依赖关系。最后,为了解决自动评估指标的不足,建立了H-TPR(人机协同分层感知排序)基准,评估模型生成感知有效排序的能力,而非预测有噪声的真实分数。
🔬 方法详解
问题定义:现有歌唱评估系统主要存在两个痛点:一是依赖参考音轨,扼杀了创造性表达;二是将复杂的演唱表现简化为基于音高和节奏的非诊断性评分。这使得系统无法全面评估演唱的质量,也难以提供有针对性的改进建议。
核心思路:论文的核心思路是从判别式评估转向描述式评估,构建一个完整的、无参考的、多维度的评估体系。通过引入多个维度(气息控制、音色质量、情感表达、演唱技巧)的评估,并利用大模型学习这些维度之间的复杂关系,从而更全面地理解和评估演唱表现。
技术框架:VocalVerse是一个混合架构,主要包含以下模块:1) 轻量级声学编码器:用于提取歌曲的全局特征和长期依赖关系,克服MLLM的内存限制。2) 多模态大语言模型(MLLM):用于学习声学特征和文本描述之间的关系,并生成多维度的评估结果。3) H-TPR基准:用于评估模型生成感知有效排序的能力,而非预测有噪声的真实分数。整体流程是,首先使用声学编码器提取歌曲特征,然后将特征输入MLLM进行评估,最后使用H-TPR基准评估模型性能。
关键创新:最重要的技术创新点在于VocalVerse的混合架构,它有效地解决了MLLM在处理长音频时遇到的内存限制问题。通过使用轻量级的声学编码器,VocalVerse可以在不损失过多信息的情况下,将长音频压缩成更易于处理的特征向量,从而使MLLM能够更好地理解和评估歌曲的整体表现。
关键设计:论文的关键设计包括:1) Sing-MD数据集的构建,提供了多维度标注的歌唱数据;2) 轻量级声学编码器的选择和训练,保证了特征提取的效率和准确性;3) H-TPR基准的建立,提供了一种更符合人类感知的评估方法。具体的参数设置、损失函数和网络结构等细节在论文中有更详细的描述,但摘要中未明确提及。
🖼️ 关键图片
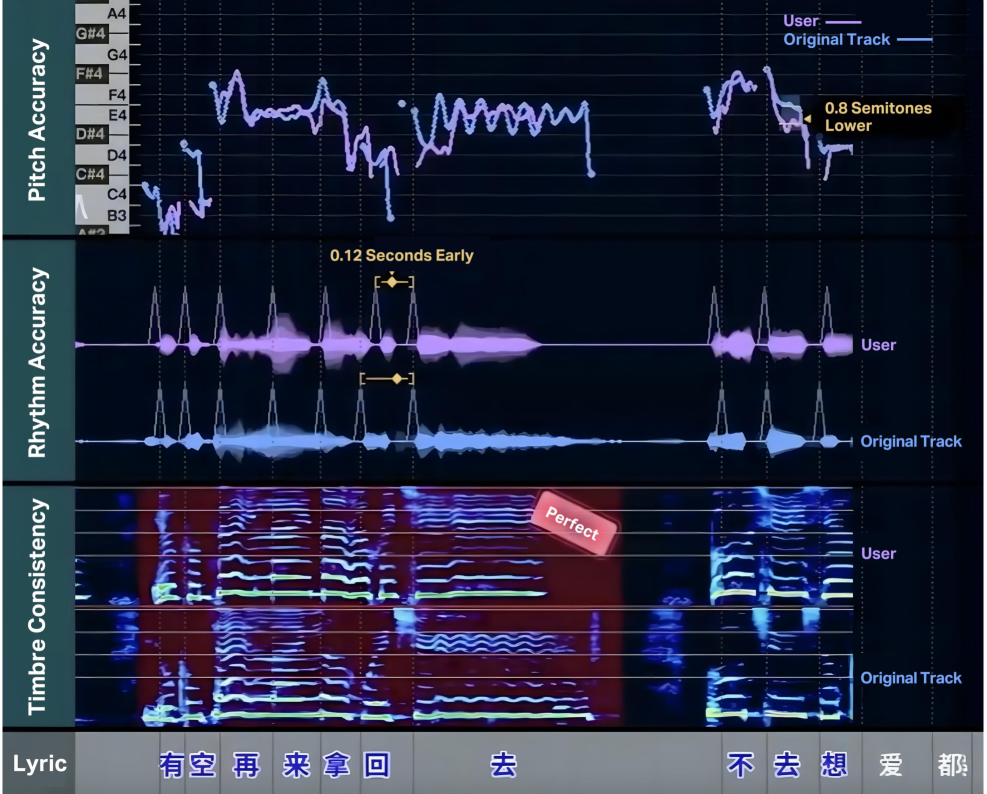
📊 实验亮点
论文构建了Sing-MD数据集,揭示了专家标注的不一致性,挑战了传统评估指标。提出的VocalVerse模型通过H-TPR基准评估,验证了其生成感知有效排序的能力,相较于传统方法,在无参考歌唱评估方面取得了显著进展。具体的性能数据和提升幅度在摘要中未明确提及,需要查阅原文。
🎯 应用场景
该研究成果可应用于在线K歌平台、声乐教育App等领域,为用户提供个性化的歌唱评估和反馈,辅助声乐学习者提高演唱水平。同时,该技术也可用于音乐创作和歌曲推荐,提升音乐产业的智能化水平,具有广阔的应用前景。
📄 摘要(原文)
Automated singing assessment is crucial for education and entertainment. However, existing systems face two fundamental limitations: reliance on reference tracks, which stifles creative expression, and the simplification of complex performances into non-diagnostic scores based solely on pitch and rhythm. We advocate for a shift from discriminative to descriptive evaluation, creating a complete ecosystem for reference-free, multi-dimensional assessment. First, we introduce Sing-MD, a large-scale dataset annotated by experts across four dimensions: breath control, timbre quality, emotional expression, and vocal technique. Our analysis reveals significant annotation inconsistencies among experts, challenging the validity of traditional accuracy-based metrics. Second, addressing the memory limitations of Multimodal Large Language Models (MLLMs) in analyzing full-length songs, we propose VocalVerse. This efficient hybrid architecture leverages a lightweight acoustic encoder to model global performance features and long-term dependencies. Third, to address automated metric shortcomings, we establish the H-TPR (Human-in-the-loop Tiered Perceptual Ranking) benchmark, which evaluates a model's ability to generate perceptually valid rankings rather than predicting noisy ground-truth scores.