SoK: Trust-Authorization Mismatch in LLM Agent Interactions
作者: Guanquan Shi, Haohua Du, Zhiqiang Wang, Xiaoyu Liang, Weiwenpei Liu, Song Bian, Zhenyu Guan
分类: cs.CR, cs.AI
发布日期: 2025-12-07
💡 一句话要点
构建LLM Agent交互安全框架,揭示信任-授权不匹配问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM Agent 安全 信任 授权 风险分析 人工智能安全 交互安全
📋 核心要点
- 现有LLM Agent交互面临信任评估与授权策略不匹配的安全挑战,传统安全机制难以应对。
- 论文提出基于信任-授权差距的风险分析模型,统一分析现有攻击与防御方法。
- 该框架识别了关键研究差距,并为构建可信Agent和动态授权机制提供了系统性研究方向。
📝 摘要(中文)
大型语言模型(LLM)正迅速发展为能够与外部世界交互的自主Agent,通过标准化交互协议显著扩展其能力。然而,这种模式在新的、不稳定的环境中重新引发了机构和授权方面的经典网络安全挑战。随着决策从确定性代码逻辑转变为由自然语言驱动的概率推理,为确定性行为设计的传统安全机制失效。为不可预测的AI Agent建立信任并在指令模糊时强制执行最小权限原则(PoLP)具有根本性的挑战。尽管威胁形势日益严峻,但学术界对这一新兴领域的理解仍然是分散的,缺乏一个系统的框架来分析其根本原因。本文为Agent交互安全提供了一个统一的形式视角。我们观察到,该领域的大多数安全威胁源于信任评估和授权策略之间的根本不匹配。我们引入了一个以这种信任-授权差距为中心的新型风险分析模型。使用该模型作为一个统一的视角,我们调查和分类了现有攻击和防御的实现路径,这些攻击和防御通常看起来是孤立的。这个新的框架不仅统一了该领域,而且使我们能够识别关键的研究差距。最后,我们利用我们的分析,提出了一个系统的研究方向,以构建健壮、可信的Agent和动态授权机制。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)驱动的Agent在与外部环境交互时面临的安全问题。现有的安全机制主要针对确定性代码逻辑,无法有效应对LLM Agent基于自然语言的概率推理和决策过程。这导致了信任评估和授权策略之间的不匹配,使得Agent可能执行超出其权限范围的操作,从而引发安全风险。现有方法缺乏对这些风险的系统性分析和统一的防御框架。
核心思路:论文的核心思路是识别并形式化描述LLM Agent交互中的信任-授权不匹配问题。通过建立一个以信任-授权差距为中心的风险分析模型,论文能够将各种看似孤立的攻击和防御方法纳入一个统一的框架下进行分析。这种统一的视角有助于理解问题的本质,并为未来的研究提供指导。
技术框架:论文构建的风险分析模型主要包含以下几个阶段:1) 识别Agent交互中的潜在风险;2) 分析信任评估过程,确定Agent的信任等级;3) 分析授权策略,确定Agent被允许执行的操作;4) 比较信任等级和授权范围,识别信任-授权差距;5) 基于差距分析,提出相应的安全措施。
关键创新:论文最重要的技术创新在于提出了一个统一的框架来分析LLM Agent交互中的安全问题。该框架通过形式化描述信任-授权不匹配问题,将各种攻击和防御方法联系起来,从而提供了一个更全面和深入的理解。此外,该框架还能够识别当前研究的不足之处,并为未来的研究方向提供指导。
关键设计:论文的关键设计在于信任-授权差距的量化方法。具体如何量化信任等级和授权范围,以及如何定义和计算信任-授权差距,论文中可能没有详细展开,属于未来研究的方向。此外,如何根据差距分析结果,动态调整授权策略,也是一个重要的技术细节。
🖼️ 关键图片

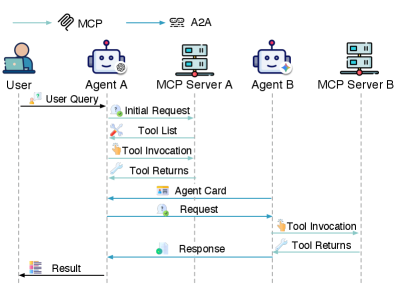
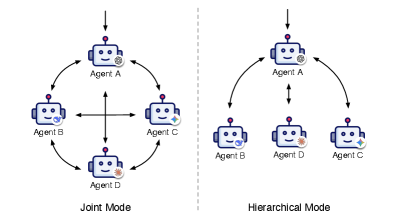
📊 实验亮点
论文的主要贡献在于提出了一个统一的风险分析模型,用于分析LLM Agent交互中的安全问题。该模型能够识别信任-授权差距,并为构建更安全的Agent提供指导。虽然论文没有提供具体的性能数据或对比基线,但其提出的框架为未来的研究奠定了基础,并有望推动AI安全领域的发展。
🎯 应用场景
该研究成果可应用于构建更安全可靠的LLM Agent,例如智能助手、自动化客服、智能家居控制等。通过动态调整Agent的权限,可以有效防止恶意攻击和数据泄露,提升用户信任度。未来,该研究有望推动AI安全领域的发展,为构建可信赖的人工智能系统奠定基础。
📄 摘要(原文)
Large Language Models (LLMs) are rapidly evolving into autonomous agents capable of interacting with the external world, significantly expanding their capabilities through standardized interaction protocols. However, this paradigm revives the classic cybersecurity challenges of agency and authorization in a novel and volatile context. As decision-making shifts from deterministic code logic to probabilistic inference driven by natural language, traditional security mechanisms designed for deterministic behavior fail. It is fundamentally challenging to establish trust for unpredictable AI agents and to enforce the Principle of Least Privilege (PoLP) when instructions are ambiguous. Despite the escalating threat landscape, the academic community's understanding of this emerging domain remains fragmented, lacking a systematic framework to analyze its root causes. This paper provides a unifying formal lens for agent-interaction security. We observed that most security threats in this domain stem from a fundamental mismatch between trust evaluation and authorization policies. We introduce a novel risk analysis model centered on this trust-authorization gap. Using this model as a unifying lens, we survey and classify the implementation paths of existing, often seemingly isolated, attacks and defenses. This new framework not only unifies the field but also allows us to identify critical research gaps. Finally, we leverage our analysis to suggest a systematic research direction toward building robust, trusted agents and dynamic authorization mechanisms.