Decouple to Generalize: Context-First Self-Evolving Learning for Data-Scarce Vision-Language Reasoning
作者: Tingyu Li, Zheng Sun, Jingxuan Wei, Siyuan Li, Conghui He, Lijun Wu, Cheng Tan
分类: cs.AI
发布日期: 2025-12-07
备注: 25 pages, 5 figures
💡 一句话要点
提出DoGe框架,通过解耦学习上下文和问题求解,提升数据稀缺场景下VLM的泛化能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 强化学习 数据稀缺 上下文学习 解耦学习 自进化学习 课程学习 多模态推理
📋 核心要点
- 现有VLM在数据稀缺领域利用强化学习自进化时,面临数据不足、奖励机制易被利用等问题。
- DoGe框架通过解耦上下文学习和问题求解,并设计双阶段强化学习,提升模型泛化能力。
- 实验表明,DoGe在多个基准测试中超越现有方法,为自进化LVLM提供可行方案。
📝 摘要(中文)
本文提出DoGe(Decouple to Generalize)框架,旨在解决视觉-语言模型(VLM)在数据稀缺领域,如化学、地球科学和多模态数学等,利用强化学习(RL)进行自进化学习时遇到的问题。现有方法依赖合成数据和自奖励机制,但存在分布受限和对齐困难,导致模型利用高奖励模式,降低策略熵并破坏训练稳定性。DoGe通过双重解耦,引导模型首先学习上下文,关注合成数据方法忽略的问题背景。该框架将学习过程解耦为“思考者”和“解决者”两个组件,合理量化奖励信号,并提出一个两阶段RL后训练方法,从自由探索上下文到实际解决任务。此外,DoGe构建了一个演进的课程学习流程,包含扩展的领域知识语料库和迭代演进的种子问题池,以增加训练数据的多样性。实验结果表明,该方法在多个基准测试中始终优于基线方法,为实现自进化LVLM提供了一条可扩展的途径。
🔬 方法详解
问题定义:现有视觉-语言模型(VLM)在数据稀缺的专业领域,如化学、地球科学和多模态数学等,利用强化学习进行自进化学习时,面临着数据量不足和数据质量不高的问题。现有的合成数据和自奖励机制存在分布受限和对齐困难,导致模型容易学习到虚假的关联性,即reward hacking,从而降低策略的多样性,影响模型的泛化能力,最终导致训练不稳定。
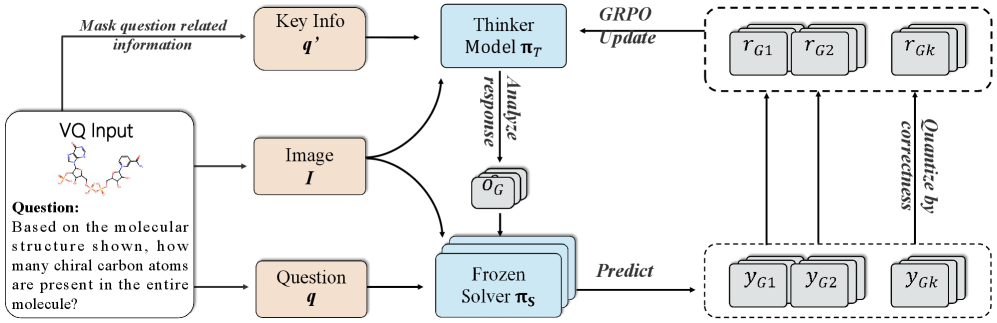
核心思路:DoGe的核心思路是将学习过程解耦为两个阶段:首先让模型学习理解问题的上下文信息,然后再进行问题求解。通过这种方式,模型可以更好地理解问题的本质,从而避免过度依赖表面的模式。此外,DoGe还通过构建演进的课程学习流程来增加训练数据的多样性,从而进一步提高模型的泛化能力。
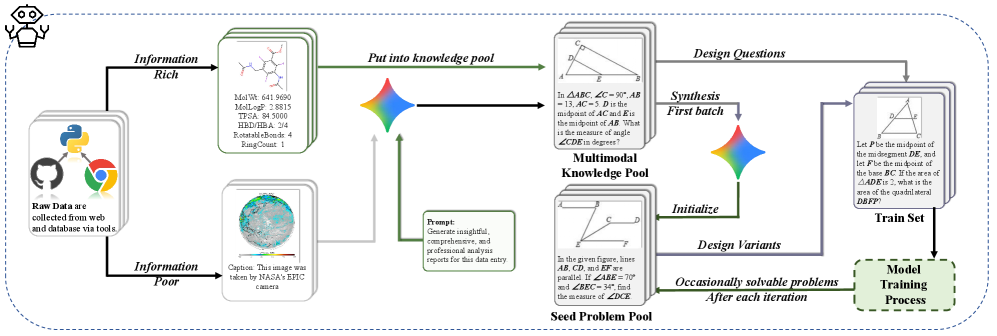
技术框架:DoGe框架包含两个主要组件:“思考者”(Thinker)和“解决者”(Solver)。“思考者”负责学习和理解问题的上下文信息,而“解决者”则负责根据上下文信息解决问题。框架采用两阶段强化学习后训练方法。第一阶段,模型自由探索上下文,学习理解问题背景;第二阶段,模型在理解上下文的基础上,实际解决任务。此外,DoGe还包含一个演进的课程学习流程,用于生成多样化的训练数据。该流程包括一个扩展的领域知识语料库和一个迭代演进的种子问题池。
关键创新:DoGe的关键创新在于双重解耦:一是将学习过程解耦为上下文学习和问题求解两个阶段;二是将模型解耦为“思考者”和“解决者”两个组件。这种解耦方式使得模型可以更好地理解问题的本质,从而避免过度依赖表面的模式。与现有方法相比,DoGe更加注重对问题上下文的学习,从而提高了模型的泛化能力。
关键设计:DoGe的关键设计包括:1) 双阶段强化学习的奖励函数设计,需要合理量化上下文理解和问题求解的奖励信号;2) 演进的课程学习流程,需要设计有效的策略来扩展领域知识语料库和迭代演进种子问题池,以保证训练数据的多样性和质量;3) “思考者”和“解决者”的网络结构设计,需要根据具体的任务选择合适的网络结构,并进行有效的训练。
🖼️ 关键图片

📊 实验亮点
实验结果表明,DoGe框架在多个基准测试中始终优于基线方法,证明了其有效性。具体的性能数据和提升幅度在论文中进行了详细的展示。该方法为解决数据稀缺场景下VLM的泛化问题提供了一个可行的解决方案,并为实现自进化LVLM提供了一条可扩展的途径。
🎯 应用场景
DoGe框架可应用于各种数据稀缺的视觉-语言推理任务,例如化学、地球科学、多模态数学等专业领域。该研究有助于提升VLM在这些领域的应用效果,例如智能化学实验设计、地球科学数据分析、数学问题自动求解等,具有重要的实际应用价值和学术研究意义,并为构建更强大的自进化LVLM奠定基础。
📄 摘要(原文)
Recent vision-language models (VLMs) achieve remarkable reasoning through reinforcement learning (RL), which provides a feasible solution for realizing continuous self-evolving large vision-language models (LVLMs) in the era of experience. However, RL for VLMs requires abundant high-quality multimodal data, especially challenging in specialized domains like chemistry, earth sciences, and multimodal mathematics. Existing strategies such as synthetic data and self-rewarding mechanisms suffer from limited distributions and alignment difficulties, ultimately causing reward hacking: models exploit high-reward patterns, collapsing policy entropy and destabilizing training. We propose DoGe (Decouple to Generalize), a dual-decoupling framework that guides models to first learn from context rather than problem solving by refocusing on the problem context scenarios overlooked by synthetic data methods. By decoupling learning process into dual components (Thinker and Solver), we reasonably quantify the reward signals of this process and propose a two-stage RL post-training approach from freely exploring context to practically solving tasks. Second, to increase the diversity of training data, DoGe constructs an evolving curriculum learning pipeline: an expanded native domain knowledge corpus and an iteratively evolving seed problems pool. Experiments show that our method consistently outperforms the baseline across various benchmarks, providing a scalable pathway for realizing self-evolving LVLMs.