From Description to Score: Can LLMs Quantify Vulnerabilities?
作者: Sima Jafarikhah, Daniel Thompson, Eva Deans, Hossein Siadati, Yi Liu
分类: cs.CR, cs.AI, cs.PL
发布日期: 2025-12-07 (更新: 2026-01-05)
备注: 10 pages
💡 一句话要点
利用大型语言模型量化漏洞:从描述到CVSS评分的自动化
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 漏洞评分 CVSS 自动化 自然语言处理
📋 核心要点
- 现有漏洞评分流程依赖人工,耗时且易受主观因素影响,存在大量CVE积压。
- 论文探索利用大型语言模型直接从CVE描述中预测CVSS评分,实现自动化评估。
- 实验表明LLM在部分CVSS指标上表现优异,但整体性能受限于CVE描述的质量。
📝 摘要(中文)
手动漏洞评分,例如分配通用漏洞评分系统(CVSS)分数,是一个资源密集型的过程,并且常常受到主观解释的影响。本研究调查了通用大型语言模型(LLM),即ChatGPT、Llama、Grok、DeepSeek和Gemini,通过分析超过31000个最新的通用漏洞披露(CVE)条目来自动化此过程的潜力。结果表明,LLM在某些指标(例如,可用性影响)上明显优于基线,而在其他指标(例如,攻击复杂性)上提供的改进较为适度。此外,模型性能在LLM系列和单个CVSS指标之间都存在差异,其中ChatGPT-5获得了最高的精度。我们的分析表明,LLM倾向于错误分类许多相同的CVE,并且基于集成的元分类器仅略微提高了性能。进一步的检查表明,CVE描述通常缺乏关键上下文或包含模棱两可的措辞,这导致了系统性的错误分类。这些发现强调了增强漏洞描述和整合更丰富的上下文细节的重要性,以支持更可靠的自动化推理,并缓解大量待处理的CVE积压。
🔬 方法详解
问题定义:论文旨在解决漏洞评分过程中人工参与度高、效率低下的问题。现有方法依赖安全专家手动分析CVE描述并分配CVSS评分,这不仅耗费大量时间和资源,而且容易受到主观因素的影响,导致评分不一致。大量的CVE积压进一步加剧了这一问题。
核心思路:论文的核心思路是利用大型语言模型(LLM)的自然语言理解和推理能力,直接从CVE的文本描述中预测其CVSS评分。通过将漏洞描述作为输入,LLM能够学习漏洞的特征与CVSS评分之间的关系,从而实现自动化的漏洞评分。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 数据收集:收集包含CVE描述和对应CVSS评分的大规模数据集。2) 模型选择:选择一系列具有代表性的LLM,包括ChatGPT、Llama、Grok、DeepSeek和Gemini。3) 模型训练/微调:使用CVE数据集对LLM进行训练或微调,使其能够学习从漏洞描述到CVSS评分的映射关系。4) 性能评估:使用一系列指标(如精度、召回率、F1值等)评估LLM在不同CVSS指标上的性能。5) 错误分析:分析LLM的错误分类案例,找出导致错误的原因。6) 集成学习:尝试使用集成学习方法,将多个LLM的预测结果进行融合,以提高整体性能。
关键创新:该研究的关键创新在于探索了利用通用LLM直接进行漏洞评分的可能性,并对不同LLM在这一任务上的性能进行了全面评估。与传统的漏洞分析方法相比,该方法无需人工特征工程,能够自动从文本描述中提取漏洞特征,从而大大提高了效率。
关键设计:论文的关键设计包括:1) 选择了多个具有代表性的LLM,以评估不同模型的性能差异。2) 针对不同的CVSS指标,分别评估LLM的性能,以了解LLM在不同方面的优势和不足。3) 进行了详细的错误分析,以找出导致错误的原因,并为未来的研究提供指导。4) 尝试使用集成学习方法,以提高整体性能。具体参数设置和损失函数等细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片
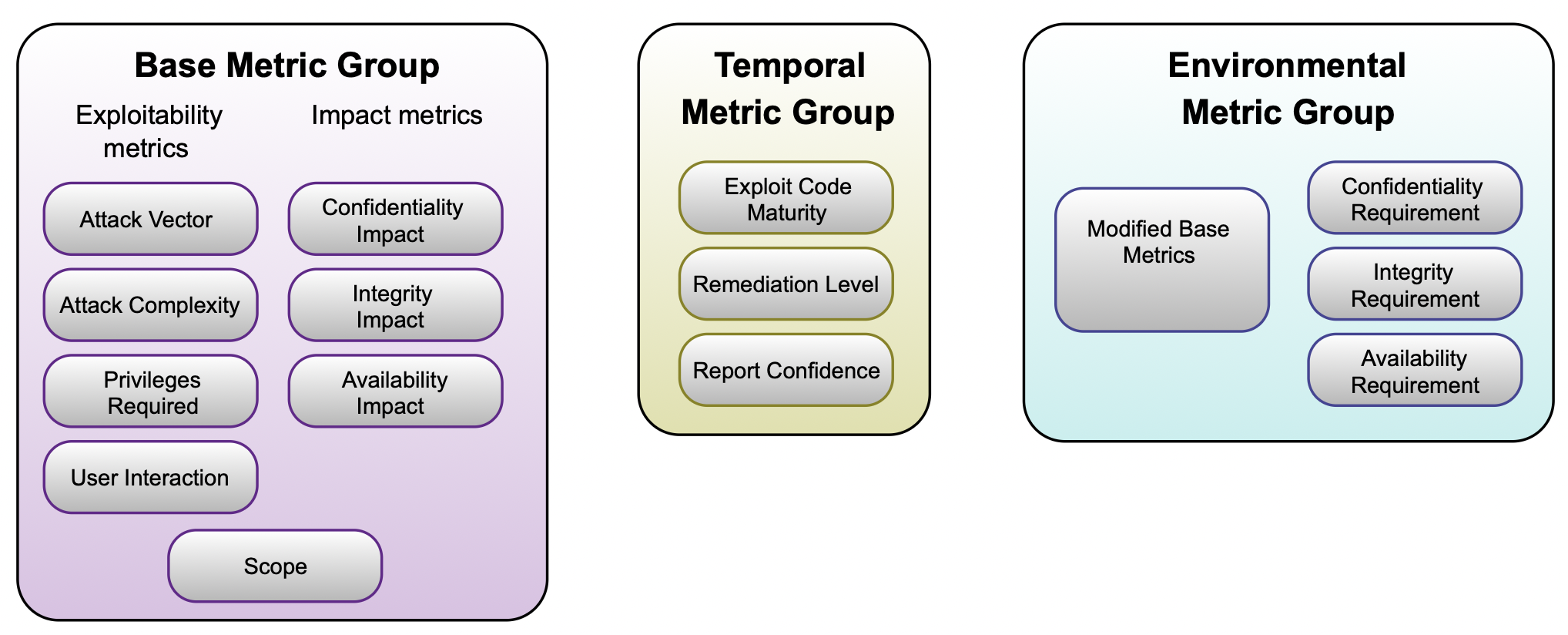
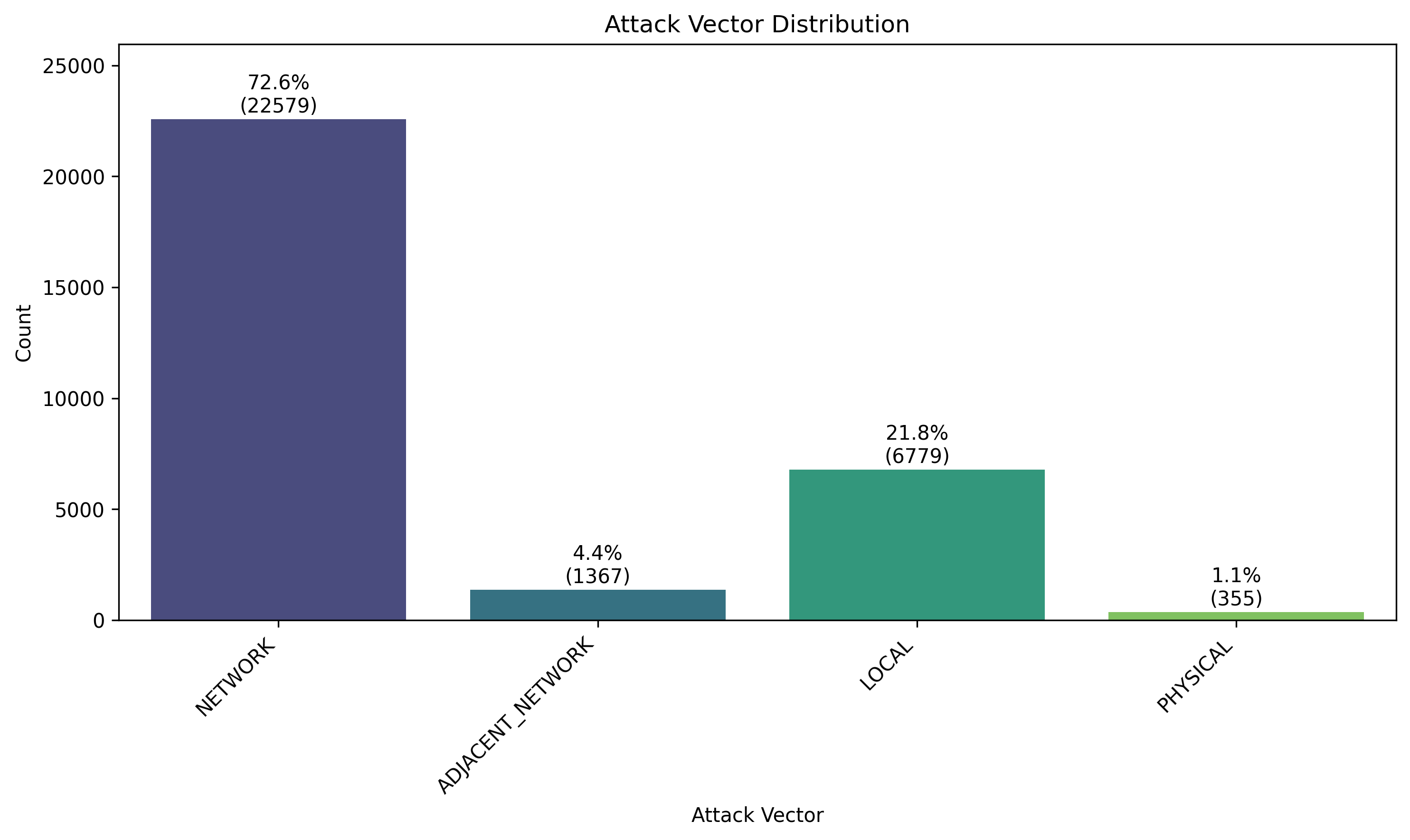
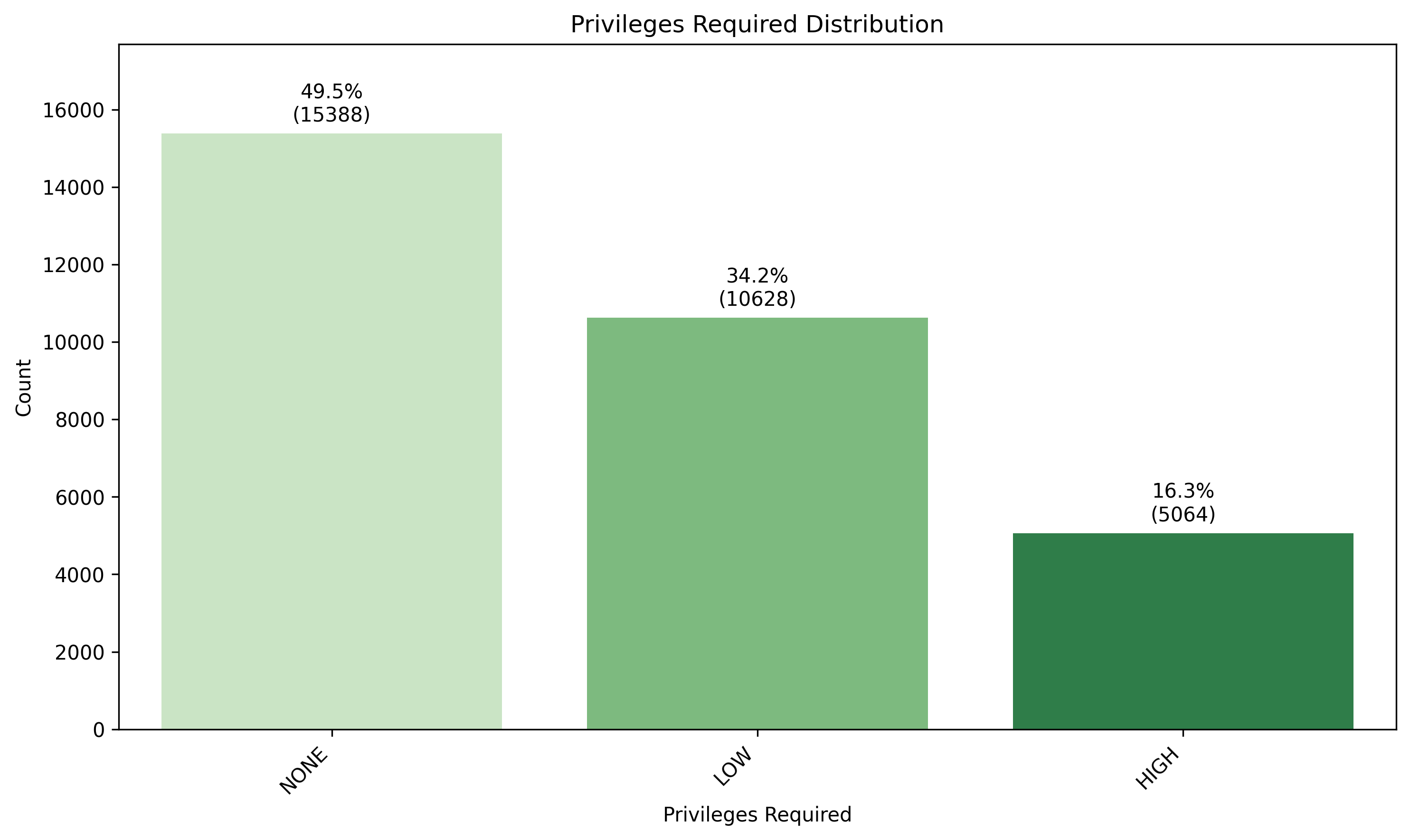
📊 实验亮点
实验结果表明,LLM在某些CVSS指标(如可用性影响)上明显优于基线方法。ChatGPT-5在精度方面表现最佳。然而,LLM在攻击复杂性等指标上的提升较为有限。分析发现,LLM倾向于对相同的CVE进行错误分类,且集成学习方法对性能的提升并不显著。这些结果表明,CVE描述的质量是影响LLM性能的关键因素。
🎯 应用场景
该研究成果可应用于自动化漏洞管理、安全事件响应和威胁情报分析等领域。通过自动化的CVSS评分,安全团队可以更快速地识别和修复高危漏洞,提高安全防护效率。此外,该技术还可以用于构建智能化的漏洞数据库,为安全研究人员提供更便捷的漏洞信息检索和分析工具。
📄 摘要(原文)
Manual vulnerability scoring, such as assigning Common Vulnerability Scoring System (CVSS) scores, is a resource-intensive process that is often influenced by subjective interpretation. This study investigates the potential of general-purpose large language models (LLMs), namely ChatGPT, Llama, Grok, DeepSeek, and Gemini, to automate this process by analyzing over 31{,}000 recent Common Vulnerabilities and Exposures (CVE) entries. The results show that LLMs substantially outperform the baseline on certain metrics (e.g., \textit{Availability Impact}), while offering more modest gains on others (e.g., \textit{Attack Complexity}). Moreover, model performance varies across both LLM families and individual CVSS metrics, with ChatGPT-5 attaining the highest precision. Our analysis reveals that LLMs tend to misclassify many of the same CVEs, and ensemble-based meta-classifiers only marginally improve performance. Further examination shows that CVE descriptions often lack critical context or contain ambiguous phrasing, which contributes to systematic misclassifications. These findings underscore the importance of enhancing vulnerability descriptions and incorporating richer contextual details to support more reliable automated reasoning and alleviate the growing backlog of CVEs awaiting triage.