DoVer: Intervention-Driven Auto Debugging for LLM Multi-Agent Systems
作者: Ming Ma, Jue Zhang, Fangkai Yang, Yu Kang, Qingwei Lin, Saravan Rajmohan, Dongmei Zhang
分类: cs.AI, cs.SE
发布日期: 2025-12-07 (更新: 2026-01-31)
💡 一句话要点
DoVer:基于干预的LLM多智能体系统自动调试框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多智能体系统 大型语言模型 自动调试 干预驱动 故障定位
📋 核心要点
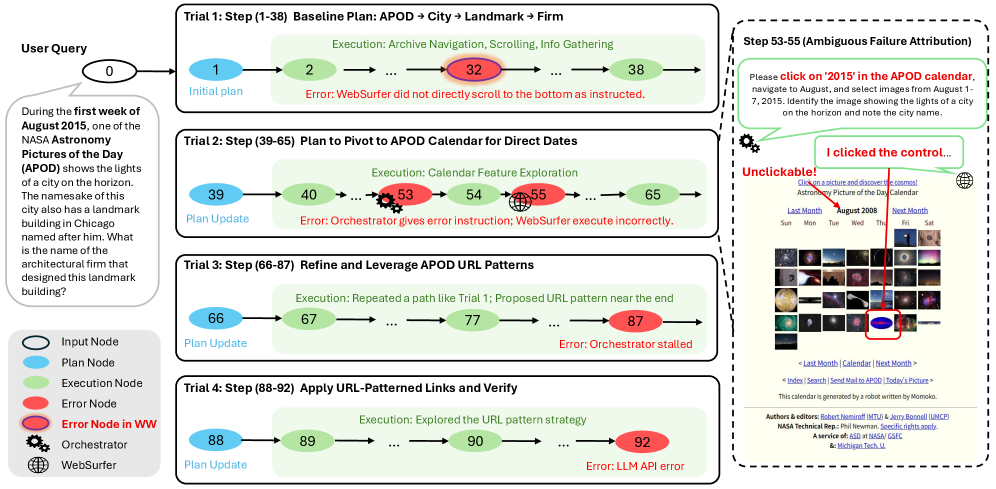
- 现有LLM多智能体系统调试依赖日志分析,缺乏验证,且单点归因难以定位根本原因。
- DoVer通过主动干预(如消息编辑、计划调整)验证调试假设,并关注任务结果而非归因准确性。
- 实验表明,DoVer能显著提升任务成功率和里程碑进展,并在不同数据集和框架上有效。
📝 摘要(中文)
基于大型语言模型(LLM)的多智能体系统调试极具挑战,因为失败通常源于漫长且分支众多的交互轨迹。目前主流做法是利用LLM进行基于日志的故障定位,将错误归因于特定智能体和步骤。然而,这种范式存在两个关键限制:(i)仅基于日志的调试缺乏验证,产生未经测试的假设;(ii)单步或单智能体归因通常是不适定的,因为我们发现多个不同的干预措施可以独立地修复失败的任务。为了解决第一个限制,我们引入了DoVer,一个干预驱动的调试框架,它通过有针对性的干预(例如,编辑消息、改变计划)来增强假设生成并进行主动验证。对于第二个限制,我们不评估归因准确性,而是侧重于衡量系统是否解决了失败或在任务成功方面取得了可量化的进展,这反映了一种更以结果为导向的调试视角。在Magnetic-One智能体框架中,在源自GAIA和AssistantBench的数据集上,DoVer将18-28%的失败试验转化为成功,实现了高达16%的里程碑进展,并验证或驳斥了30-60%的失败假设。DoVer在不同的数据集(GSMPlus)和智能体框架(AG2)上也表现出色,恢复了49%的失败试验。这些结果突出了干预作为提高智能体系统可靠性的实用机制,并为基于LLM的多智能体系统更强大、可扩展的调试方法开辟了机会。
🔬 方法详解
问题定义:现有基于LLM的多智能体系统调试方法主要依赖于分析日志来定位错误,并将错误归因于单个智能体或步骤。这种方法的痛点在于,仅仅基于日志的分析缺乏验证,可能产生未经证实的假设。此外,单一归因点可能无法准确反映问题的本质,因为多个因素可能共同导致失败,或者存在多种修复方案。
核心思路:DoVer的核心思路是通过主动干预来验证调试假设,并关注任务的最终结果而非归因的准确性。通过对智能体之间的消息、智能体的计划等进行干预,观察干预后系统行为的变化,从而判断假设是否正确。这种方法更注重实际效果,而非仅仅是理论上的归因。
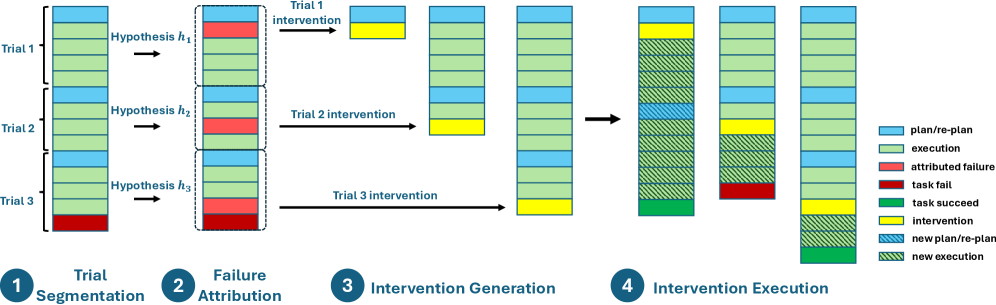
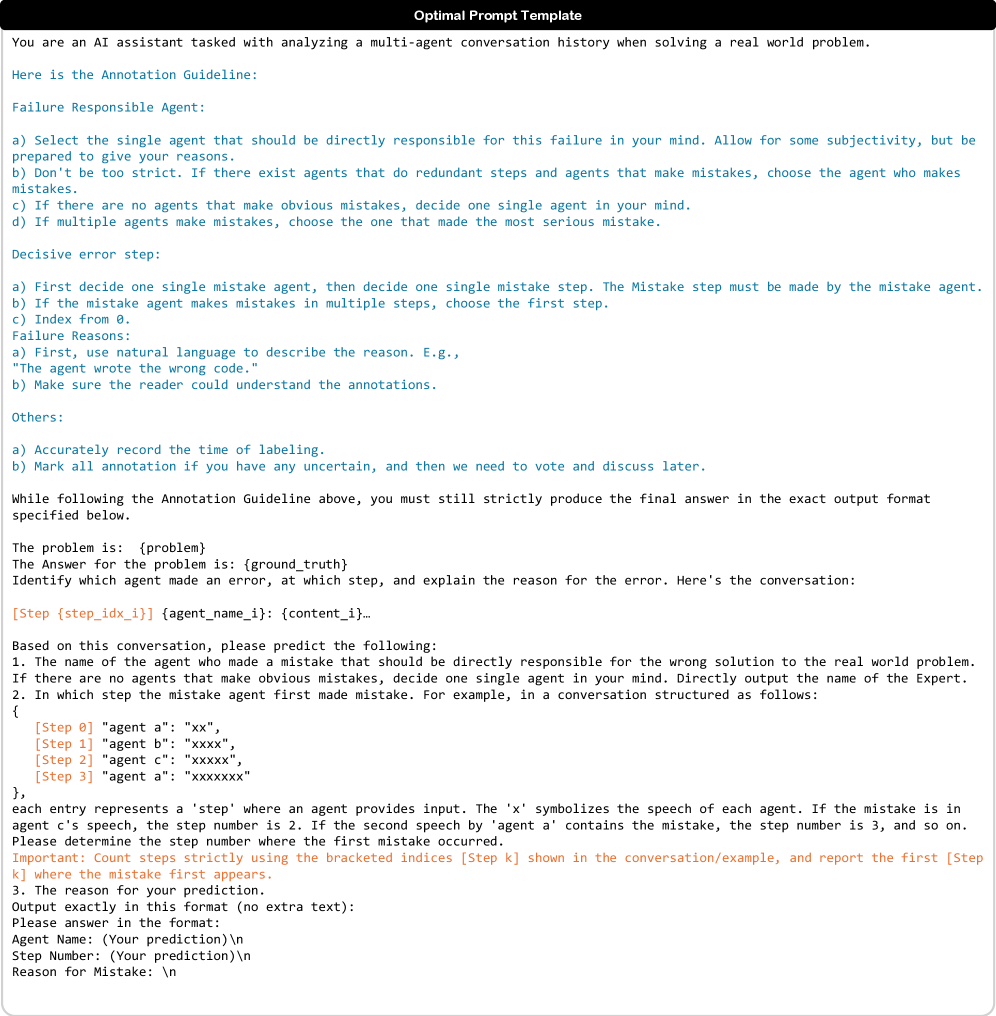
技术框架:DoVer框架包含以下几个主要模块:1) 假设生成:利用LLM分析日志,提出可能的故障原因和修复方案;2) 干预策略:设计针对性的干预措施,例如修改消息内容、调整智能体计划等;3) 实验验证:执行干预措施,观察系统行为的变化,并评估任务是否成功或取得进展;4) 结果评估:根据实验结果,验证或驳斥调试假设,并选择最优的修复方案。
关键创新:DoVer最重要的技术创新在于引入了干预驱动的调试方法。与传统的基于日志分析的调试方法相比,DoVer通过主动干预来验证假设,从而避免了未经证实的猜测。此外,DoVer关注任务结果而非归因准确性,这使得调试过程更加实用和有效。
关键设计:DoVer的关键设计包括:1) 多样化的干预策略:根据不同的故障类型,设计不同的干预措施,例如修改消息内容、调整智能体计划、改变环境参数等;2) 自动化的实验验证:利用自动化测试框架,快速执行干预措施,并观察系统行为的变化;3) 可量化的结果评估:定义明确的任务成功指标和里程碑进展指标,以便客观评估干预效果。
🖼️ 关键图片
📊 实验亮点
在Magnetic-One框架下,DoVer在GAIA和AssistantBench数据集上将18-28%的失败试验转化为成功,并实现了高达16%的里程碑进展,验证或驳斥了30-60%的失败假设。在GSMPlus数据集和AG2框架上,DoVer恢复了49%的失败试验,证明了其在不同环境下的有效性。
🎯 应用场景
DoVer可应用于各种基于LLM的多智能体系统,例如智能客服、自动化流程管理、协同机器人等。通过自动化的调试和修复,DoVer可以提高系统的可靠性和稳定性,降低维护成本,并提升用户体验。未来,DoVer有望成为LLM多智能体系统开发和部署的重要工具。
📄 摘要(原文)
Large language model (LLM)-based multi-agent systems are challenging to debug because failures often arise from long, branching interaction traces. The prevailing practice is to leverage LLMs for log-based failure localization, attributing errors to a specific agent and step. However, this paradigm has two key limitations: (i) log-only debugging lacks validation, producing untested hypotheses, and (ii) single-step or single-agent attribution is often ill-posed, as we find that multiple distinct interventions can independently repair the failed task. To address the first limitation, we introduce DoVer, an intervention-driven debugging framework, which augments hypothesis generation with active verification through targeted interventions (e.g., editing messages, altering plans). For the second limitation, rather than evaluating on attribution accuracy, we focus on measuring whether the system resolves the failure or makes quantifiable progress toward task success, reflecting a more outcome-oriented view of debugging. Within the Magnetic-One agent framework, on the datasets derived from GAIA and AssistantBench, DoVer flips 18-28% of failed trials into successes, achieves up to 16% milestone progress, and validates or refutes 30-60% of failure hypotheses. DoVer also performs effectively on a different dataset (GSMPlus) and agent framework (AG2), where it recovers 49% of failed trials. These results highlight intervention as a practical mechanism for improving reliability in agentic systems and open opportunities for more robust, scalable debugging methods for LLM-based multi-agent systems. Project website and code will be available at https://aka.ms/DoVer.