Cognitive Control Architecture (CCA): A Lifecycle Supervision Framework for Robustly Aligned AI Agents
作者: Zhibo Liang, Tianze Hu, Zaiye Chen, Mingjie Tang
分类: cs.AI, cs.CL, cs.CR
发布日期: 2025-12-07 (更新: 2026-01-23)
💡 一句话要点
提出认知控制架构CCA,解决LLM Agent中IPI攻击的鲁棒对齐问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM Agent 间接提示注入 认知控制架构 意图图 分层仲裁器
📋 核心要点
- 现有防御机制在LLM Agent中存在安全性和功能性的权衡,无法有效应对复杂的间接提示注入(IPI)攻击。
- 提出认知控制架构(CCA),通过意图图进行完整性控制,并采用分层仲裁器进行偏差检测和深度推理。
- 实验表明,CCA在AgentDojo基准上能够有效抵御复杂攻击,并在安全、效率和鲁棒性之间取得平衡。
📝 摘要(中文)
自主大型语言模型(LLM)Agent极易受到间接提示注入(IPI)攻击。这些攻击通过污染外部信息源来劫持Agent行为,利用现有防御机制在安全性和功能性之间的根本权衡。这导致恶意和未经授权的工具调用,使Agent偏离其原始目标。复杂IPI的成功揭示了更深层次的系统脆弱性:虽然当前的防御措施显示出一定的有效性,但大多数防御架构本质上是分散的。因此,它们无法在整个任务执行管道中提供完整的完整性保证,从而迫使安全、功能和效率之间做出不可接受的多维妥协。我们的方法基于一个核心洞察:无论IPI攻击多么微妙,其对恶意目标的追求最终都会表现为行动轨迹中可检测到的偏差,这与预期的合法计划不同。基于此,我们提出了认知控制架构(CCA),这是一个实现全生命周期认知监督的整体框架。CCA通过两个协同支柱构建了一个高效的双层防御系统:(i)通过预生成的“意图图”主动和抢先地执行控制流和数据流完整性;(ii)一种创新的“分层仲裁器”,一旦检测到偏差,就会启动基于多维评分的深度推理,专门用于对抗复杂的条件攻击。在AgentDojo基准上的实验证实,CCA不仅有效地抵御了挑战其他先进防御方法的复杂攻击,而且以显著的效率和鲁棒性实现了完全的安全,从而协调了上述多维权衡。
🔬 方法详解
问题定义:论文旨在解决自主LLM Agent易受间接提示注入(IPI)攻击的问题。现有防御方法通常是碎片化的,无法在整个任务执行流程中提供完整的安全性保证,并且需要在安全性、功能性和效率之间做出妥协。IPI攻击通过污染外部信息源来劫持Agent的行为,导致恶意工具调用和目标偏离。
核心思路:论文的核心思路是,无论IPI攻击多么隐蔽,其最终都会在Agent的行动轨迹上表现出与预期计划的偏差。通过监控和分析Agent的行动轨迹,可以检测并阻止IPI攻击。CCA架构基于这一洞察,通过主动的完整性控制和事后的偏差检测,实现全生命周期的认知监督。
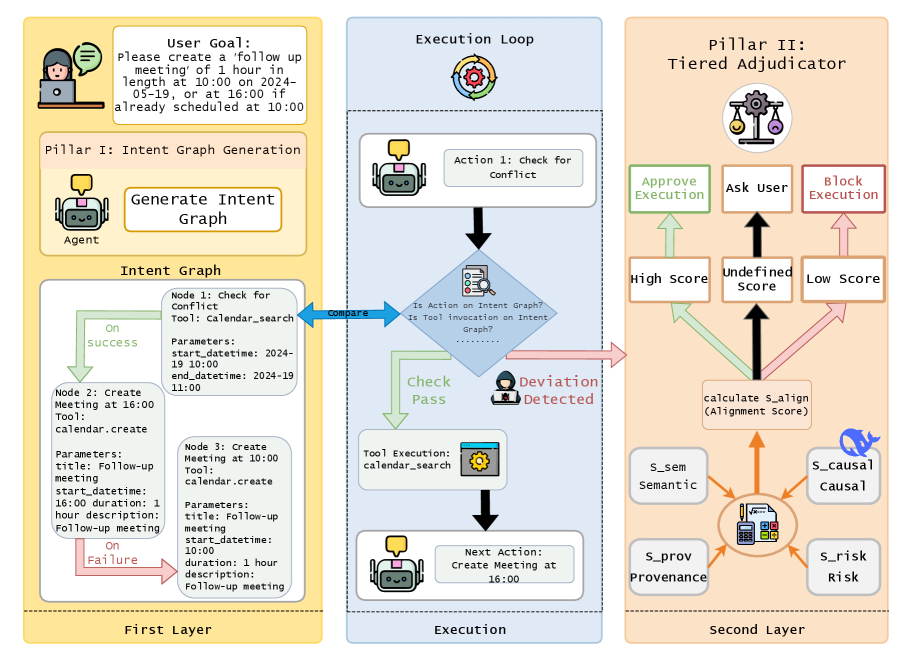
技术框架:CCA架构包含两个主要组成部分:意图图(Intent Graph)和分层仲裁器(Tiered Adjudicator)。意图图是一个预先生成的图,用于定义Agent的预期行为和数据流,从而实现主动的控制流和数据流完整性。分层仲裁器则负责监控Agent的行动轨迹,一旦检测到偏差,就会启动基于多维评分的深度推理,以判断是否存在IPI攻击。
关键创新:CCA的关键创新在于其全生命周期的认知监督方法,以及意图图和分层仲裁器的协同工作。意图图实现了主动的防御,而分层仲裁器则提供了事后的检测和推理能力。这种双层防御体系能够有效地应对复杂的条件攻击,并在安全、功能和效率之间取得平衡。
关键设计:意图图的设计需要仔细考虑Agent的任务目标和可能的行动路径,以确保其能够覆盖所有合法的行为。分层仲裁器的多维评分机制需要根据具体的应用场景进行调整,以提高检测的准确性和效率。论文中没有明确给出具体的参数设置、损失函数或网络结构等技术细节,这些可能需要根据实际情况进行调整和优化。
🖼️ 关键图片

📊 实验亮点
实验结果表明,CCA在AgentDojo基准上能够有效抵御复杂的IPI攻击,优于其他先进的防御方法。CCA不仅实现了更高的安全性,还在效率和鲁棒性方面表现出色,从而解决了传统防御方法在安全、功能和效率之间的权衡问题。具体的性能数据和提升幅度在论文中没有明确给出,需要查阅原文获取。
🎯 应用场景
该研究成果可应用于各种需要自主Agent进行决策和执行任务的领域,例如智能客服、自动化流程管理、智能家居等。通过提高Agent的安全性,可以防止恶意攻击和数据泄露,确保Agent能够可靠地完成任务,从而提升用户体验和系统效率。未来,该技术有望进一步发展,应用于更复杂的场景,例如自动驾驶、金融风控等。
📄 摘要(原文)
Autonomous Large Language Model (LLM) agents exhibit significant vulnerability to Indirect Prompt Injection (IPI) attacks. These attacks hijack agent behavior by polluting external information sources, exploiting fundamental trade-offs between security and functionality in existing defense mechanisms. This leads to malicious and unauthorized tool invocations, diverting agents from their original objectives. The success of complex IPIs reveals a deeper systemic fragility: while current defenses demonstrate some effectiveness, most defense architectures are inherently fragmented. Consequently, they fail to provide full integrity assurance across the entire task execution pipeline, forcing unacceptable multi-dimensional compromises among security, functionality, and efficiency. Our method is predicated on a core insight: no matter how subtle an IPI attack, its pursuit of a malicious objective will ultimately manifest as a detectable deviation in the action trajectory, distinct from the expected legitimate plan. Based on this, we propose the Cognitive Control Architecture (CCA), a holistic framework achieving full-lifecycle cognitive supervision. CCA constructs an efficient, dual-layered defense system through two synergistic pillars: (i) proactive and preemptive control-flow and data-flow integrity enforcement via a pre-generated "Intent Graph"; and (ii) an innovative "Tiered Adjudicator" that, upon deviation detection, initiates deep reasoning based on multi-dimensional scoring, specifically designed to counter complex conditional attacks. Experiments on the AgentDojo benchmark substantiate that CCA not only effectively withstands sophisticated attacks that challenge other advanced defense methods but also achieves uncompromised security with notable efficiency and robustness, thereby reconciling the aforementioned multi-dimensional trade-off.