Stochasticity in Agentic Evaluations: Quantifying Inconsistency with Intraclass Correlation
作者: Zairah Mustahsan, Abel Lim, Megna Anand, Saahil Jain, Bryan McCann
分类: cs.AI
发布日期: 2025-12-07
🔗 代码/项目: GITHUB
💡 一句话要点
提出使用类内相关系数(ICC)量化Agent评估中的随机性,提升评估可靠性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Agent评估 类内相关系数 随机性 可靠性 大型语言模型 基准测试 方差分析
📋 核心要点
- 现有Agent评估方法仅报告单次准确率,忽略了评估结果的随机性和不确定性,难以区分真实能力提升和偶然因素。
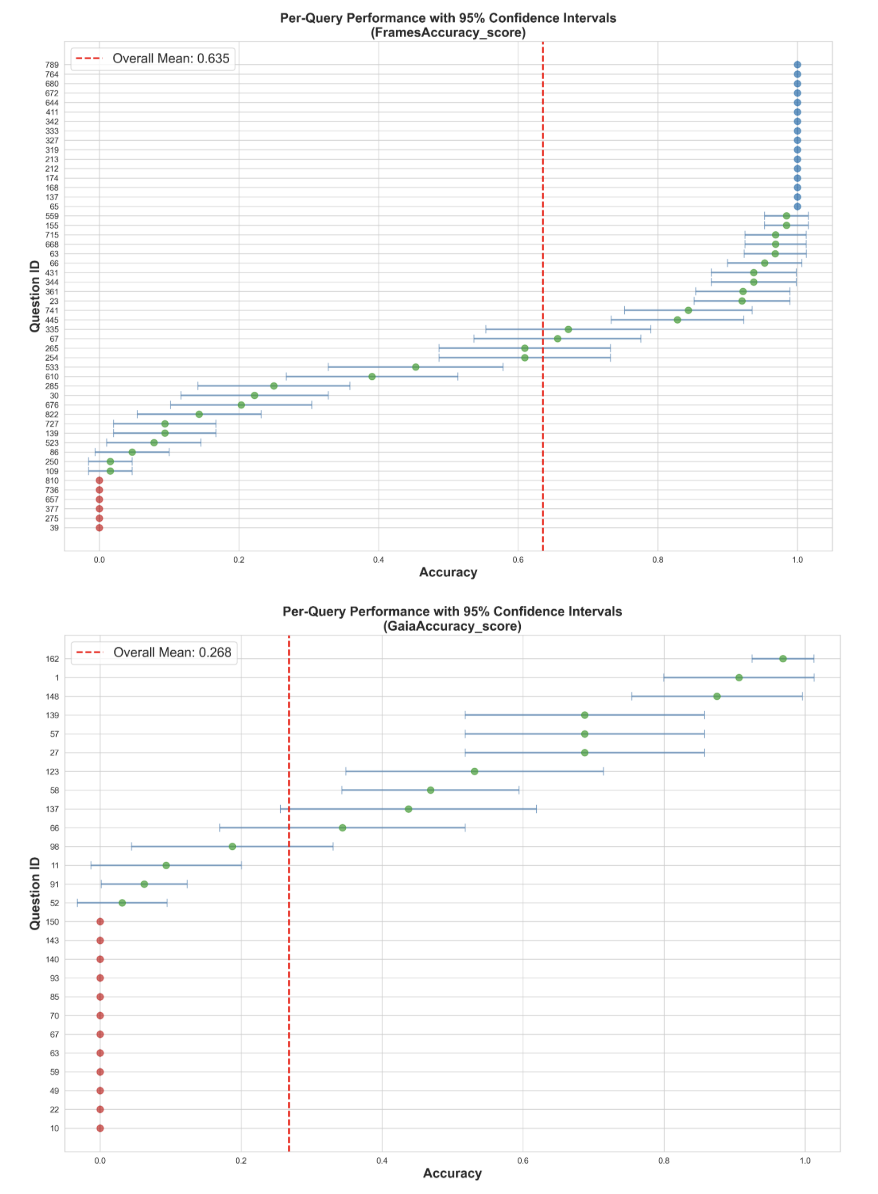
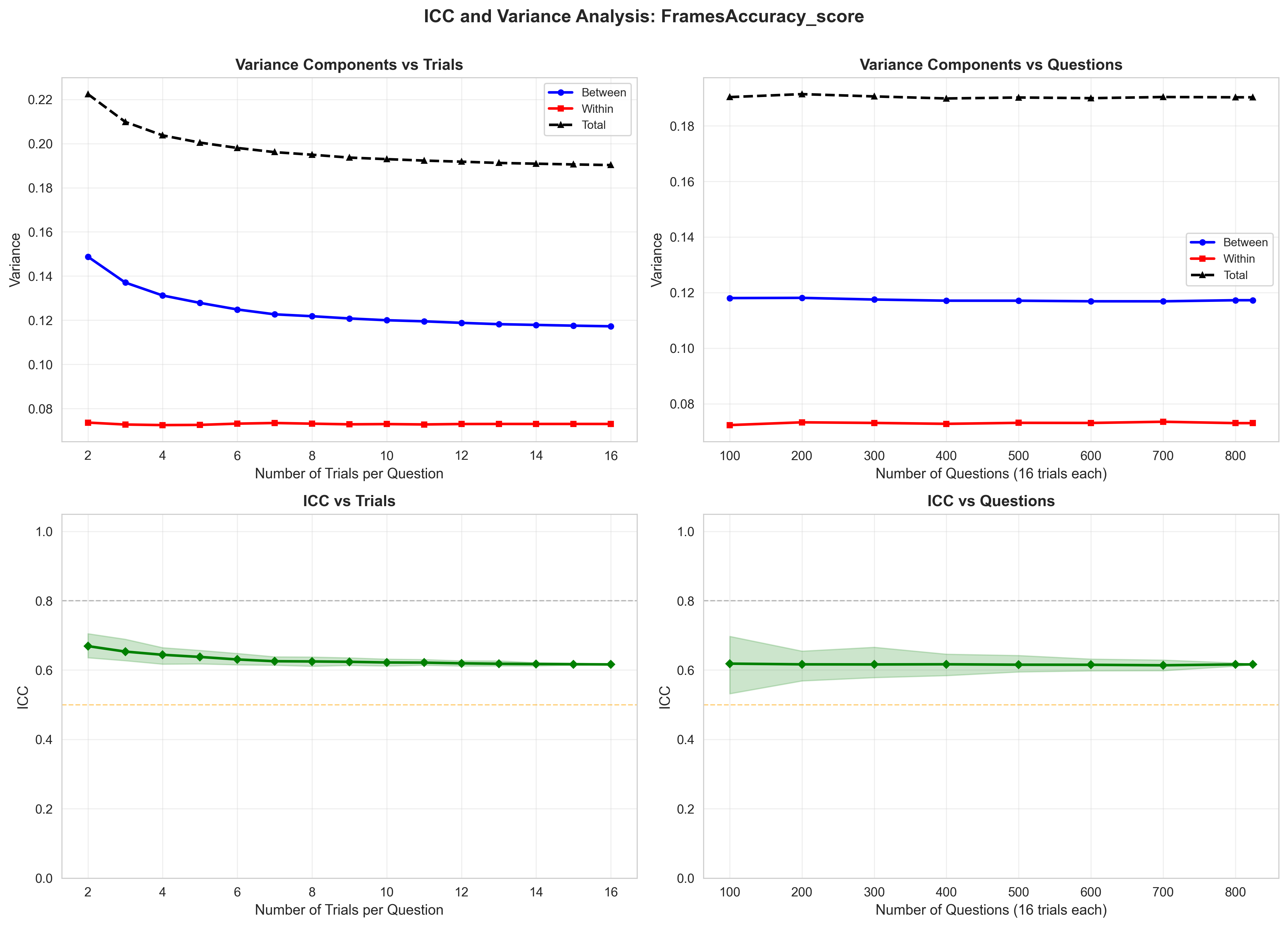
- 论文提出使用类内相关系数(ICC)来量化Agent评估中的随机性,将方差分解为任务难度和Agent不一致性。
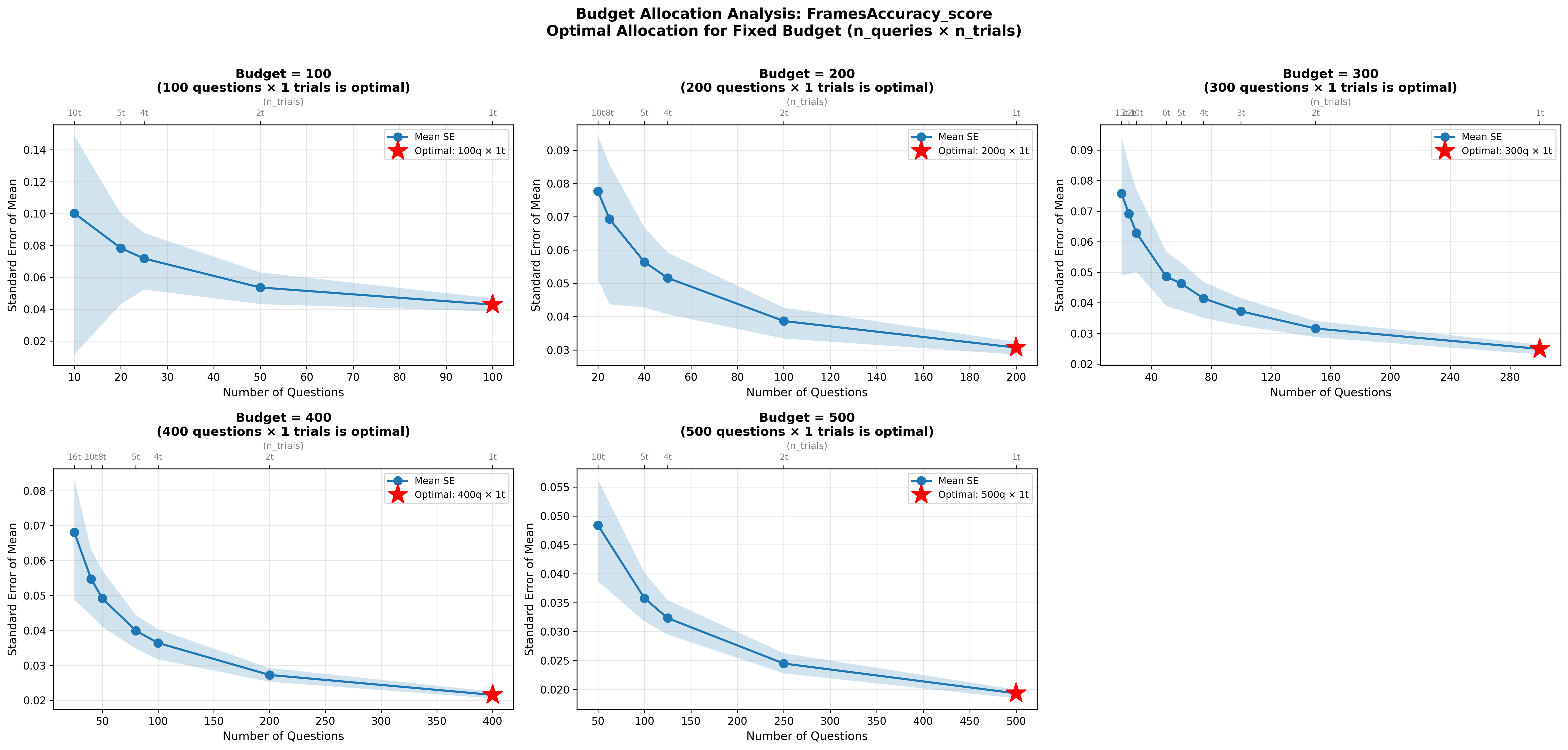
- 实验表明,ICC随任务结构变化显著,并给出了不同任务类型下ICC收敛所需的采样次数,为评估提供了参考。
📝 摘要(中文)
随着大型语言模型成为大型Agent系统的组成部分,评估可靠性变得至关重要:不可靠的子Agent会给下游系统行为带来脆弱性。然而,当前的评估实践,仅报告单次运行的单一准确率数值,掩盖了这些结果的潜在方差,使得区分真正的能力提升和幸运采样变得不可能。我们建议采用测量科学中的类内相关系数(ICC)来表征这种方差。ICC将观察到的方差分解为查询间方差(任务难度)和查询内方差(Agent不一致性),突出了报告的结果是反映了真实能力还是测量噪声。我们在GAIA(1-3级,衡量跨不同推理复杂度的Agent能力)和FRAMES(衡量跨多个文档的检索和事实性)上进行了评估。我们发现ICC随任务结构而变化很大,推理和检索任务(FRAMES)在不同模型中表现出ICC=0.4955-0.7118,而Agent任务(GAIA)在不同模型中表现出ICC=0.304-0.774。对于Agent系统中子Agent的替换决策,只有当ICC也得到改善时,准确率的提高才是可信的。我们证明,对于结构化任务,ICC通过n=8-16次试验收敛,对于复杂推理,ICC通过n>=32次试验收敛,使从业者能够设置基于证据的重采样预算。我们建议将准确率与ICC和查询内方差一起报告作为标准实践,并提出更新的评估卡来捕获这些指标。通过使评估稳定性可见,我们的目标是将Agent基准测试从不透明的排行榜竞争转变为可信的实验科学。我们的代码已在https://github.com/youdotcom-oss/stochastic-agent-evals上开源。
🔬 方法详解
问题定义:论文旨在解决Agent评估中存在的随机性和不确定性问题。现有评估方法通常只报告单次运行的准确率,忽略了评估结果的方差,使得难以区分Agent能力的真实提升和偶然的幸运采样。这种不确定性导致下游Agent系统行为的脆弱性,影响了Agent替换决策的可靠性。
核心思路:论文的核心思路是借鉴测量科学中的类内相关系数(ICC)来量化Agent评估中的随机性。ICC能够将观察到的方差分解为查询间方差(任务难度)和查询内方差(Agent不一致性),从而更准确地评估Agent的真实能力。通过多次运行Agent并计算ICC,可以评估评估结果的稳定性,并确定所需的采样次数。
技术框架:论文的技术框架主要包括以下几个步骤:1)选择合适的Agent评估任务,如GAIA和FRAMES;2)多次运行Agent,获得每个查询的多个结果;3)计算类内相关系数(ICC),将总方差分解为查询间方差和查询内方差;4)分析ICC值,评估Agent评估的可靠性;5)确定ICC收敛所需的采样次数,为评估提供参考。
关键创新:论文最重要的技术创新点在于将类内相关系数(ICC)引入到Agent评估领域。与传统的单次准确率评估方法相比,ICC能够更全面地评估Agent的性能,并量化评估结果的随机性和不确定性。这使得评估结果更加可靠,并为Agent替换决策提供了更强的依据。
关键设计:论文的关键设计包括:1)选择GAIA和FRAMES作为评估任务,涵盖了不同类型的Agent能力,如推理、检索和事实性;2)使用不同的大型语言模型作为Agent,评估ICC在不同模型上的表现;3)通过实验确定ICC收敛所需的采样次数,为评估提供了具体的指导;4)提出更新的评估卡,将ICC和查询内方差作为标准评估指标。
🖼️ 关键图片
📊 实验亮点
实验结果表明,ICC随任务结构变化显著,推理和检索任务(FRAMES)的ICC在0.4955-0.7118之间,Agent任务(GAIA)的ICC在0.304-0.774之间。对于结构化任务,ICC通过8-16次试验收敛,对于复杂推理,ICC通过32次以上试验收敛。这些结果为Agent评估提供了重要的参考。
🎯 应用场景
该研究成果可应用于Agent系统的开发和评估,例如,在选择合适的子Agent时,可以参考ICC指标,避免选择性能不稳定的Agent。此外,该方法还可以用于评估不同Agent评估任务的难度和可靠性,为Agent基准测试提供更科学的依据。未来,该方法可以推广到其他AI系统的评估中,提高评估的可靠性和可信度。
📄 摘要(原文)
As large language models become components of larger agentic systems, evaluation reliability becomes critical: unreliable sub-agents introduce brittleness into downstream system behavior. Yet current evaluation practice, reporting a single accuracy number from a single run, obscures the variance underlying these results, making it impossible to distinguish genuine capability improvements from lucky sampling. We propose adopting Intraclass Correlation Coefficient (ICC), a metric from measurement science, to characterize this variance. ICC decomposes observed variance into between-query variance (task difficulty) and within-query variance (agent inconsistency), highlighting whether reported results reflect true capability or measurement noise. We evaluated on GAIA (Levels 1-3, measuring agentic capabilities across varying reasoning complexity) and FRAMES (measuring retrieval and factuality across multiple documents). We found that ICC varies dramatically with task structure, with reasoning and retrieval tasks (FRAMES) exhibit ICC=0.4955-0.7118 across models, and agentic tasks (GAIA) exhibiting ICC=0.304-0.774 across models. For sub-agent replacement decisions in agentic systems, accuracy improvements are only trustworthy if ICC also improves. We demonstrate that ICC converges by n=8-16 trials for structured tasks and n>=32 for complex reasoning, enabling practitioners to set evidence-based resampling budgets. We recommend reporting accuracy alongside ICC and within-query variance as standard practice, and propose updated Evaluation Cards capturing these metrics. By making evaluation stability visible, we aim to transform agentic benchmarking from opaque leaderboard competition to trustworthy experimental science. Our code is open-sourced at https://github.com/youdotcom-oss/stochastic-agent-evals.