LightSearcher: Efficient DeepSearch via Experiential Memory
作者: Hengzhi Lan, Yue Yu, Li Qian, Li Peng, Jie Wu, Wei Liu, Jian Luan, Ting Bai
分类: cs.AI
发布日期: 2025-12-07 (更新: 2025-12-10)
备注: 10 pages, 5 figures
💡 一句话要点
LightSearcher:通过经验记忆实现高效的深度搜索
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 深度搜索 强化学习 经验记忆 多跳问答 效率优化
📋 核心要点
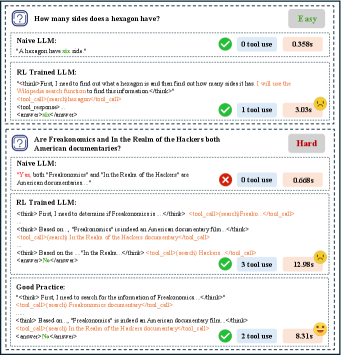
- 现有基于强化学习的深度搜索方法在准确性和效率之间存在权衡,频繁的工具调用虽能提高准确性,但计算开销大。
- LightSearcher通过引入文本经验记忆,学习对比推理轨迹,生成可解释的推理摘要,从而减少不必要的搜索调用。
- 实验表明,LightSearcher在保持与SOTA基线相当的准确性的同时,显著降低了搜索工具调用次数、推理时间和token消耗。
📝 摘要(中文)
深度搜索范式已成为深度推理模型的关键赋能技术,使其能够调用外部搜索工具来访问最新的、特定领域的知识,从而增强推理的深度和事实可靠性。最近,强化学习(RL)的进展进一步使模型能够自主且策略性地控制搜索工具的使用,优化何时以及如何查询外部知识源。然而,这些由RL驱动的深度搜索系统通常揭示了准确性和效率之间的权衡——频繁的工具调用可以提高事实正确性,但会导致不必要的计算开销和效率降低。为了解决这个问题,我们提出了LightSearcher,一个高效的RL框架,它通过学习对比推理轨迹来生成成功推理模式的可解释摘要,从而整合了文本经验记忆。此外,它采用了一种自适应奖励塑造机制,仅在正确答案的情况下惩罚冗余的工具调用。这种设计有效地平衡了深度搜索范式中固有的准确性-效率权衡。在四个多跳问答基准上的实验表明,LightSearcher保持了与SOTA基线ReSearch相当的准确性,同时减少了39.6%的搜索工具调用,48.6%的推理时间和21.2%的token消耗,证明了其卓越的效率。
🔬 方法详解
问题定义:论文旨在解决基于强化学习的深度搜索方法中准确性和效率之间的权衡问题。现有方法为了提高推理的准确性,往往会频繁调用外部搜索工具,导致计算开销过大,效率降低。因此,如何在保证准确性的前提下,减少不必要的搜索调用,是本论文要解决的核心问题。
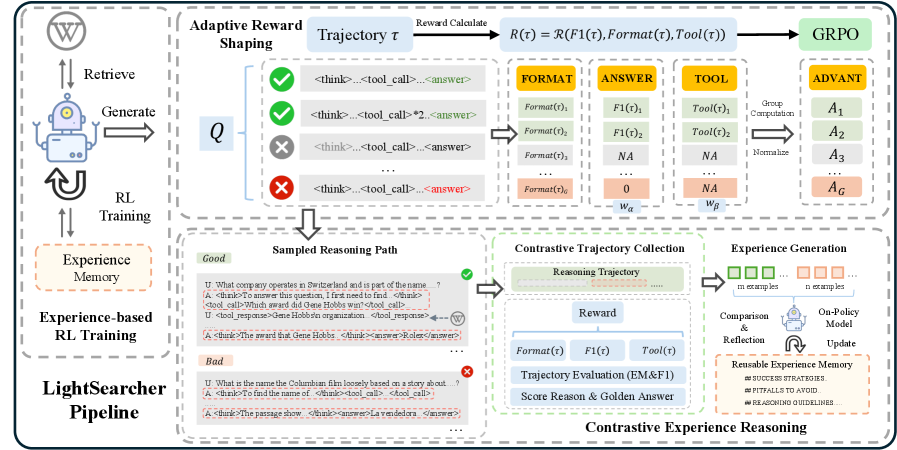
核心思路:LightSearcher的核心思路是通过引入文本经验记忆,让模型学习成功的推理模式,并利用这些经验来指导未来的搜索过程。具体来说,模型会学习对比推理轨迹,生成可解释的推理摘要,从而避免重复搜索已经知道的信息,减少不必要的工具调用。同时,采用自适应奖励塑造机制,仅在答案正确的情况下惩罚冗余的工具调用,鼓励模型在保证准确性的前提下提高效率。
技术框架:LightSearcher的整体框架包含以下几个主要模块:1) 文本经验记忆模块:用于存储和检索成功的推理轨迹,并生成可解释的推理摘要。2) 强化学习代理:负责控制搜索工具的调用,并根据环境反馈调整搜索策略。3) 自适应奖励塑造模块:根据模型的行为和答案的正确性,动态调整奖励函数,引导模型学习高效的搜索策略。整个流程如下:首先,模型根据当前状态和经验记忆,决定是否调用搜索工具。如果调用,则根据搜索结果更新状态,并获得环境反馈。然后,模型根据环境反馈和自适应奖励,更新强化学习代理的策略。最后,模型将成功的推理轨迹存储到文本经验记忆中,以便未来使用。
关键创新:LightSearcher最重要的技术创新点在于引入了文本经验记忆,并利用对比学习来学习推理轨迹。与传统的强化学习方法相比,LightSearcher能够更好地利用历史经验,避免重复搜索,从而提高效率。此外,自适应奖励塑造机制也能够有效地平衡准确性和效率之间的权衡。
关键设计:LightSearcher的关键设计包括:1) 使用对比学习来训练文本经验记忆模块,使其能够生成可解释的推理摘要。2) 设计自适应奖励函数,仅在答案正确的情况下惩罚冗余的工具调用。3) 使用Transformer模型作为强化学习代理,使其能够更好地处理文本信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LightSearcher在四个多跳问答基准上,与SOTA基线ReSearch相比,保持了相当的准确性,同时减少了39.6%的搜索工具调用,48.6%的推理时间和21.2%的token消耗。这些数据充分证明了LightSearcher在效率方面的优势。
🎯 应用场景
LightSearcher具有广泛的应用前景,可应用于问答系统、知识图谱推理、智能助手等领域。通过提高搜索效率,可以显著降低计算成本,并提升用户体验。未来,该技术有望应用于更复杂的推理任务,例如科学发现、医疗诊断等,为人工智能的发展做出贡献。
📄 摘要(原文)
DeepSearch paradigms have become a core enabler for deep reasoning models, allowing them to invoke external search tools to access up-to-date, domain-specific knowledge beyond parametric boundaries, thereby enhancing the depth and factual reliability of reasoning. Building upon this foundation, recent advances in reinforcement learning (RL) have further empowered models to autonomously and strategically control search tool usage, optimizing when and how to query external knowledge sources. Yet, these RL-driven DeepSearch systems often reveal a see-saw trade-off between accuracy and efficiency-frequent tool invocations can improve factual correctness but lead to unnecessary computational overhead and diminished efficiency. To address this challenge, we propose LightSearcher, an efficient RL framework that incorporates textual experiential memory by learning contrastive reasoning trajectories to generate interpretable summaries of successful reasoning patterns. In addition, it employs an adaptive reward shaping mechanism that penalizes redundant tool calls only in correct-answer scenarios. This design effectively balances the inherent accuracy-efficiency trade-off in DeepSearch paradigms. Experiments on four multi-hop QA benchmarks show that LightSearcher maintains accuracy comparable to SOTA baseline ReSearch, while reducing search tool invocations by 39.6%, inference time by 48.6%, and token consumption by 21.2%, demonstrating its superior efficiency.