Securing the Model Context Protocol: Defending LLMs Against Tool Poisoning and Adversarial Attacks
作者: Saeid Jamshidi, Kawser Wazed Nafi, Arghavan Moradi Dakhel, Negar Shahabi, Foutse Khomh, Naser Ezzati-Jivan
分类: cs.CR, cs.AI
发布日期: 2025-12-06
💡 一句话要点
提出针对模型上下文协议(MCP)的安全框架,防御LLM工具中毒和对抗攻击
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型安全 模型上下文协议 工具中毒 对抗攻击 语义安全 分层防御 LLM安全
📋 核心要点
- 现有防御主要关注提示注入,忽略了工具元数据中的语义攻击,导致基于MCP的LLM系统存在安全漏洞。
- 提出分层安全框架,包括RSA签名保证完整性、LLM语义审查检测恶意定义、启发式护栏阻止异常行为。
- 实验表明,该框架能在不微调模型的情况下降低不安全工具调用率,不同模型表现各异,GPT-4平衡了安全与效率。
📝 摘要(中文)
模型上下文协议(MCP)通过结构化描述符使大型语言模型能够集成外部工具,从而提高决策、任务执行和多智能体工作流的自主性。然而,这种自主性带来了一个被严重忽视的安全漏洞。现有的防御措施主要集中于提示注入攻击,而未能解决嵌入在工具元数据中的威胁,使得基于MCP的系统容易受到语义操纵。本文分析了针对MCP集成系统的三种语义攻击:(1)工具中毒,即对抗性指令隐藏在工具描述符中;(2)阴影攻击,即受信任的工具通过受污染的共享上下文间接受到损害;(3)撤退攻击,即描述符在批准后被更改以破坏行为。为了应对这些威胁,我们引入了一个分层安全框架,包含三个组件:基于RSA的清单签名以强制执行描述符完整性,LLM-on-LLM语义审查以检测可疑的工具定义,以及轻量级启发式护栏,用于在运行时阻止异常的工具行为。通过对GPT-4、DeepSeek和Llama-3.5在八种提示策略下的评估,我们发现安全性能因模型架构和推理方法而异。GPT-4阻止了约71%的不安全工具调用,平衡了延迟和安全性。DeepSeek对阴影攻击表现出最高的抵抗力,但延迟较高,而Llama-3.5速度最快但最不稳健。我们的结果表明,所提出的框架降低了不安全工具的调用率,而无需模型微调或内部修改。
🔬 方法详解
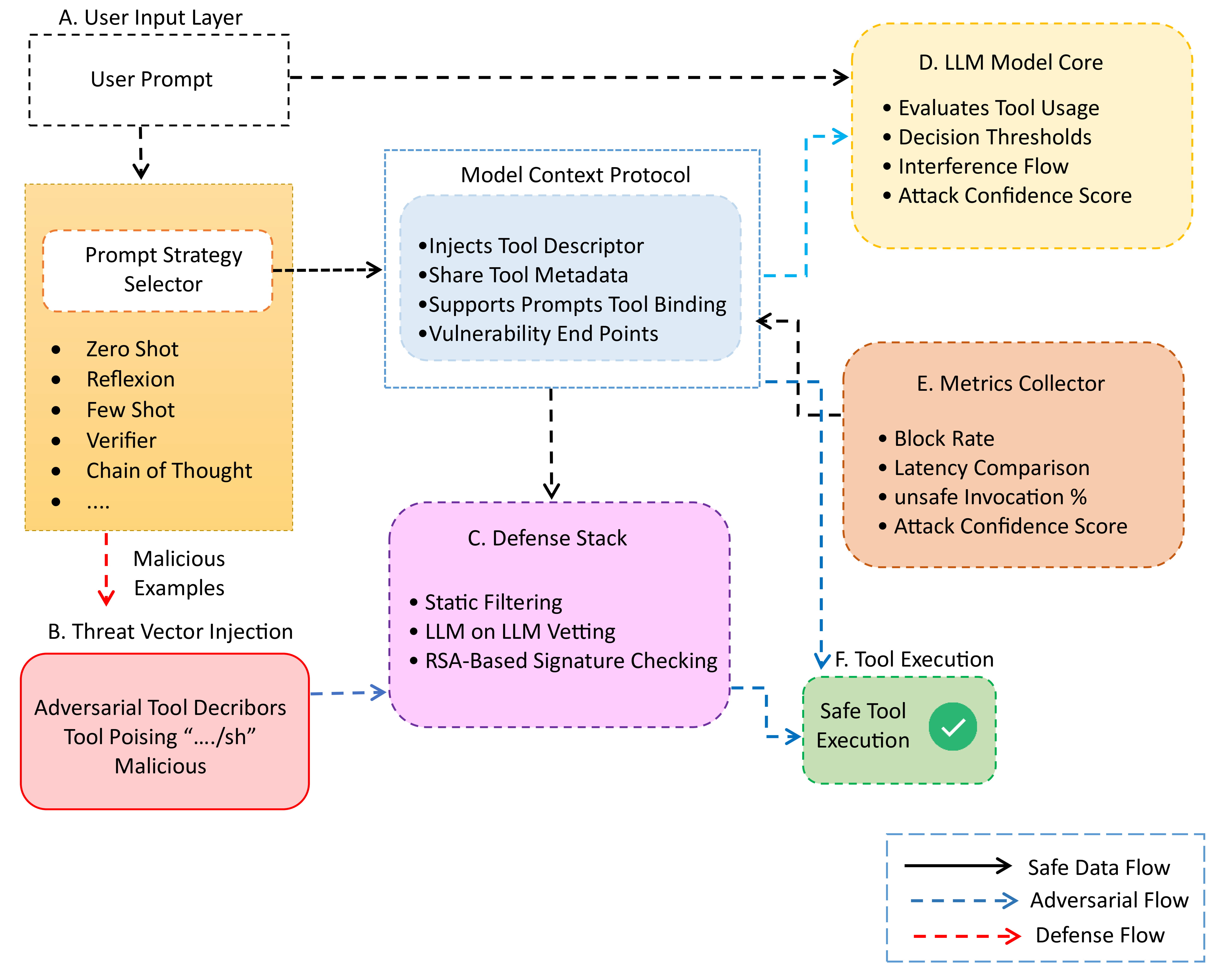
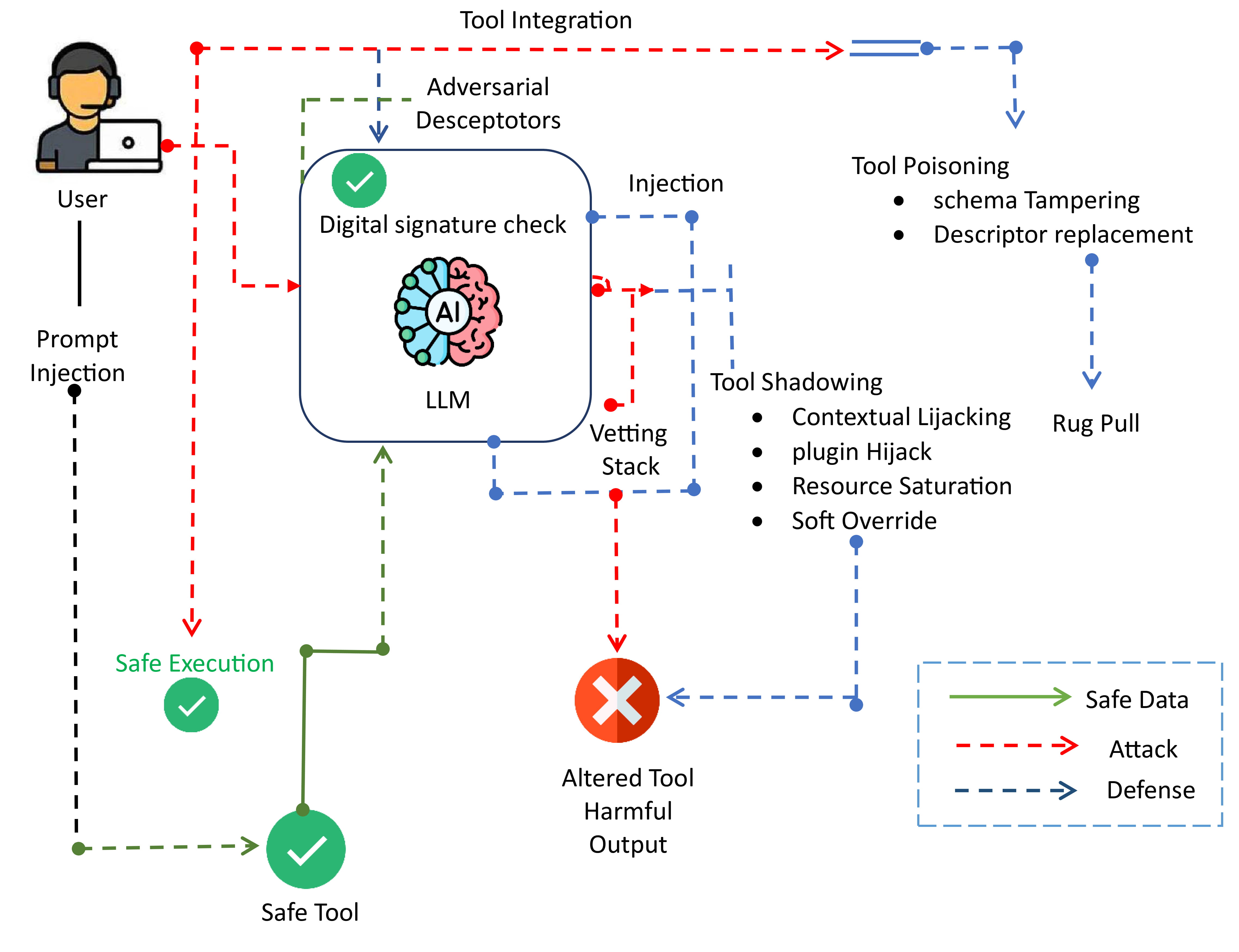
问题定义:论文旨在解决大型语言模型(LLM)通过模型上下文协议(MCP)集成外部工具时面临的安全问题。现有防御方法主要关注提示注入攻击,而忽略了工具元数据中存在的语义攻击,例如工具中毒、阴影攻击和撤退攻击。这些攻击方式能够绕过现有的安全机制,对LLM系统的安全性和可靠性构成严重威胁。
核心思路:论文的核心思路是构建一个多层次的安全框架,从工具描述符的完整性、语义可信度和运行时行为三个方面进行防御。通过RSA签名确保工具描述符未被篡改,利用LLM进行语义审查识别潜在的恶意工具定义,并采用启发式护栏在运行时监控和阻止异常的工具行为。这种分层防御体系能够有效应对各种语义攻击,提高LLM系统的安全性。
技术框架:该安全框架包含三个主要组件:1) RSA签名:使用RSA算法对工具描述符进行签名,确保其完整性和来源可信度。2) LLM语义审查:利用另一个LLM(LLM-on-LLM)对工具描述符的语义进行分析,检测其中是否存在可疑或恶意的指令。3) 启发式护栏:在运行时监控工具的使用行为,通过预定义的规则和阈值,检测并阻止异常的工具调用。这三个组件协同工作,形成一个完整的防御体系。
关键创新:该论文的关键创新在于提出了一个针对MCP集成系统的分层安全框架,能够有效防御工具中毒、阴影攻击和撤退攻击等语义攻击。与现有的防御方法相比,该框架不仅关注提示注入攻击,还考虑了工具元数据中存在的安全风险,从而更全面地保护LLM系统的安全。此外,该框架无需对LLM进行微调或内部修改,具有较好的通用性和可扩展性。
关键设计:RSA签名采用标准的RSA算法,密钥管理策略未知。LLM语义审查使用另一个LLM进行零样本或少样本学习,判断工具描述符是否安全,具体提示词设计未知。启发式护栏基于预定义的规则和阈值,例如限制工具的调用频率、监控工具的输出内容等,具体规则设计未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,所提出的安全框架能够有效降低不安全工具的调用率。在GPT-4上,该框架能够阻止约71%的不安全工具调用,在安全性和延迟之间取得了较好的平衡。DeepSeek对阴影攻击表现出最高的抵抗力,但延迟较高。Llama-3.5速度最快但安全性较差。这些结果表明,不同LLM模型对语义攻击的抵抗能力存在差异,需要根据具体应用场景选择合适的模型和安全策略。
🎯 应用场景
该研究成果可应用于各种需要LLM与外部工具集成的场景,例如智能助手、自动化工作流、多智能体系统等。通过提高LLM系统的安全性,可以降低恶意攻击的风险,保障用户数据安全,提升系统的可靠性和可用性。该研究对于推动LLM在实际应用中的广泛部署具有重要意义。
📄 摘要(原文)
The Model Context Protocol (MCP) enables Large Language Models to integrate external tools through structured descriptors, increasing autonomy in decision-making, task execution, and multi-agent workflows. However, this autonomy creates a largely overlooked security gap. Existing defenses focus on prompt-injection attacks and fail to address threats embedded in tool metadata, leaving MCP-based systems exposed to semantic manipulation. This work analyzes three classes of semantic attacks on MCP-integrated systems: (1) Tool Poisoning, where adversarial instructions are hidden in tool descriptors; (2) Shadowing, where trusted tools are indirectly compromised through contaminated shared context; and (3) Rug Pulls, where descriptors are altered after approval to subvert behavior. To counter these threats, we introduce a layered security framework with three components: RSA-based manifest signing to enforce descriptor integrity, LLM-on-LLM semantic vetting to detect suspicious tool definitions, and lightweight heuristic guardrails that block anomalous tool behavior at runtime. Through evaluation of GPT-4, DeepSeek, and Llama-3.5 across eight prompting strategies, we find that security performance varies widely by model architecture and reasoning method. GPT-4 blocks about 71 percent of unsafe tool calls, balancing latency and safety. DeepSeek shows the highest resilience to Shadowing attacks but with greater latency, while Llama-3.5 is fastest but least robust. Our results show that the proposed framework reduces unsafe tool invocation rates without model fine-tuning or internal modification.