DaGRPO: Rectifying Gradient Conflict in Reasoning via Distinctiveness-Aware Group Relative Policy Optimization
作者: Xuan Xie, Xuan Wang, Wenjie Wang, Shuai Chen, Wei Lin
分类: cs.AI
发布日期: 2025-12-06 (更新: 2025-12-31)
💡 一句话要点
DaGRPO:通过区分性感知的组相对策略优化来纠正推理中的梯度冲突
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推理能力 梯度优化 策略优化 数据增强 梯度冲突 区分性学习
📋 核心要点
- 现有GRPO方法在长程推理中表现出色,但训练不稳定且样本效率低。
- DaGRPO通过序列级梯度校正和离线数据增强来解决梯度冲突和样本稀缺问题。
- 实验表明,DaGRPO在数学推理和OOD泛化基准上显著优于现有方法,平均准确率提升4.7%。
📝 摘要(中文)
大型语言模型(LLMs)的演进已经催化了一个范式转变,从肤浅的指令遵循到严格的长程推理。组相对策略优化(GRPO)由于其卓越的性能,已成为引发这种后训练推理能力的关键机制。然而,它仍然受到显著的训练不稳定性和较差的样本效率的困扰。我们从理论上将这些问题的根本原因确定为在线策略rollout中缺乏区分性:对于常规查询,高度同质的样本会导致破坏性的梯度冲突;而对于困难查询,有效正样本的稀缺会导致无效的优化。为了弥合这一差距,我们提出了区分性感知的组相对策略优化(DaGRPO)。DaGRPO包含两个核心机制:(1)序列级梯度校正,它利用细粒度评分来动态屏蔽具有低区分性的样本对,从而从源头上消除梯度冲突;(2)离线数据增强,它引入高质量的锚点来恢复具有挑战性任务的训练信号。在9个数学推理和分布外(OOD)泛化基准上的大量实验表明,DaGRPO显著超越了现有的SFT、GRPO和混合基线,实现了新的最先进性能(例如,在数学基准上平均准确率提高了+4.7%)。此外,深入分析证实DaGRPO有效地缓解了梯度爆炸,并加速了长链推理能力的出现。
🔬 方法详解
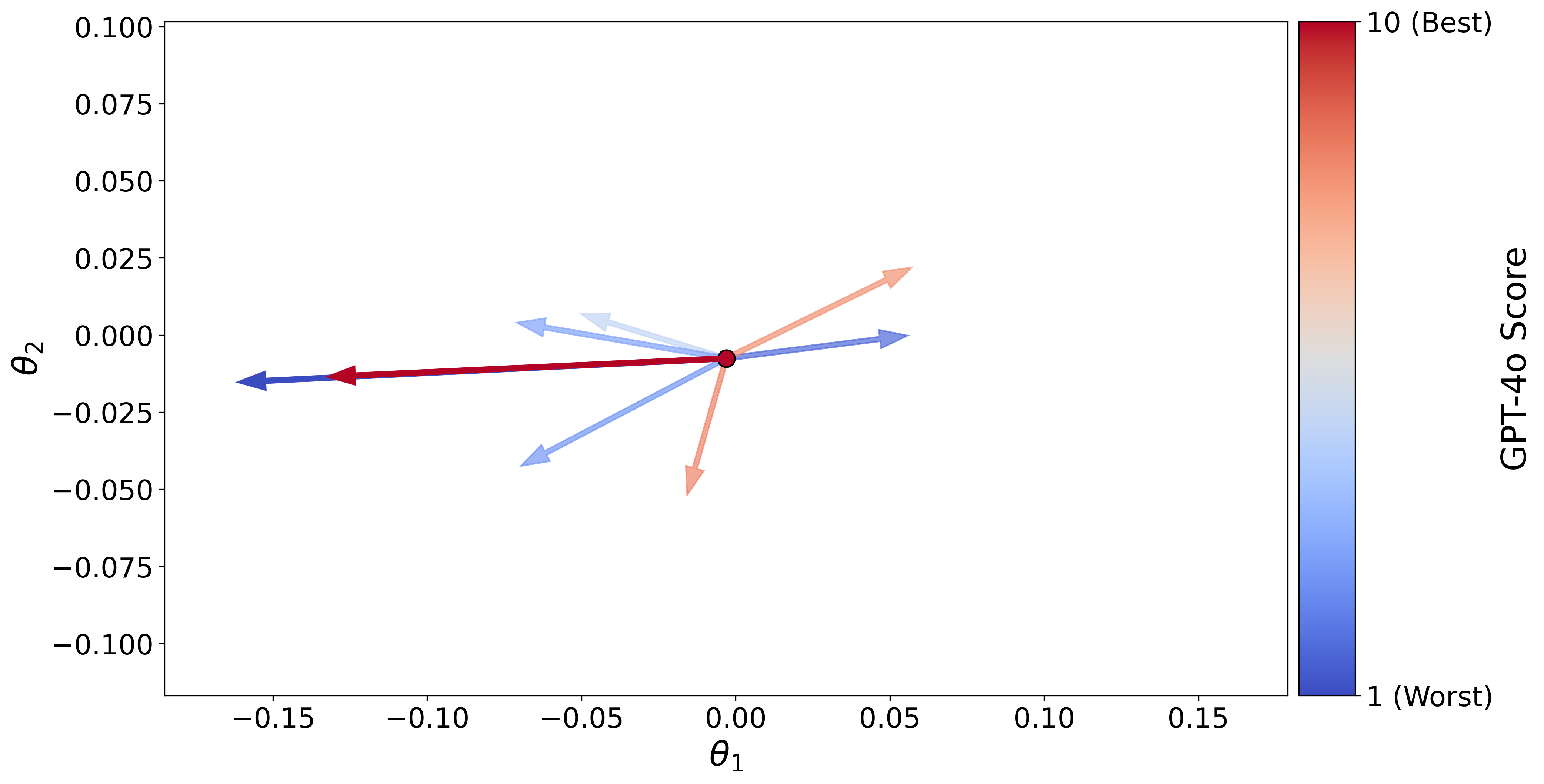
问题定义:现有组相对策略优化(GRPO)方法在训练大型语言模型进行复杂推理时,存在训练不稳定和样本效率低下的问题。主要原因是on-policy rollout中缺乏区分性,导致梯度冲突(同质样本)或训练信号不足(困难样本)。
核心思路:DaGRPO的核心思路是通过增强样本的区分性来解决梯度冲突和训练信号不足的问题。具体来说,对于同质样本,通过梯度校正来消除冲突;对于困难样本,通过离线数据增强来补充训练信号。
技术框架:DaGRPO包含两个主要模块:序列级梯度校正和离线数据增强。序列级梯度校正模块计算样本对的区分性得分,并动态屏蔽低区分性的样本对,从而消除梯度冲突。离线数据增强模块引入高质量的锚点样本,以恢复困难任务的训练信号。整体流程是:首先使用离线数据增强模块生成额外的训练数据,然后使用序列级梯度校正模块对on-policy rollout数据进行处理,最后使用处理后的数据进行模型训练。
关键创新:DaGRPO的关键创新在于区分性感知的梯度优化。它不是简单地使用所有样本进行训练,而是根据样本的区分性动态调整训练过程,从而更有效地利用数据,避免梯度冲突,并提高训练效率。与现有方法相比,DaGRPO能够更好地处理同质样本和困难样本,从而提高模型的推理能力。
关键设计:序列级梯度校正模块使用细粒度评分函数来计算样本对的区分性得分。该评分函数考虑了样本之间的语义相似性和逻辑一致性。区分性得分低于阈值的样本对将被屏蔽,不参与梯度计算。离线数据增强模块使用高质量的外部数据(例如,人工标注数据或专家系统生成的数据)作为锚点样本。这些锚点样本可以提供更强的训练信号,帮助模型学习更有效的推理策略。
🖼️ 关键图片
📊 实验亮点
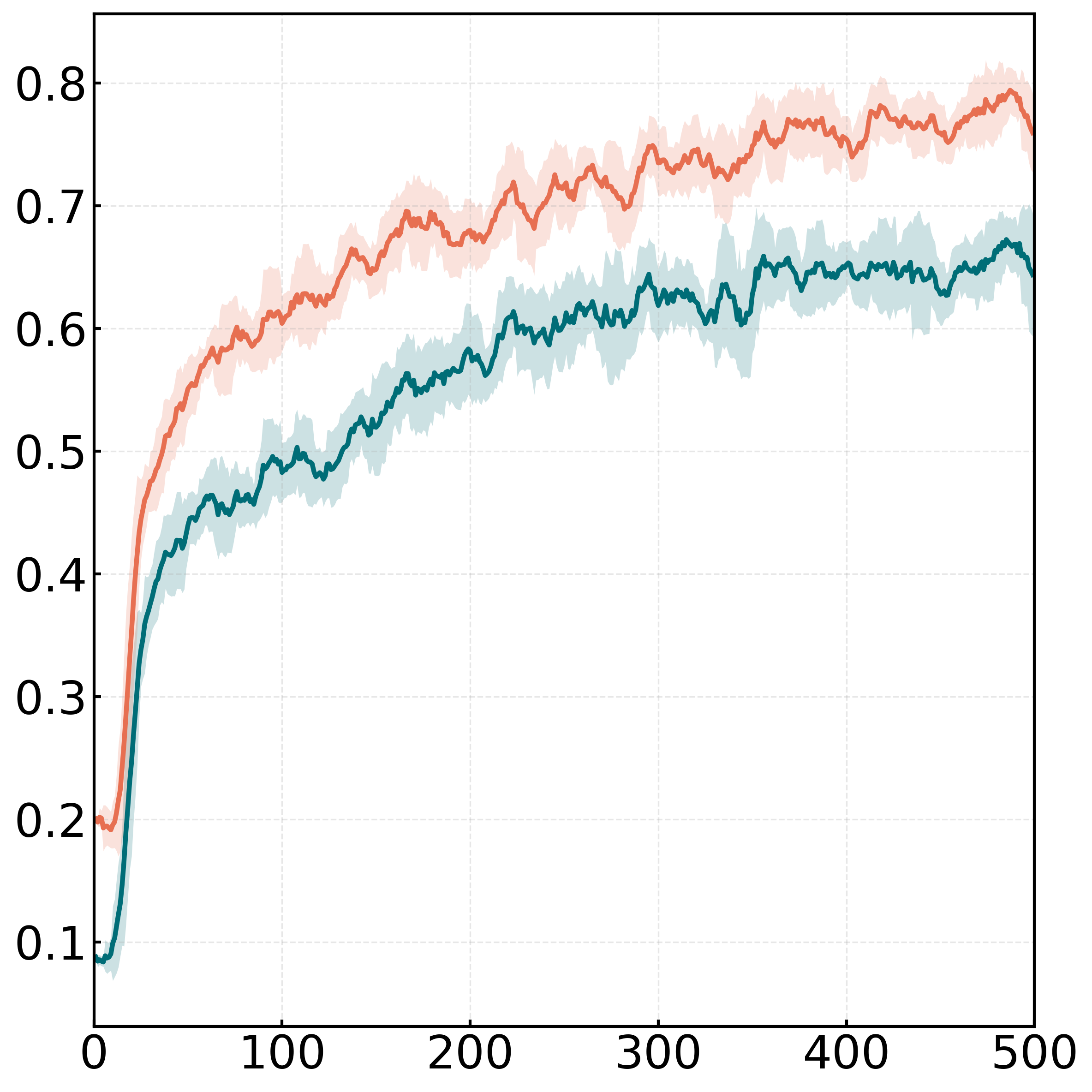
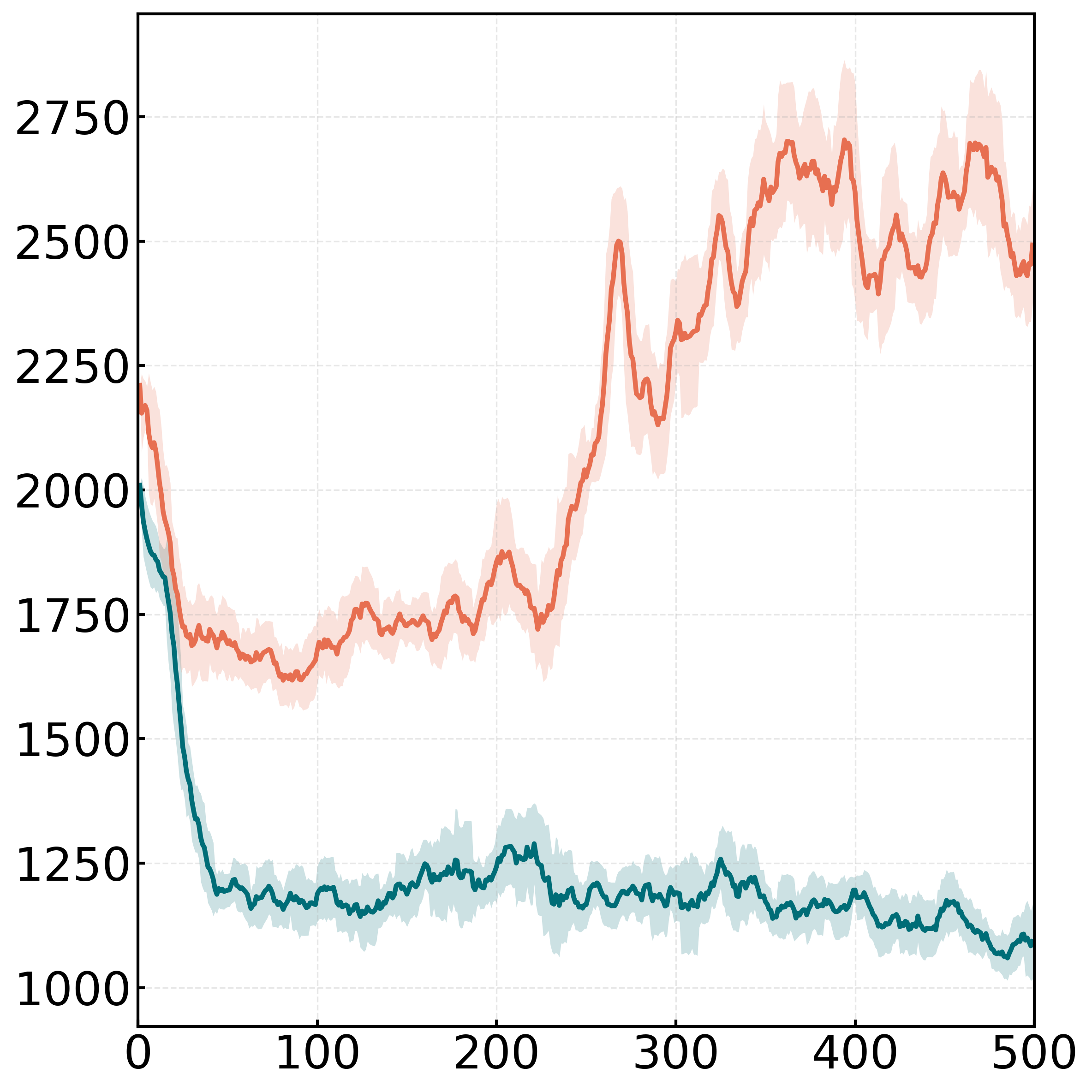
DaGRPO在9个数学推理和OOD泛化基准上取得了显著的性能提升。例如,在数学基准上,DaGRPO的平均准确率比现有最佳方法提高了4.7%。此外,实验结果表明,DaGRPO能够有效缓解梯度爆炸,并加速长链推理能力的出现。这些结果表明DaGRPO是一种有效的提高大型语言模型推理能力的方法。
🎯 应用场景
DaGRPO可应用于各种需要复杂推理能力的场景,例如数学问题求解、代码生成、知识图谱推理和对话系统。通过提高模型的推理能力和训练效率,DaGRPO可以帮助构建更智能、更可靠的人工智能系统,在教育、科研、金融等领域具有广泛的应用前景。
📄 摘要(原文)
The evolution of Large Language Models (LLMs) has catalyzed a paradigm shift from superficial instruction following to rigorous long-horizon reasoning. While Group Relative Policy Optimization (GRPO) has emerged as a pivotal mechanism for eliciting such post-training reasoning capabilities due to its exceptional performance, it remains plagued by significant training instability and poor sample efficiency. We theoretically identify the root cause of these issues as the lack of distinctiveness within on-policy rollouts: for routine queries, highly homogeneous samples induce destructive gradient conflicts; whereas for hard queries, the scarcity of valid positive samples results in ineffective optimization. To bridge this gap, we propose Distinctiveness-aware Group Relative Policy Optimization (DaGRPO). DaGRPO incorporates two core mechanisms: (1) Sequence-level Gradient Rectification, which utilizes fine-grained scoring to dynamically mask sample pairs with low distinctiveness, thereby eradicating gradient conflicts at the source; and (2) Off-policy Data Augmentation, which introduces high-quality anchors to recover training signals for challenging tasks. Extensive experiments across 9 mathematical reasoning and out-of-distribution (OOD) generalization benchmarks demonstrate that DaGRPO significantly surpasses existing SFT, GRPO, and hybrid baselines, achieving new state-of-the-art performance (e.g., a +4.7% average accuracy gain on math benchmarks). Furthermore, in-depth analysis confirms that DaGRPO effectively mitigates gradient explosion and accelerates the emergence of long-chain reasoning capabilities.