Degrading Voice: A Comprehensive Overview of Robust Voice Conversion Through Input Manipulation
作者: Xining Song, Zhihua Wei, Rui Wang, Haixiao Hu, Yanxiang Chen, Meng Han
分类: eess.AS, cs.AI, cs.CR, cs.SD
发布日期: 2025-12-06
💡 一句话要点
针对语音转换模型在噪声环境下的鲁棒性问题,提出一种基于输入扰动的全面评估框架。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 语音转换 鲁棒性 输入扰动 对抗攻击 语音增强
📋 核心要点
- 现有语音转换模型在干净数据上训练,缺乏对噪声、混响等真实场景退化语音的鲁棒性。
- 该论文从输入扰动的角度,对语音转换模型的鲁棒性进行全面评估,并对攻击和防御方法进行分类。
- 通过在可懂性、自然度、音色相似性和主观感知四个维度上评估,揭示了不同输入退化对语音转换模型的影响。
📝 摘要(中文)
语音的身份、口音、风格和情感是人类语音的重要组成部分。语音转换(VC)技术处理两个输入说话者的语音信号以及提示和情感标签等辅助信息的其他模态。它改变了从一个到另一个的超语言特征,同时保持了语言内容。最近,VC模型在生成质量和个性化能力方面都取得了快速进展。这些发展吸引了人们对各种应用的广泛关注,包括隐私保护、已故者的声纹复制和构音障碍语音恢复。然而,由于训练数据干净,这些模型只学习到非鲁棒的特征。因此,在现实场景中处理退化的输入语音时,包括额外的噪声、混响、对抗性攻击,甚至轻微的扰动,会导致不令人满意的性能。因此,它需要鲁棒的部署,尤其是在现实环境中。尽管最新的研究试图为VC系统找到潜在的攻击和对策,但在全面理解VC模型在输入操作下的鲁棒性方面仍然存在显著差距。这里也提出了许多问题:例如,不同形式的输入退化攻击在多大程度上改变了VC模型的预期输出?优化这些攻击和防御策略是否有潜力?为了回答这些问题,我们从输入操作的角度对现有的攻击和防御方法进行分类,并评估退化的输入语音在四个维度上的影响,包括可理解性、自然度、音色相似性和主观感知。最后,我们概述了未解决的问题和未来的方向。
🔬 方法详解
问题定义:语音转换(VC)模型在干净的训练数据上表现良好,但在实际应用中,输入语音常常受到噪声、混响、对抗攻击等因素的影响,导致性能显著下降。现有的研究缺乏对VC模型在各种输入退化情况下的鲁棒性的全面理解和评估,难以指导实际部署和应用。
核心思路:该论文的核心思路是从输入扰动的角度出发,系统地研究不同类型的输入退化对VC模型性能的影响。通过对现有的攻击和防御方法进行分类,并评估VC模型在不同退化情况下的表现,从而全面了解VC模型的鲁棒性,并为未来的研究提供指导。
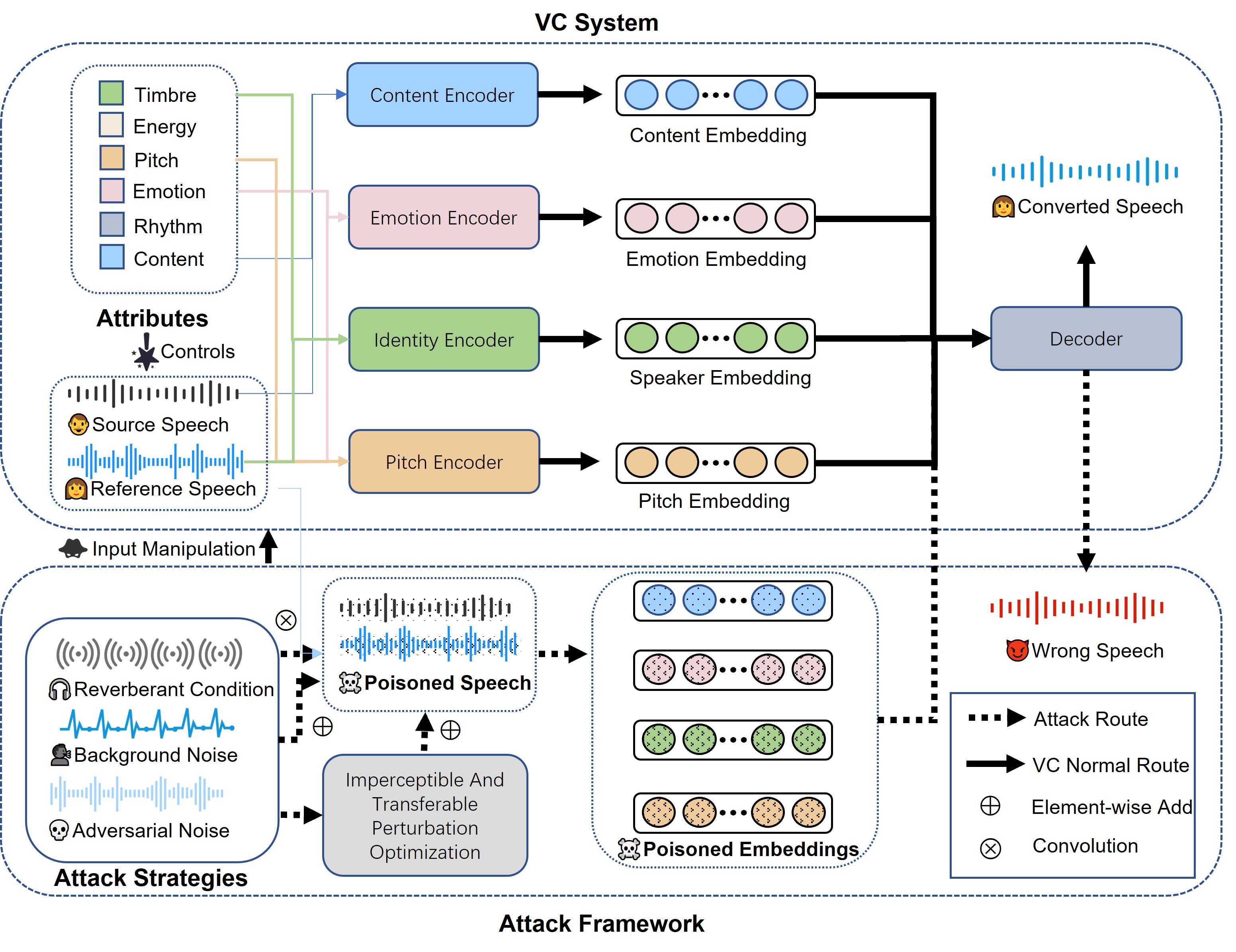
技术框架:该论文没有提出新的模型或算法,而是一个评估框架。该框架主要包含以下几个阶段:1) 对现有的攻击和防御方法进行分类,从输入操作的角度进行划分;2) 选择具有代表性的VC模型作为评估对象;3) 构建包含不同类型和程度的输入退化的测试数据集;4) 在可懂性、自然度、音色相似性和主观感知四个维度上评估VC模型的性能;5) 分析实验结果,总结VC模型在不同输入退化情况下的鲁棒性表现。
关键创新:该论文的主要创新在于提供了一个全面的语音转换模型鲁棒性评估框架,并从输入扰动的角度对现有的攻击和防御方法进行了系统分类。这有助于研究人员更好地理解VC模型的鲁棒性瓶颈,并为未来的研究提供指导。
关键设计:该论文的关键设计在于选择了四个维度(可懂性、自然度、音色相似性和主观感知)来评估VC模型的性能。这些维度涵盖了语音质量、语义信息和说话人特征等多个方面,能够全面反映VC模型的鲁棒性表现。此外,该论文还考虑了不同类型和程度的输入退化,从而能够更细致地分析VC模型在不同情况下的性能。
🖼️ 关键图片

📊 实验亮点
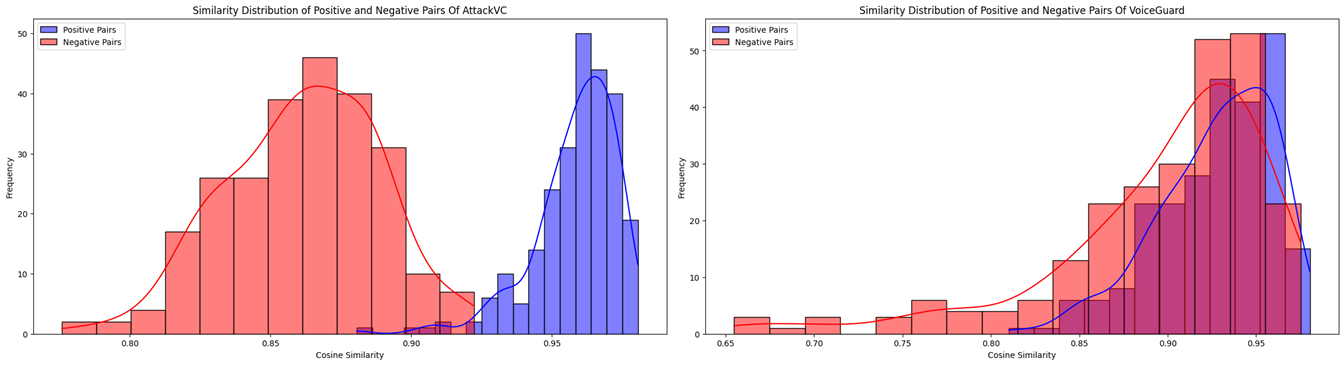
该论文通过实验评估了多种语音转换模型在不同输入退化情况下的性能,揭示了现有模型在噪声、混响和对抗攻击等方面的脆弱性。实验结果表明,即使是轻微的输入扰动也可能导致语音转换模型的性能显著下降,尤其是在可懂性和自然度方面。这些发现为未来的研究提供了重要的参考。
🎯 应用场景
该研究成果可应用于多种场景,例如:提升语音转换模型在噪声环境下的性能,使其在实际应用中更加可靠;为语音转换模型的安全性研究提供指导,帮助开发者设计更强的防御机制;应用于语音增强、语音识别等领域,提高这些系统在复杂环境下的鲁棒性。此外,该研究还有助于推动语音转换技术在隐私保护、声纹复制等领域的应用。
📄 摘要(原文)
Identity, accent, style, and emotions are essential components of human speech. Voice conversion (VC) techniques process the speech signals of two input speakers and other modalities of auxiliary information such as prompts and emotion tags. It changes para-linguistic features from one to another, while maintaining linguistic contents. Recently, VC models have made rapid advancements in both generation quality and personalization capabilities. These developments have attracted considerable attention for diverse applications, including privacy preservation, voice-print reproduction for the deceased, and dysarthric speech recovery. However, these models only learn non-robust features due to the clean training data. Subsequently, it results in unsatisfactory performances when dealing with degraded input speech in real-world scenarios, including additional noise, reverberation, adversarial attacks, or even minor perturbation. Hence, it demands robust deployments, especially in real-world settings. Although latest researches attempt to find potential attacks and countermeasures for VC systems, there remains a significant gap in the comprehensive understanding of how robust the VC model is under input manipulation. here also raises many questions: For instance, to what extent do different forms of input degradation attacks alter the expected output of VC models? Is there potential for optimizing these attack and defense strategies? To answer these questions, we classify existing attack and defense methods from the perspective of input manipulation and evaluate the impact of degraded input speech across four dimensions, including intelligibility, naturalness, timbre similarity, and subjective perception. Finally, we outline open issues and future directions.