MARINE: Theoretical Optimization and Design for Multi-Agent Recursive IN-context Enhancement
作者: Hongwei Zhang, Ji Lu, Yongsheng Du, Yanqin Gao, Lingjun Huang, Baoli Wang, Fang Tan, Peng Zou
分类: cs.MA, cs.AI
发布日期: 2025-12-05
💡 一句话要点
MARINE:多智能体递归上下文增强的理论优化与设计,提升LLM推理性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多智能体系统 上下文学习 递归推理 大语言模型 参数高效 迭代优化 推理增强
📋 核心要点
- 现有基于LLM的Agent推理能力受限于单次输出,未能充分发挥其性能潜力。
- MARINE框架将测试时推理视为对参考轨迹的迭代改进,实现接近最优的性能。
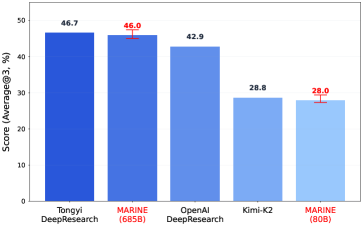
- 实验表明,MARINE在BrowserComp-ZH上达到SOTA,并显著降低了参数需求。
📝 摘要(中文)
本文提出了一种名为MARINE(多智能体递归上下文增强)的框架,它从理论上优化了测试时的推理过程。MARINE将推理重新概念化为对持久参考轨迹的迭代改进,这与传统的单次或多样本范式不同。MARINE的改进算子能够系统地将基础模型的pass@N能力转化为接近最优的pass@1性能。理论分析表明,在固定的调用预算下,最小可行批次能够最大化预期性能增益,而对数增长的批次调度能够确保在没有计算约束的情况下持续改进。在BrowserComp-ZH基准上的综合评估表明,MARINE达到了最先进的结果,一个685B参数的实现达到了46.0%的pass@1准确率。此外,MARINE建立了一种新的参数高效推理范式:一个配备MARINE的80B参数模型能够匹配独立1000B参数智能体的性能,从而将参数需求降低了一个数量级以上。值得注意的是,在固定的计算预算内,MARINE比传统的采样和排序策略向对齐和优化过程提供更高质量的样本,因此具有提高后训练效率的巨大潜力。
🔬 方法详解
问题定义:现有基于大型语言模型(LLM)的智能体虽然展现出强大的推理能力,但实际应用中常常受限于单次输出,导致其性能潜力无法充分发挥。传统的单次或多样本推理方法难以有效利用LLM的潜在能力,需要一种新的推理范式来提升性能。
核心思路:MARINE的核心思路是将测试时的推理过程重新定义为对一个持久参考轨迹的迭代改进。通过多个智能体协同工作,递归地优化和增强上下文信息,从而逐步逼近最优解。这种迭代改进的方式能够更有效地利用LLM的推理能力,并克服单次输出的局限性。
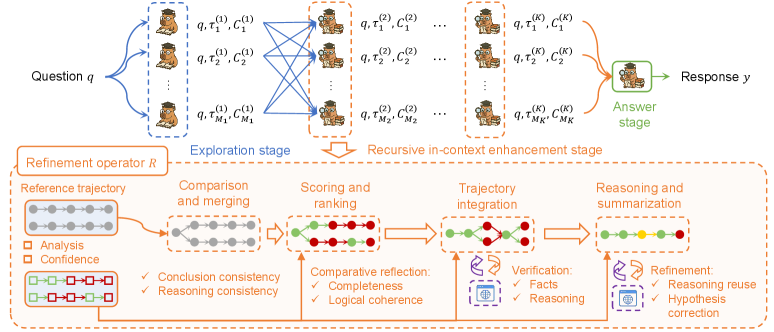
技术框架:MARINE框架包含以下主要模块:1) 初始化:使用基础模型生成初始参考轨迹。2) 多智能体协同:多个智能体基于当前参考轨迹并行生成候选解。3) 改进算子:使用改进算子对候选解进行评估和选择,更新参考轨迹。4) 递归迭代:重复多智能体协同和改进算子的过程,直到满足停止条件。整体流程是一个迭代优化的过程,通过不断改进参考轨迹来提升推理性能。
关键创新:MARINE最重要的技术创新点在于其递归上下文增强的推理范式。与传统的单次或多样本方法不同,MARINE通过迭代改进参考轨迹来逐步逼近最优解,从而更有效地利用LLM的推理能力。此外,MARINE还提出了理论指导下的批次调度策略,能够在固定的计算预算下最大化性能增益。
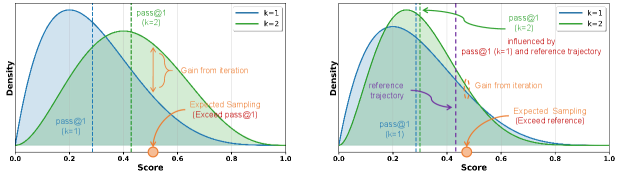
关键设计:MARINE的关键设计包括:1) 改进算子:改进算子的设计直接影响参考轨迹的更新效果,可以采用不同的评估指标和选择策略。2) 批次调度:批次调度策略决定了每次迭代中使用的智能体数量,需要根据计算预算和性能需求进行调整。论文的理论分析表明,最小可行批次能够最大化预期性能增益,而对数增长的批次调度能够确保持续改进。
🖼️ 关键图片
📊 实验亮点
MARINE在BrowserComp-ZH基准测试中取得了显著成果,一个685B参数的实现达到了46.0%的pass@1准确率,达到了SOTA水平。更重要的是,一个配备MARINE的80B参数模型能够匹配独立1000B参数智能体的性能,从而将参数需求降低了一个数量级以上,展示了其卓越的参数效率。
🎯 应用场景
MARINE框架可应用于各种需要复杂推理的任务,例如智能客服、代码生成、金融分析等。通过提升LLM的推理性能,MARINE能够提高这些应用的准确性和效率。此外,MARINE的参数高效性使其更易于部署在资源受限的环境中,具有广泛的应用前景。MARINE还能够提升后训练效率,降低模型对齐和优化的成本。
📄 摘要(原文)
Large Language Model (LLM)-based agents demonstrate advanced reasoning capabilities, yet practical constraints frequently limit outputs to single responses, leaving significant performance potential unrealized. This paper introduces MARINE (Multi-Agent Recursive IN-context Enhancement), a theoretically grounded framework that reconceptualizes test-time reasoning as iterative refinement of a persistent reference trajectory, fundamentally departing from conventional one-shot or multi-sample paradigms. The MARINE refinement operator systematically converts a base model's pass@N capabilities into near-optimal pass@1 performance. Rigorous theoretical analysis establishes that minimal feasible batches maximize expected performance gains under fixed invocation budgets, while logarithmically growing batch schedules ensure continuous improvement without computational constraints. Comprehensive evaluation on the BrowserComp-ZH benchmark demonstrates state-of-the-art results, with a 685B-parameter implementation achieving 46.0% pass@1 accuracy. Meanwhile, MARINE establishes a new paradigm for parameter-efficient reasoning: an 80B-parameter model augmented with MARINE matches the performance of standalone 1000B-parameter agents, reducing parameter requirements by over an order of magnitude. Notably, within a fixed computational budget, the proposed MARINE delivers higher-quality samples to alignment and optimization processes than traditional sampling-and-ranking strategies. Consequently, it has great potential to boost post-training efficiency.