ARCANE: A Multi-Agent Framework for Interpretable and Configurable Alignment
作者: Charlie Masters, Marta Grześkiewicz, Stefano V. Albrecht
分类: cs.AI, cs.CL
发布日期: 2025-12-05
备注: Accepted to the AAAI 2026 LLAMAS Workshop (Large Language Model Agents for Multi-Agent Systems)
💡 一句话要点
ARCANE框架通过多智能体协作实现可解释、可配置的对齐,解决长时程任务中偏好动态调整问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 对齐 多智能体 可解释性 自然语言规则 长时程任务
📋 核心要点
- 现有方法难以在长时程任务中保持智能体与利益相关者偏好的一致性,缺乏可解释性和动态调整能力。
- ARCANE框架将对齐问题建模为多智能体协作,使用自然语言规则动态表示利益相关者偏好,实现可解释的奖励模型。
- 实验表明,ARCANE框架学习到的规则紧凑易读,支持在测试时进行配置,无需重新训练即可实现偏好调整。
📝 摘要(中文)
随着基于大型语言模型的智能体越来越多地部署到长时程任务中,保持它们与利益相关者偏好的一致性变得至关重要。在这种环境中,有效的对齐需要可解释的奖励模型,以便利益相关者能够理解和审计模型目标。此外,奖励模型必须能够在交互时指导智能体,从而在无需重新训练的情况下整合偏好变化。我们提出了ARCANE,一个将对齐视为多智能体协作问题的框架,它动态地将利益相关者的偏好表示为自然语言规则:加权的可验证标准集,可以根据任务上下文即时生成。受效用理论的启发,我们将规则学习定义为一个重构问题,并应用一个正则化的Group-Sequence Policy Optimization (GSPO)过程,以平衡可解释性、保真度和计算效率。我们使用从GDPVal基准测试中导出的包含219个标记规则的语料库,在需要多步骤推理和工具使用的具有挑战性的任务上评估ARCANE。学习到的规则产生紧凑、易读的评估,并支持可配置的权衡(例如,正确性与简洁性),而无需重新训练。我们的结果表明,基于规则的奖励模型为复杂、长时程AI系统的可解释、测试时自适应对齐提供了一条有希望的途径。
🔬 方法详解
问题定义:论文旨在解决大型语言模型智能体在长时程任务中与利益相关者偏好对齐的问题。现有方法的痛点在于奖励模型缺乏可解释性,难以理解模型目标,并且无法在交互过程中动态调整偏好,需要重新训练。
核心思路:论文的核心思路是将对齐问题建模为多智能体协作问题。通过引入自然语言规则(rubrics)来动态表示利益相关者的偏好,这些规则是加权的可验证标准集,可以根据任务上下文即时生成。这种方法使得奖励模型更具可解释性,并且可以在测试时进行配置,从而实现偏好的动态调整。
技术框架:ARCANE框架的核心流程如下:首先,根据任务上下文生成自然语言规则,这些规则代表了利益相关者的偏好。然后,利用这些规则来评估智能体的行为,并生成奖励信号。智能体通过与环境交互,学习最大化基于规则的奖励。框架使用Group-Sequence Policy Optimization (GSPO)算法来优化策略,该算法在可解释性、保真度和计算效率之间进行平衡。
关键创新:ARCANE框架的关键创新在于使用自然语言规则来表示利益相关者的偏好,并将对齐问题建模为多智能体协作问题。这种方法使得奖励模型更具可解释性,并且可以在测试时进行配置,从而实现偏好的动态调整。此外,框架还引入了正则化的GSPO算法,以平衡可解释性、保真度和计算效率。
关键设计:论文使用GDPVal基准测试数据集,该数据集包含219个标记规则。规则学习被定义为一个重构问题,目标是重构利益相关者的偏好。GSPO算法使用正则化项来鼓励规则的简洁性和可解释性。具体的损失函数包括重构损失和正则化损失。网络结构方面,使用了Transformer模型来生成和评估规则。
🖼️ 关键图片
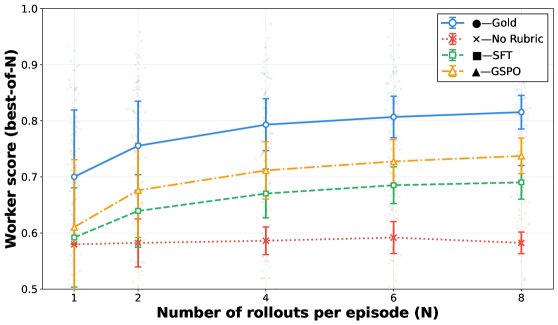
📊 实验亮点
实验结果表明,ARCANE框架学习到的规则紧凑易读,能够有效地表示利益相关者的偏好。在GDPVal基准测试中,ARCANE框架在多个指标上优于现有方法,例如,在规则的简洁性和可解释性方面取得了显著提升。此外,实验还证明了ARCANE框架可以在测试时进行配置,无需重新训练即可实现偏好调整。
🎯 应用场景
ARCANE框架可应用于各种需要智能体与人类偏好对齐的场景,例如:自动驾驶、医疗诊断、金融投资等。该研究的实际价值在于提高AI系统的可信度和可靠性,并促进人机协作。未来,该框架可以进一步扩展到更复杂的任务和更广泛的利益相关者群体,实现更灵活、更个性化的对齐。
📄 摘要(原文)
As agents based on large language models are increasingly deployed to long-horizon tasks, maintaining their alignment with stakeholder preferences becomes critical. Effective alignment in such settings requires reward models that are interpretable so that stakeholders can understand and audit model objectives. Moreover, reward models must be capable of steering agents at interaction time, allowing preference shifts to be incorporated without retraining. We introduce ARCANE, a framework that frames alignment as a multi-agent collaboration problem that dynamically represents stakeholder preferences as natural-language rubrics: weighted sets of verifiable criteria that can be generated on-the-fly from task context. Inspired by utility theory, we formulate rubric learning as a reconstruction problem and apply a regularized Group-Sequence Policy Optimization (GSPO) procedure that balances interpretability, faithfulness, and computational efficiency. Using a corpus of 219 labeled rubrics derived from the GDPVal benchmark, we evaluate ARCANE on challenging tasks requiring multi-step reasoning and tool use. The learned rubrics produce compact, legible evaluations and enable configurable trade-offs (e.g., correctness vs. conciseness) without retraining. Our results show that rubric-based reward models offer a promising path toward interpretable, test-time adaptive alignment for complex, long-horizon AI systems.