Variational Quantum Rainbow Deep Q-Network for Optimizing Resource Allocation Problem
作者: Truong Thanh Hung Nguyen, Truong Thinh Nguyen, Hung Cao
分类: cs.AI, cs.ET, cs.SE
发布日期: 2025-12-05
备注: Quantum Software Engineering Practices at The 41st ACM/SIGAPP Symposium On Applied Computing (SAC 2026)
🔗 代码/项目: GITHUB
💡 一句话要点
提出VQR-DQN,利用变分量子电路优化资源分配问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 量子强化学习 变分量子电路 资源分配 深度强化学习 组合优化
📋 核心要点
- 资源分配问题是NP难问题,传统深度强化学习方法在处理大规模问题时存在表示能力不足的挑战。
- VQR-DQN将变分量子电路集成到Rainbow DQN中,利用量子叠加和纠缠来增强策略的表达能力。
- 在人力资源分配问题上,VQR-DQN优于传统DRL方法,验证了量子增强DRL在资源分配中的潜力。
📝 摘要(中文)
资源分配由于其组合复杂性仍然是NP难问题。深度强化学习(DRL)方法,如Rainbow DQN,通过优先回放和分布头部提高了可扩展性,但经典函数逼近器的表示能力有限。我们引入了变分量子Rainbow DQN (VQR-DQN),它将环形拓扑变分量子电路与Rainbow DQN集成,以利用量子叠加和纠缠。我们将人力资源分配问题(HRAP)构建为马尔可夫决策过程(MDP),其组合动作空间基于人员能力、事件时间表和转移时间。在四个HRAP基准测试中,VQR-DQN实现了比随机基线降低26.8%的归一化完工时间,并且优于Double DQN和经典Rainbow DQN 4.9-13.4%。这些收益与电路可表达性、纠缠和策略质量之间的理论联系相符,证明了量子增强DRL在大型资源分配中的潜力。我们的实现可在https://github.com/Analytics-Everywhere-Lab/qtrl/上找到。
🔬 方法详解
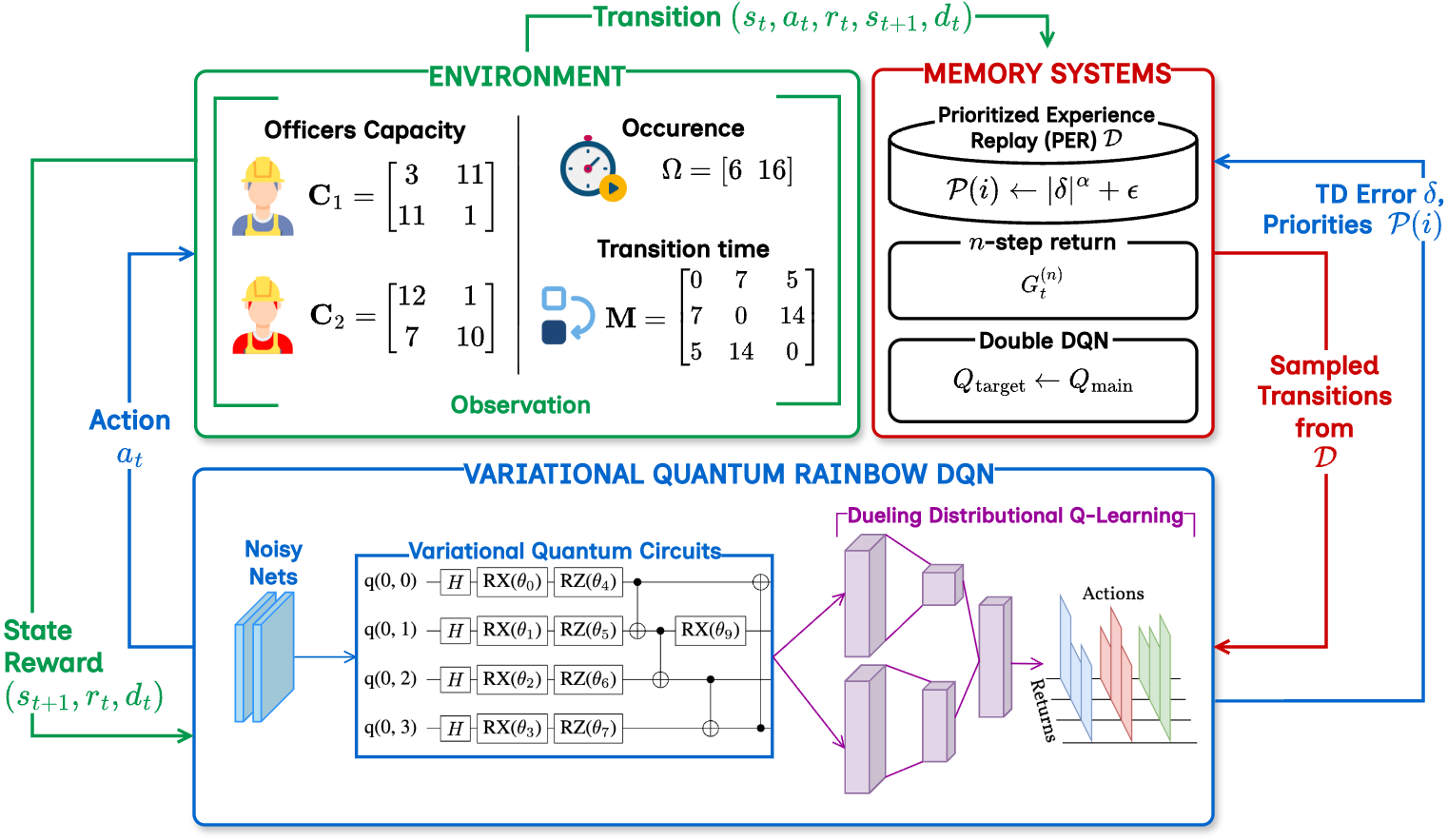
问题定义:论文旨在解决大规模人力资源分配问题(HRAP),这是一个NP难的组合优化问题。现有的深度强化学习方法,如Rainbow DQN,虽然在一定程度上提高了可扩展性,但由于其使用的经典函数逼近器(如神经网络)的表示能力有限,难以有效处理HRAP中巨大的动作空间和复杂的状态转移。
核心思路:论文的核心思路是利用量子计算的优势来增强DRL的表示能力。具体来说,通过将变分量子电路(VQC)集成到Rainbow DQN中,利用量子叠加和量子纠缠来更有效地表示和学习复杂的策略。VQC具有比经典神经网络更强的表达能力,能够更好地处理HRAP中的组合复杂性。
技术框架:VQR-DQN的整体框架是基于Rainbow DQN的。Rainbow DQN是一个先进的DRL算法,它结合了多种技术,如Double DQN、优先经验回放、分布Q学习等。VQR-DQN的关键改进在于将Rainbow DQN中的经典神经网络替换为变分量子电路(VQC)。整个流程包括:1) 使用VQC作为Q函数的逼近器;2) 使用Rainbow DQN的训练框架(包括经验回放、目标网络更新等)来训练VQC;3) 在HRAP环境中与智能体交互,收集经验数据;4) 使用收集到的经验数据来更新VQC的参数。
关键创新:最重要的技术创新点是将变分量子电路(VQC)引入到深度强化学习中,用于函数逼近。与传统的神经网络相比,VQC具有更强的表达能力,能够更好地处理组合优化问题。此外,论文还探索了VQC的电路结构(环形拓扑)与策略质量之间的关系,并验证了量子纠缠在提高策略性能方面的作用。
关键设计:VQR-DQN的关键设计包括:1) 使用环形拓扑的变分量子电路作为Q函数的逼近器。环形拓扑结构被认为能够更好地利用量子纠缠;2) 使用梯度下降法来优化VQC的参数。由于量子电路的输出是概率分布,因此需要使用特定的损失函数(如交叉熵损失)来衡量预测值与目标值之间的差距;3) 将HRAP建模为马尔可夫决策过程(MDP),并定义了状态空间、动作空间和奖励函数。动作空间基于人员能力、事件时间表和转移时间。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在四个人力资源分配问题(HRAP)基准测试中,VQR-DQN相对于随机基线实现了26.8%的归一化完工时间减少。此外,VQR-DQN的性能优于Double DQN和经典Rainbow DQN,分别提升了4.9-13.4%。这些结果验证了VQR-DQN在解决资源分配问题方面的有效性,并表明量子增强DRL具有巨大的潜力。
🎯 应用场景
VQR-DQN在资源分配领域具有广泛的应用前景,例如人力资源调度、车辆路径规划、云计算资源管理等。该方法能够有效地处理大规模、高复杂度的组合优化问题,提高资源利用率,降低成本。未来,VQR-DQN可以进一步扩展到其他领域,如金融投资、智能制造等,为解决实际问题提供新的思路和方法。
📄 摘要(原文)
Resource allocation remains NP-hard due to combinatorial complexity. While deep reinforcement learning (DRL) methods, such as the Rainbow Deep Q-Network (DQN), improve scalability through prioritized replay and distributional heads, classical function approximators limit their representational power. We introduce Variational Quantum Rainbow DQN (VQR-DQN), which integrates ring-topology variational quantum circuits with Rainbow DQN to leverage quantum superposition and entanglement. We frame the human resource allocation problem (HRAP) as a Markov decision process (MDP) with combinatorial action spaces based on officer capabilities, event schedules, and transition times. On four HRAP benchmarks, VQR-DQN achieves 26.8% normalized makespan reduction versus random baselines and outperforms Double DQN and classical Rainbow DQN by 4.9-13.4%. These gains align with theoretical connections between circuit expressibility, entanglement, and policy quality, demonstrating the potential of quantum-enhanced DRL for large-scale resource allocation. Our implementation is available at: https://github.com/Analytics-Everywhere-Lab/qtrl/.