PRiSM: An Agentic Multimodal Benchmark for Scientific Reasoning via Python-Grounded Evaluation
作者: Shima Imani, Seungwhan Moon, Adel Ahmadyan, Lu Zhang, Kirmani Ahmed, Babak Damavandi
分类: cs.AI
发布日期: 2025-12-05
💡 一句话要点
提出PRiSM:一个基于Python代码执行评估的多模态科学推理Agent基准。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 科学推理 视觉语言模型 多模态学习 Python代码执行 基准测试
📋 核心要点
- 现有视觉语言模型在科学领域的评估缺乏中间推理步骤、鲁棒性以及验证机制,难以评估其深层理解能力。
- PRiSM通过动态生成文本和视觉输入,并结合可执行的Python代码进行真值验证,实现对科学推理过程的细粒度评估。
- 实验结果表明,现有VLM在PRiSM基准上表现出局限性,该基准能够有效揭示其在泛化、鲁棒性等方面的不足。
📝 摘要(中文)
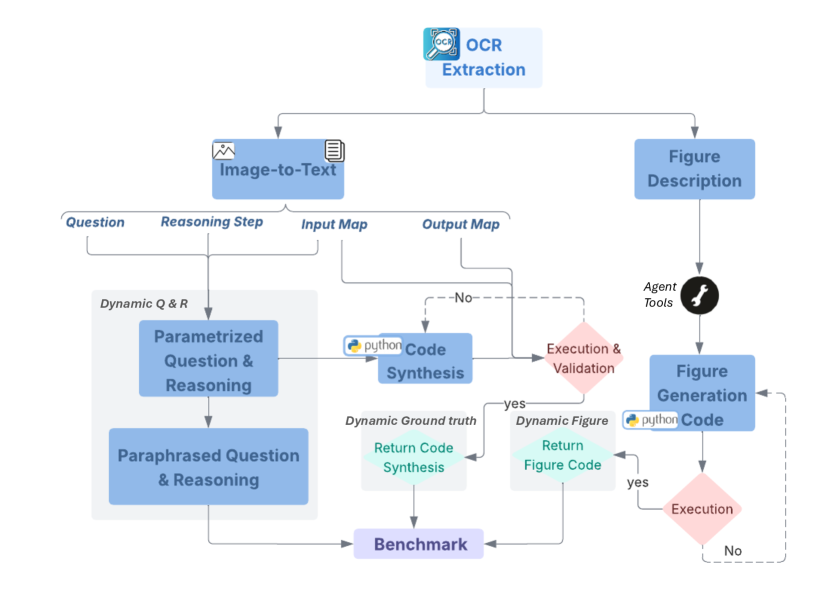
本文提出了PRiSM,一个合成的、完全动态的、多模态的基准,用于评估基于Python代码执行的科学推理能力。PRiSM包含超过24750个大学水平的物理和数学问题,并利用可扩展的基于Agent的流程PrismAgent生成结构良好的问题实例。每个问题包含动态的文本和视觉输入、生成的图表,以及丰富的结构化输出:用于生成和验证真值的可执行Python代码,以及详细的逐步推理过程。该基准的动态特性和Python驱动的自动真值生成,允许对多模态视觉语言模型(VLM)进行细粒度的实验审计,揭示其失效模式、不确定性行为和科学推理的局限性。为此,我们提出了五个有针对性的评估任务,涵盖泛化、符号程序合成、扰动鲁棒性、推理校正和歧义消除。通过对现有VLM的全面评估,我们强调了它们的局限性,并展示了PRiSM如何能够更深入地了解它们的科学推理能力。
🔬 方法详解
问题定义:现有视觉语言模型(VLM)在数学和物理等科学领域的评估中,仅仅预测最终答案是不够的。更重要的是,需要评估模型对概念的理解、符号推理能力以及对形式化规则的遵循程度。现有的数据集往往是静态的,缺乏中间推理步骤,对输入变化不够鲁棒,并且缺乏验证科学正确性的机制。因此,如何构建一个能够全面评估VLM在科学领域推理能力的基准是一个关键问题。
核心思路:PRiSM的核心思路是构建一个动态的、多模态的基准,其中问题实例是动态生成的,并且包含可执行的Python代码用于生成和验证真值。通过这种方式,可以对VLM的推理过程进行细粒度的审计,从而揭示其失效模式和局限性。利用Python代码作为ground truth,保证了科学上的正确性,并允许对推理过程进行精确控制和验证。
技术框架:PRiSM的整体框架包含以下几个主要组成部分:1) PrismAgent:一个可扩展的基于Agent的流程,用于生成结构良好的问题实例。2) 问题生成器:负责生成包含动态文本和视觉输入的问题,以及相应的图表。3) Python代码生成器:负责生成可执行的Python代码,用于生成真值和验证推理过程。4) 评估模块:包含五个有针对性的评估任务,涵盖泛化、符号程序合成、扰动鲁棒性、推理校正和歧义消除。
关键创新:PRiSM最重要的创新点在于其动态性和基于Python代码的真值生成机制。传统的基准数据集通常是静态的,难以覆盖各种可能的输入变化。而PRiSM通过动态生成问题实例,可以更好地评估VLM的泛化能力和鲁棒性。此外,使用Python代码作为真值,可以确保科学上的正确性,并允许对推理过程进行精确控制和验证。这与现有方法中依赖人工标注或简单规则的方法有本质区别。
关键设计:PRiSM的关键设计包括:1) PrismAgent的设计,确保能够生成高质量的问题实例。2) Python代码生成器的设计,需要能够生成正确且可执行的代码。3) 五个评估任务的设计,需要能够全面评估VLM的科学推理能力。具体参数设置、损失函数和网络结构等细节取决于被评估的VLM。
🖼️ 关键图片


📊 实验亮点
实验结果表明,现有VLM在PRiSM基准上表现出明显的局限性,尤其是在符号程序合成、扰动鲁棒性和推理校正等方面。例如,在扰动鲁棒性测试中,VLM的性能显著下降,表明其对输入变化的敏感性。PRiSM能够有效揭示这些局限性,并为改进VLM的科学推理能力提供指导。
🎯 应用场景
PRiSM基准的潜在应用领域包括:提升视觉语言模型在科学教育、科研辅助、自动化问题求解等方面的能力。通过更精确地评估和改进模型的科学推理能力,可以开发出更智能的科学助手,辅助科学家进行研究,并为学生提供更有效的学习工具。未来,该基准可以扩展到其他科学领域,例如化学、生物学等。
📄 摘要(原文)
Evaluating vision-language models (VLMs) in scientific domains like mathematics and physics poses unique challenges that go far beyond predicting final answers. These domains demand conceptual understanding, symbolic reasoning, and adherence to formal laws, requirements that most existing benchmarks fail to address. In particular, current datasets tend to be static, lacking intermediate reasoning steps, robustness to variations, or mechanisms for verifying scientific correctness. To address these limitations, we introduce PRiSM, a synthetic, fully dynamic, and multimodal benchmark for evaluating scientific reasoning via grounded Python code. PRiSM includes over 24,750 university-level physics and math problems, and it leverages our scalable agent-based pipeline, PrismAgent, to generate well-structured problem instances. Each problem contains dynamic textual and visual input, a generated figure, alongside rich structured outputs: executable Python code for ground truth generation and verification, and detailed step-by-step reasoning. The dynamic nature and Python-powered automated ground truth generation of our benchmark allow for fine-grained experimental auditing of multimodal VLMs, revealing failure modes, uncertainty behaviors, and limitations in scientific reasoning. To this end, we propose five targeted evaluation tasks covering generalization, symbolic program synthesis, perturbation robustness, reasoning correction, and ambiguity resolution. Through comprehensive evaluation of existing VLMs, we highlight their limitations and showcase how PRiSM enables deeper insights into their scientific reasoning capabilities.