Ontology Learning with LLMs: A Benchmark Study on Axiom Identification
作者: Roos M. Bakker, Daan L. Di Scala, Maaike H. T. de Boer, Stephan A. Raaijmakers
分类: cs.AI, cs.CL
发布日期: 2025-12-05
备注: Submitted to Semantic Web Journal, under review
💡 一句话要点
OntoAxiom基准测试揭示LLM在公理识别中的潜力与局限,为本体工程提供支持。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 本体学习 大型语言模型 公理识别 知识图谱 基准测试
📋 核心要点
- 本体构建复杂且耗时,需要领域专家参与,现有方法难以自动化。
- 提出OntoAxiom基准测试,系统评估LLM在公理识别任务中的能力,探索不同提示策略的影响。
- 实验表明逐个公理提示策略更有效,但性能受公理类型和领域影响,大型LLM表现更优。
📝 摘要(中文)
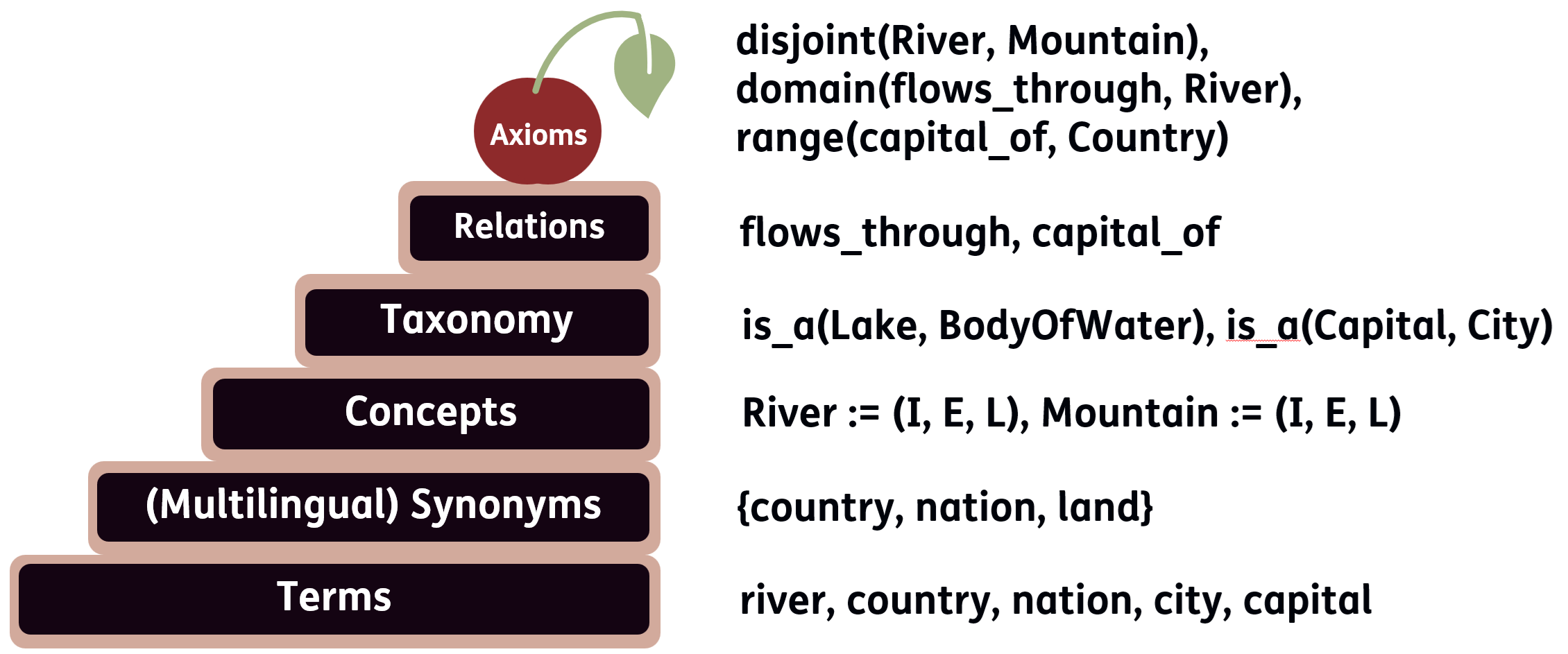
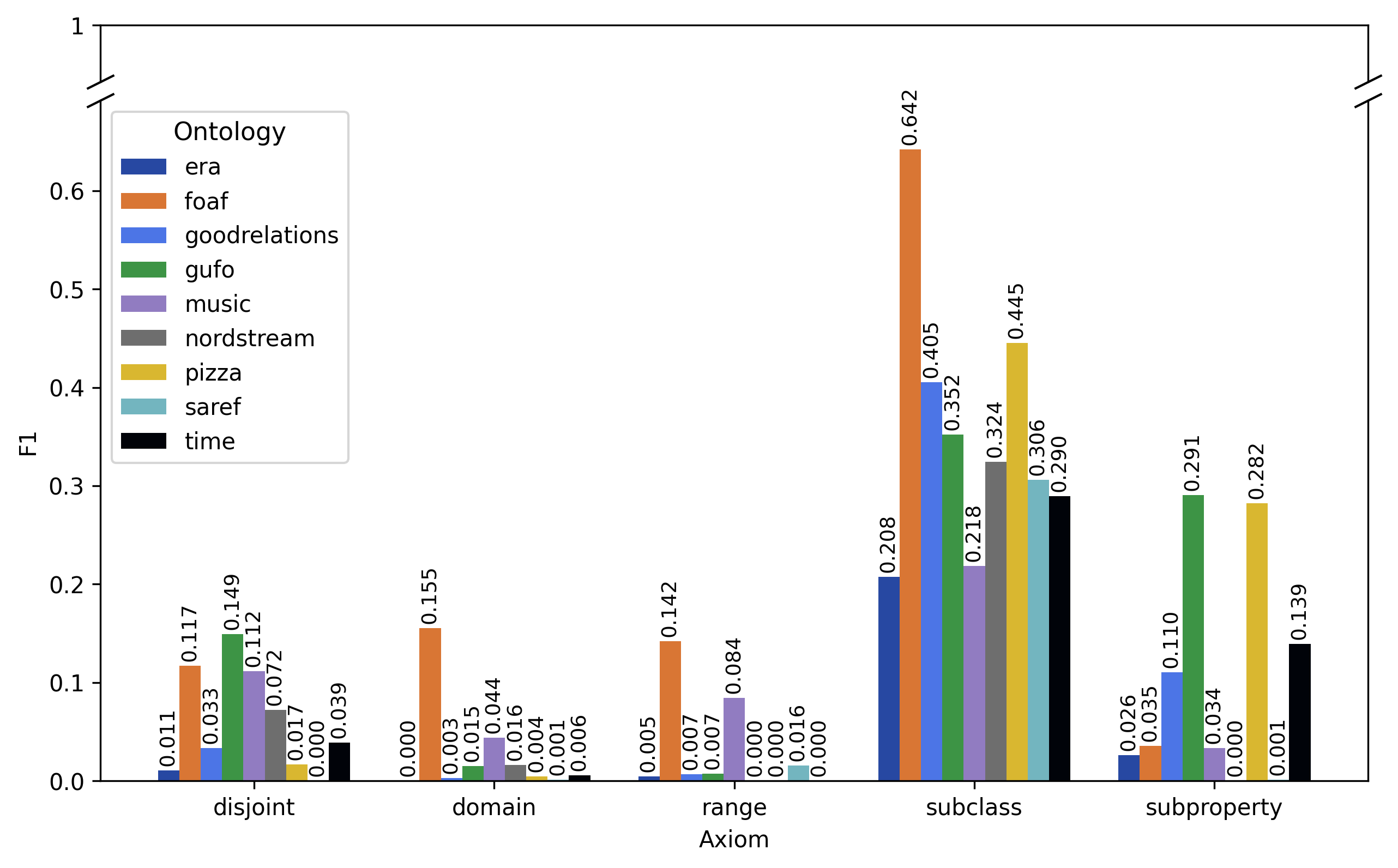
本体是构建领域知识的重要工具,但其开发需要专业的建模和领域知识。本体学习旨在自动化这一过程,近年来随着自然语言处理技术的进步,特别是大型语言模型(LLM)的快速发展,取得了显著进展。本文研究了公理识别这一难题,公理是定义类和属性之间逻辑关系的基本本体组件。我们提出了一个本体公理基准OntoAxiom,并系统地测试了LLM在该基准上的公理识别能力,评估了不同的提示策略、本体和公理类型。该基准包含九个中等规模的本体,共计17118个三元组和2771个公理。我们重点关注子类、不相交、子属性、域和范围公理。为了评估LLM的性能,我们比较了十二个LLM,采用了三种shot设置和两种提示策略:直接方法(一次查询所有公理)和逐个公理(AbA)方法(每次提示仅查询一个公理)。结果表明,AbA提示策略的F1分数高于直接方法。然而,不同公理的性能差异很大,表明某些公理更难识别。领域也会影响性能:FOAF本体的子类公理得分为0.642,而音乐本体仅为0.218。较大的LLM优于较小的LLM,但较小的模型在资源受限的环境中仍然可行。虽然总体性能不足以完全自动化公理识别,但LLM可以提供有价值的候选公理,以支持本体工程师开发和改进本体。
🔬 方法详解
问题定义:论文旨在解决本体学习中公理识别的自动化问题。现有本体构建方法依赖人工,成本高昂且效率低下。现有方法无法有效利用LLM进行公理识别,缺乏系统性的评估和优化。
核心思路:论文的核心思路是利用LLM的知识推理能力,通过设计合适的提示策略,使其能够从本体数据中识别出公理。通过构建OntoAxiom基准测试,系统评估不同LLM和提示策略在公理识别任务中的性能,从而为本体工程提供支持。
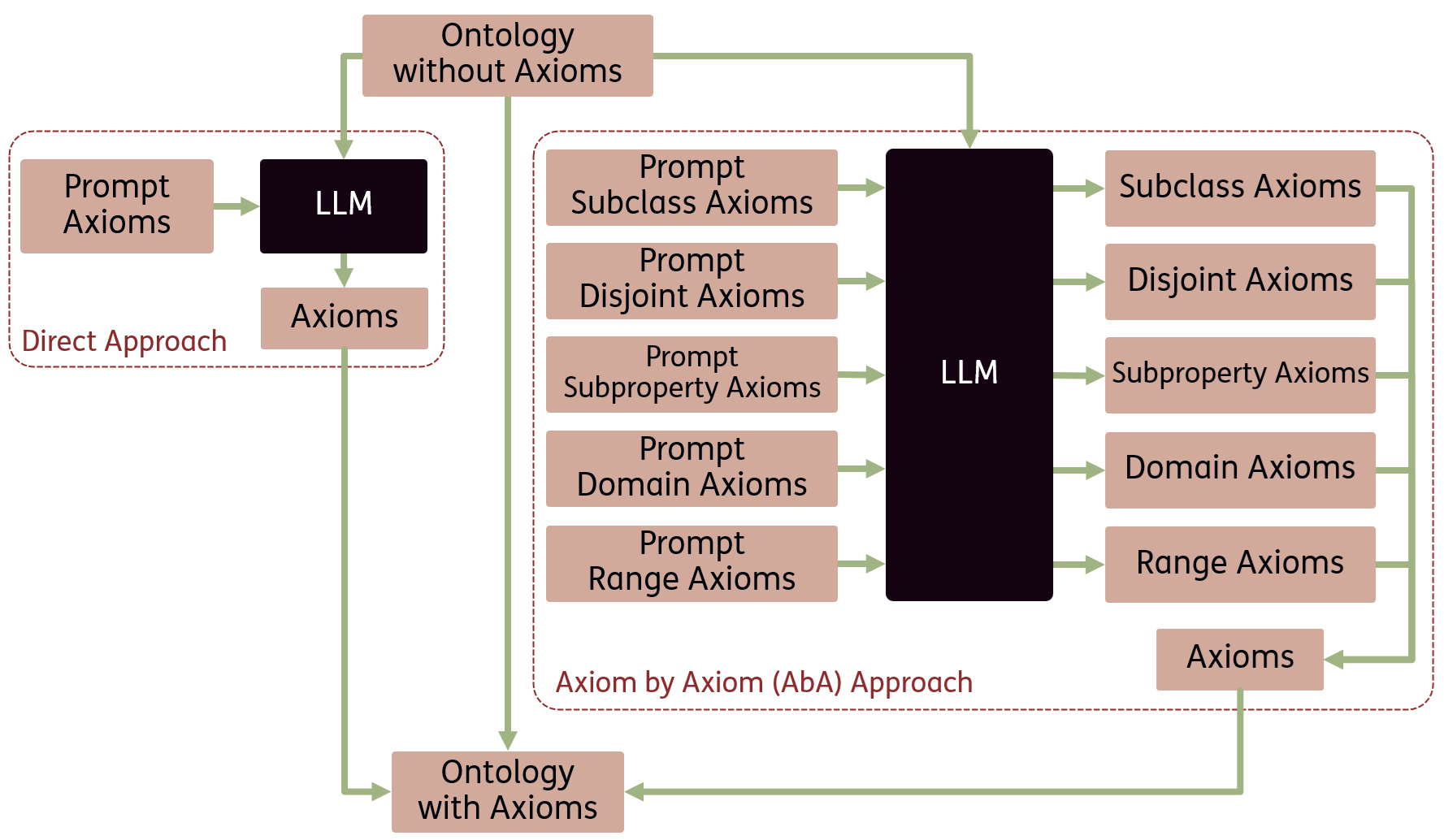
技术框架:论文的技术框架主要包括以下几个部分: 1. OntoAxiom基准测试:包含九个中等规模的本体,涵盖子类、不相交、子属性、域和范围等多种公理类型。 2. LLM选择:选择了十二个不同规模的LLM进行评估。 3. 提示策略:设计了两种提示策略,即直接方法(一次查询所有公理)和逐个公理(AbA)方法(每次提示仅查询一个公理)。 4. 评估指标:采用F1分数作为评估指标,衡量LLM在公理识别任务中的性能。
关键创新:论文的关键创新在于: 1. OntoAxiom基准测试:构建了一个专门用于评估LLM在公理识别任务中的性能的基准测试。 2. 逐个公理提示策略:提出了一种逐个公理的提示策略,相比于直接方法,能够显著提高LLM在公理识别任务中的性能。
关键设计:论文的关键设计包括: 1. 提示模板设计:针对不同的公理类型,设计了不同的提示模板,以引导LLM进行公理识别。 2. Shot设置:采用了三种shot设置(zero-shot, one-shot, three-shot),以评估LLM在不同知识储备下的性能。 3. LLM选择:选择了不同规模的LLM,以评估模型规模对公理识别性能的影响。
🖼️ 关键图片
📊 实验亮点
实验结果表明,逐个公理(AbA)提示策略的F1分数高于直接方法。FOAF本体的子类公理得分为0.642,而音乐本体仅为0.218,表明领域知识对性能有显著影响。较大的LLM通常优于较小的LLM,但较小的模型在资源受限的环境中仍然具有可行性。
🎯 应用场景
该研究成果可应用于自动化本体构建、知识图谱补全、语义搜索等领域。通过利用LLM辅助本体工程师进行公理识别,可以显著降低本体构建的成本和时间,提高本体的质量和可用性。未来,该研究可以进一步扩展到其他本体学习任务,例如概念分类、关系抽取等。
📄 摘要(原文)
Ontologies are an important tool for structuring domain knowledge, but their development is a complex task that requires significant modelling and domain expertise. Ontology learning, aimed at automating this process, has seen advancements in the past decade with the improvement of Natural Language Processing techniques, and especially with the recent growth of Large Language Models (LLMs). This paper investigates the challenge of identifying axioms: fundamental ontology components that define logical relations between classes and properties. In this work, we introduce an Ontology Axiom Benchmark OntoAxiom, and systematically test LLMs on that benchmark for axiom identification, evaluating different prompting strategies, ontologies, and axiom types. The benchmark consists of nine medium-sized ontologies with together 17.118 triples, and 2.771 axioms. We focus on subclass, disjoint, subproperty, domain, and range axioms. To evaluate LLM performance, we compare twelve LLMs with three shot settings and two prompting strategies: a Direct approach where we query all axioms at once, versus an Axiom-by-Axiom (AbA) approach, where each prompt queries for one axiom only. Our findings show that the AbA prompting leads to higher F1 scores than the direct approach. However, performance varies across axioms, suggesting that certain axioms are more challenging to identify. The domain also influences performance: the FOAF ontology achieves a score of 0.642 for the subclass axiom, while the music ontology reaches only 0.218. Larger LLMs outperform smaller ones, but smaller models may still be viable for resource-constrained settings. Although performance overall is not high enough to fully automate axiom identification, LLMs can provide valuable candidate axioms to support ontology engineers with the development and refinement of ontologies.