Lyrics Matter: Exploiting the Power of Learnt Representations for Music Popularity Prediction
作者: Yash Choudhary, Preeti Rao, Pushpak Bhattacharyya
分类: cs.SD, cs.AI, cs.LG
发布日期: 2025-12-05
备注: 8 pages
💡 一句话要点
提出HitMusicLyricNet,利用LLM歌词嵌入提升音乐流行度预测精度。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音乐流行度预测 歌词嵌入 大型语言模型 多模态融合 深度学习
📋 核心要点
- 现有音乐流行度预测方法主要依赖音频特征和社交数据,忽略了歌词中蕴含的丰富信息。
- 论文提出利用大型语言模型(LLM)提取歌词的深层语义特征,并融入多模态预测模型。
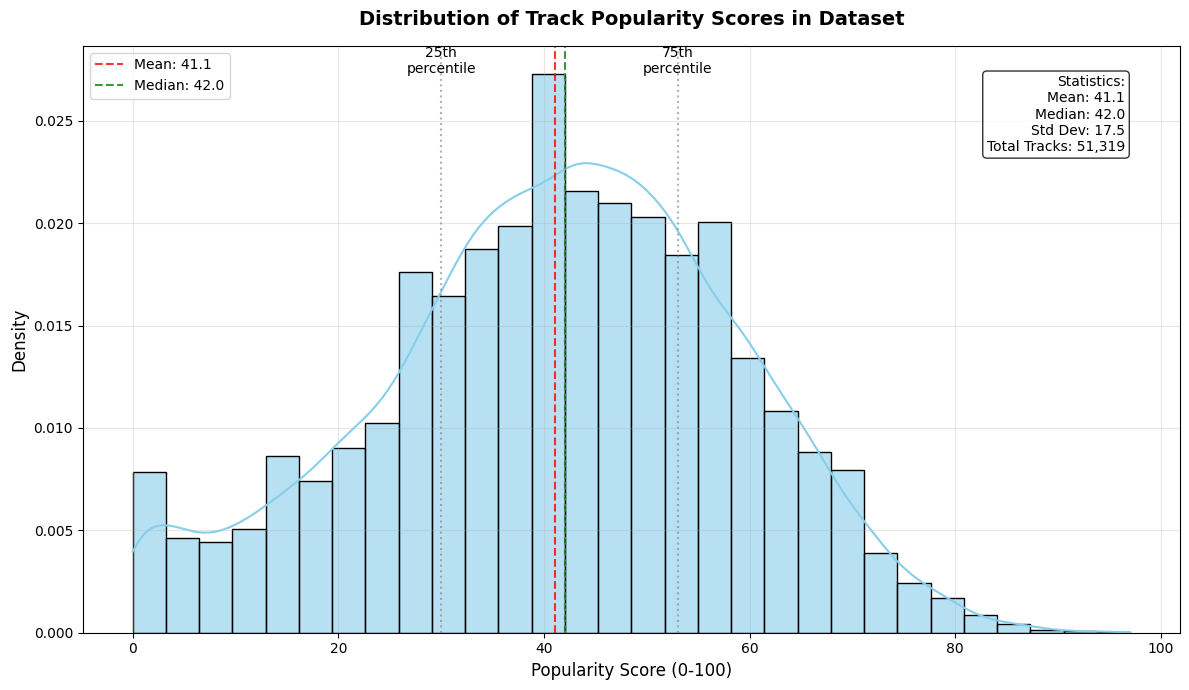
- 实验表明,该方法在SpotGenTrack数据集上显著提升了音乐流行度预测的准确性,MAE和MSE分别提高了9%和20%。
📝 摘要(中文)
准确预测音乐流行度是音乐产业的关键挑战,对艺术家、制作人和流媒体平台都有益处。以往研究主要集中在音频特征、社交元数据或模型架构上。本文着重研究了歌词在预测流行度方面被低估的作用。我们提出了一个自动化流程,使用LLM提取高维歌词嵌入,捕捉语义、句法和序列信息。这些特征被整合到HitMusicLyricNet中,这是一个多模态架构,结合了音频、歌词和社交元数据,用于预测0-100范围内的流行度评分。我们的方法在包含超过10万首歌曲的SpotGenTrack数据集上优于现有基线,MAE和MSE分别提高了9%和20%。消融实验证实,性能提升源于我们基于LLM的歌词特征流程(LyricsAENet),突显了密集歌词表示的价值。
🔬 方法详解
问题定义:音乐流行度预测旨在量化歌曲的受欢迎程度,对音乐产业具有重要价值。现有方法主要依赖音频特征和社交元数据,忽略了歌词所蕴含的丰富语义信息。如何有效利用歌词信息,提升音乐流行度预测的准确性,是本文要解决的问题。
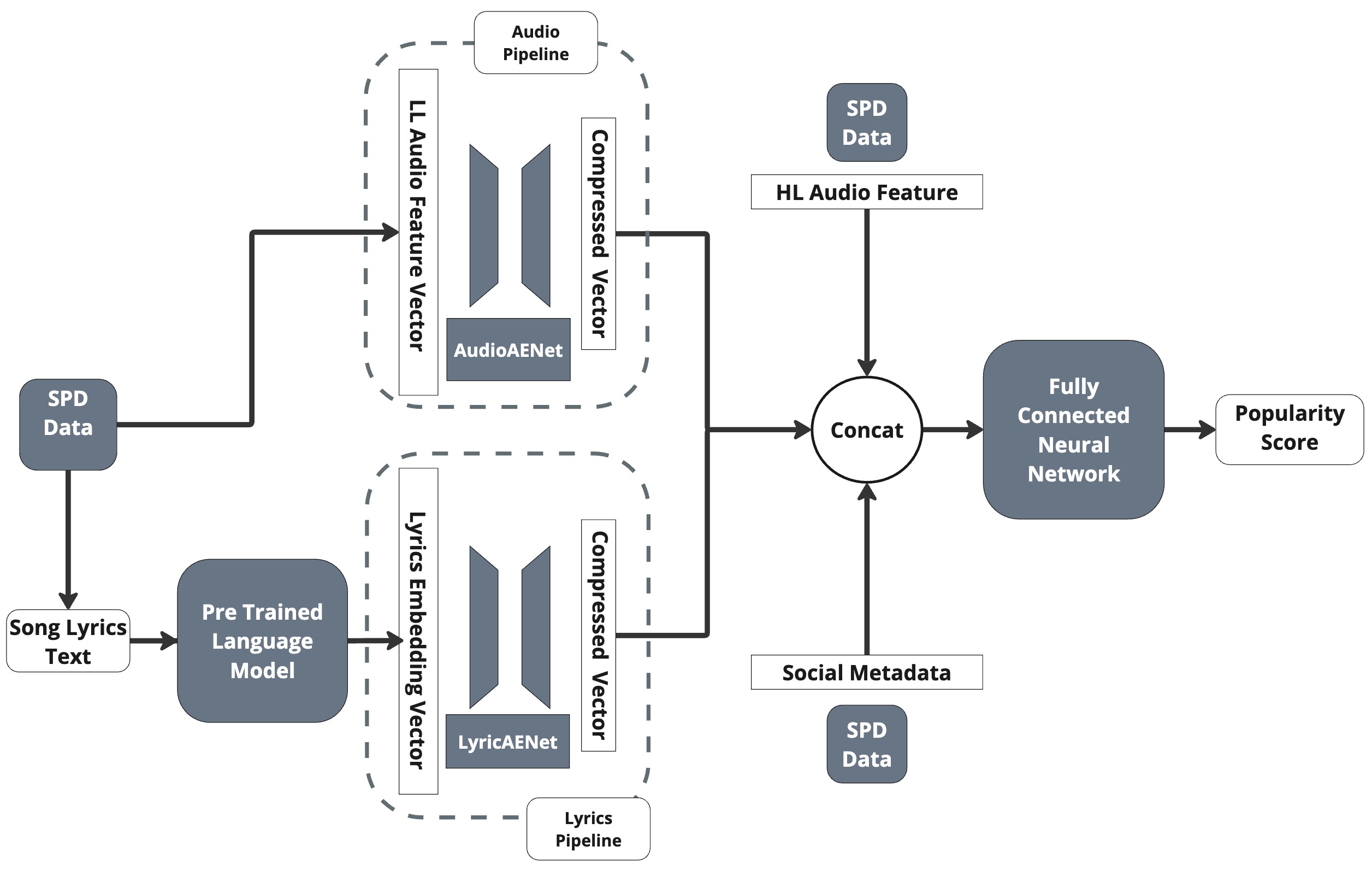
核心思路:论文的核心思路是利用大型语言模型(LLM)学习歌词的深层表示,捕捉歌词的语义、句法和序列信息。通过将这些歌词嵌入与音频特征和社交元数据相结合,可以更全面地理解歌曲的特征,从而提高流行度预测的准确性。
技术框架:论文提出的HitMusicLyricNet是一个多模态架构,包含以下主要模块:1) LyricsAENet:使用LLM提取歌词嵌入;2) 音频特征提取模块:提取歌曲的音频特征;3) 社交元数据模块:获取歌曲的社交数据,如播放量、点赞数等;4) 融合模块:将歌词嵌入、音频特征和社交元数据进行融合;5) 预测模块:根据融合后的特征预测歌曲的流行度评分。
关键创新:论文的关键创新在于提出了LyricsAENet,利用LLM自动学习歌词的深层表示。与传统的词袋模型或TF-IDF等方法相比,LLM能够更好地捕捉歌词的语义信息和上下文关系,从而生成更具表达力的歌词嵌入。
关键设计:论文使用预训练的LLM(具体模型未知)来提取歌词嵌入。损失函数采用均方误差(MSE)和平均绝对误差(MAE)的组合。网络结构细节(如层数、神经元数量等)未知。训练过程采用SpotGenTrack数据集,包含超过10万首歌曲。
🖼️ 关键图片

📊 实验亮点
实验结果表明,HitMusicLyricNet在SpotGenTrack数据集上显著优于现有基线方法,MAE降低了9%,MSE降低了20%。消融实验证实,性能提升主要归功于LyricsAENet,突显了LLM歌词嵌入的有效性。这些结果表明,歌词信息在音乐流行度预测中具有重要作用。
🎯 应用场景
该研究成果可应用于音乐推荐系统,帮助用户发现更符合其口味的音乐;也可用于音乐制作和发行,为艺术家和制作人提供市场趋势分析,辅助创作更受欢迎的音乐作品;还可用于音乐版权管理,评估歌曲的商业价值。
📄 摘要(原文)
Accurately predicting music popularity is a critical challenge in the music industry, offering benefits to artists, producers, and streaming platforms. Prior research has largely focused on audio features, social metadata, or model architectures. This work addresses the under-explored role of lyrics in predicting popularity. We present an automated pipeline that uses LLM to extract high-dimensional lyric embeddings, capturing semantic, syntactic, and sequential information. These features are integrated into HitMusicLyricNet, a multimodal architecture that combines audio, lyrics, and social metadata for popularity score prediction in the range 0-100. Our method outperforms existing baselines on the SpotGenTrack dataset, which contains over 100,000 tracks, achieving 9% and 20% improvements in MAE and MSE, respectively. Ablation confirms that gains arise from our LLM-driven lyrics feature pipeline (LyricsAENet), underscoring the value of dense lyric representations.