Knowing Your Uncertainty -- On the application of LLM in social sciences
作者: Bolun Zhang, Linzhuo Li, Yunqi Chen, Qinlin Zhao, Zihan Zhu, Xiaoyuan Yi, Xing Xie
分类: cs.CY, cs.AI, cs.HC
发布日期: 2025-12-05
备注: 49 pages, 10 figures
💡 一句话要点
提出LLM不确定性评估框架,助力其在社会科学中的可靠应用
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 不确定性量化 社会科学 任务类型 验证类型
📋 核心要点
- LLM在社会科学应用中面临黑盒特性和随机性带来的不确定性挑战。
- 论文提出T-V框架,从任务类型和验证类型两个维度评估LLM的不确定性。
- 该框架将现有不确定性量化方法映射到T-V类型学中,为研究提供实践指导。
📝 摘要(中文)
大型语言模型(LLM)正迅速融入计算社会科学研究,但其黑盒训练和推理中固有的随机性为科学探究带来了独特的挑战。本文认为,将LLM应用于社会科学任务需要明确评估其不确定性,这既是社会科学定量方法论也是机器学习领域长期以来的要求。我们提出了一个统一的框架,用于评估LLM在两个维度上的不确定性:任务类型(T),区分分类、短文本生成和长文本生成;验证类型(V),捕捉参考数据或评估标准的可获得性。借鉴计算机科学和社会科学文献,我们将现有的不确定性量化(UQ)方法映射到这个T-V类型学中,并为研究人员提供实用的建议。我们的框架为将LLM整合到严谨的社会科学研究中提供了方法论保障和实践指导。
🔬 方法详解
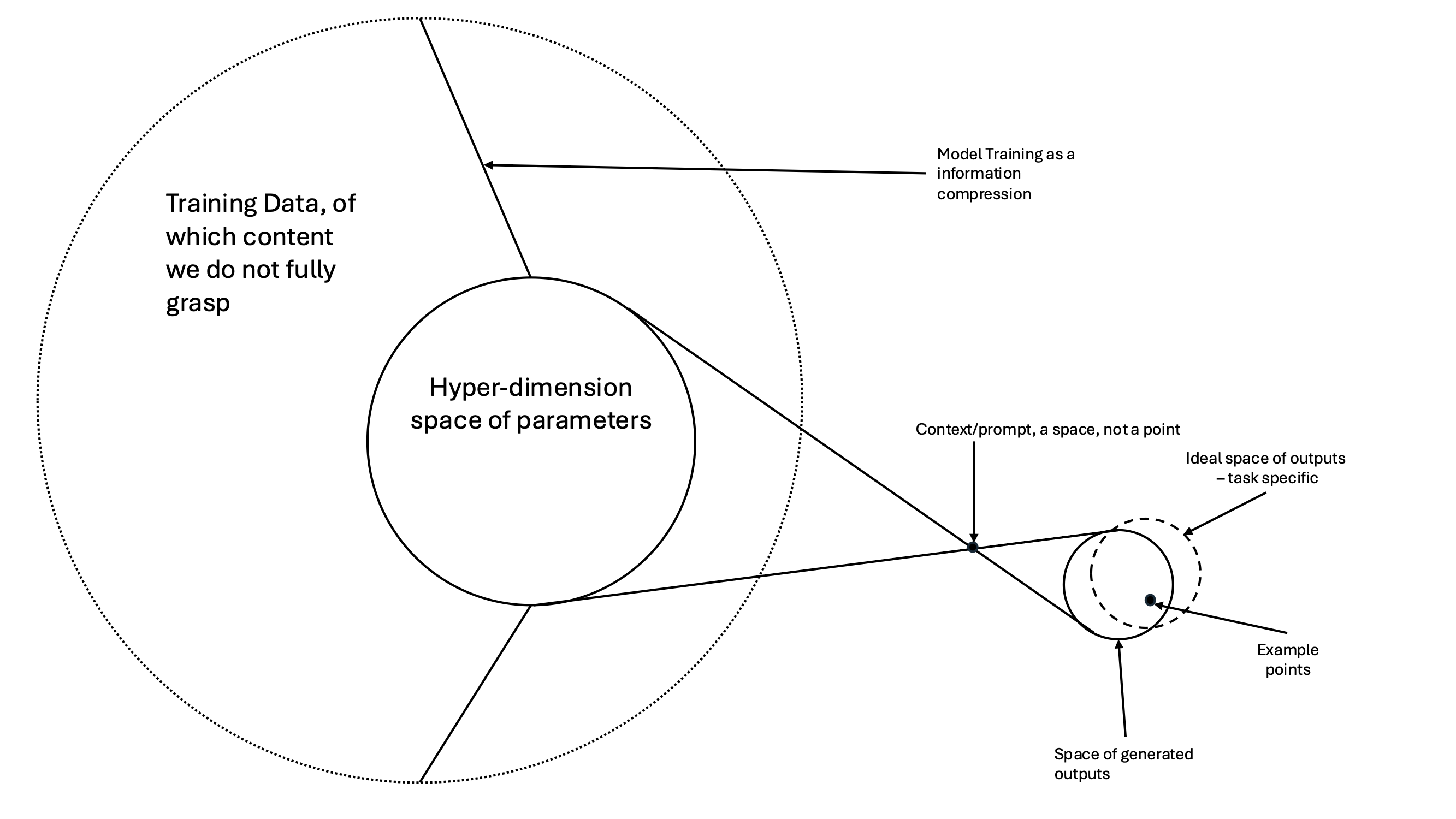
问题定义:LLM在社会科学领域的应用日益广泛,但其固有的不确定性(来源于黑盒训练和推理过程中的随机性)对研究结果的可靠性构成了威胁。现有方法缺乏系统性的不确定性评估框架,难以保证LLM在社会科学研究中的有效性和可信度。因此,如何量化和管理LLM的不确定性成为一个关键问题。
核心思路:论文的核心思路是构建一个统一的框架,从任务类型(Task Type, T)和验证类型(Validation Type, V)两个维度对LLM的不确定性进行系统评估。通过将不同的任务类型(如分类、短文本生成、长文本生成)和验证类型(如存在参考数据、存在评估标准)进行组合,形成一个T-V类型学,从而为选择合适的不确定性量化方法提供指导。
技术框架:该框架主要包含以下几个阶段:1) 定义任务类型(T),明确LLM所执行的任务属于分类、短文本生成还是长文本生成;2) 确定验证类型(V),判断是否存在可用的参考数据或评估标准;3) 根据T-V类型学,选择合适的的不确定性量化(UQ)方法;4) 应用所选的UQ方法对LLM的不确定性进行评估;5) 根据评估结果,对LLM的应用进行调整或改进。
关键创新:该论文的关键创新在于提出了一个统一的T-V框架,用于系统性地评估LLM在社会科学应用中的不确定性。与以往的研究相比,该框架更加全面和系统化,能够覆盖不同类型的任务和验证场景。此外,该框架还借鉴了计算机科学和社会科学领域的知识,为研究人员提供了更实用的指导。
关键设计:T-V框架的关键设计在于其两个维度:任务类型(T)和验证类型(V)。任务类型区分了分类、短文本生成和长文本生成,这三种任务在不确定性来源和评估方法上存在差异。验证类型则考虑了参考数据或评估标准的可获得性,这直接影响了不确定性评估方法的选择。通过将这两个维度进行组合,可以形成一个清晰的类型学,从而为选择合适的UQ方法提供依据。具体的UQ方法选择取决于T-V组合的具体情况,例如,对于分类任务且存在参考数据的情况,可以使用交叉熵损失等方法进行不确定性评估。
🖼️ 关键图片
📊 实验亮点
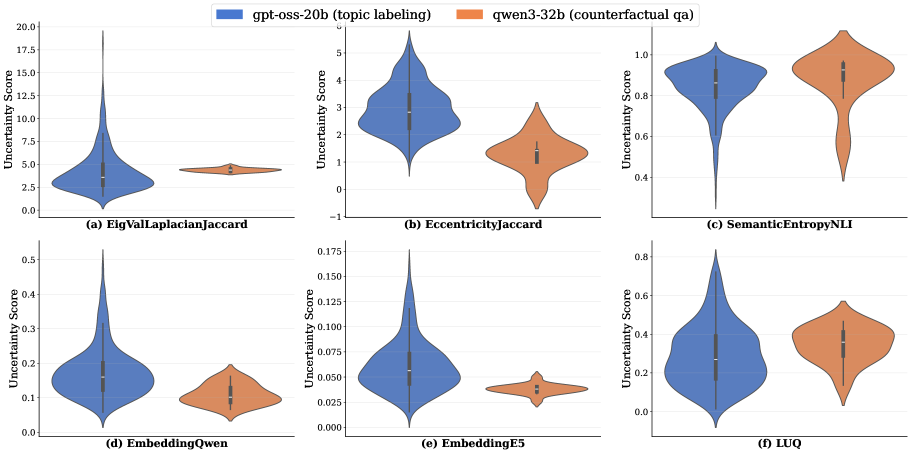
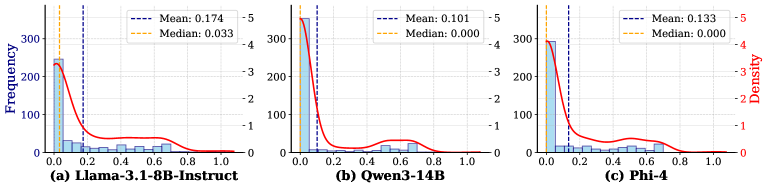
论文提出了一个统一的T-V框架,并将其应用于不同的社会科学任务中。通过该框架,研究人员可以更好地理解和量化LLM的不确定性,从而提高研究结果的可靠性。虽然论文没有提供具体的性能数据,但其提出的框架为LLM在社会科学领域的应用提供了一个重要的 methodological safeguard。
🎯 应用场景
该研究成果可广泛应用于社会科学研究中,例如舆情分析、政策评估、社会关系挖掘等。通过量化和管理LLM的不确定性,可以提高研究结果的可靠性和可信度,为决策提供更准确的依据。未来,该框架可以进一步扩展到其他领域,如医疗、金融等,为AI的可靠应用提供保障。
📄 摘要(原文)
Large language models (LLMs) are rapidly being integrated into computational social science research, yet their blackboxed training and designed stochastic elements in inference pose unique challenges for scientific inquiry. This article argues that applying LLMs to social scientific tasks requires explicit assessment of uncertainty-an expectation long established in both quantitative methodology in the social sciences and machine learning. We introduce a unified framework for evaluating LLM uncertainty along two dimensions: the task type (T), which distinguishes between classification, short-form, and long-form generation, and the validation type (V), which captures the availability of reference data or evaluative criteria. Drawing from both computer science and social science literature, we map existing uncertainty quantification (UQ) methods to this T-V typology and offer practical recommendations for researchers. Our framework provides both a methodological safeguard and a practical guide for integrating LLMs into rigorous social science research.