BEAVER: An Efficient Deterministic LLM Verifier
作者: Tarun Suresh, Nalin Wadhwa, Debangshu Banerjee, Gagandeep Singh
分类: cs.AI, cs.FL
发布日期: 2025-12-05
💡 一句话要点
BEAVER:一种高效的确定性LLM验证框架,用于保证模型输出满足约束条件
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型验证 确定性验证 约束满足 概率界限 token trie frontier数据结构
📋 核心要点
- 现有基于采样的LLM验证方法无法提供可靠的保证,难以满足生产系统对安全性的需求。
- BEAVER通过token trie和frontier数据结构系统探索生成空间,维持可证明的概率界限。
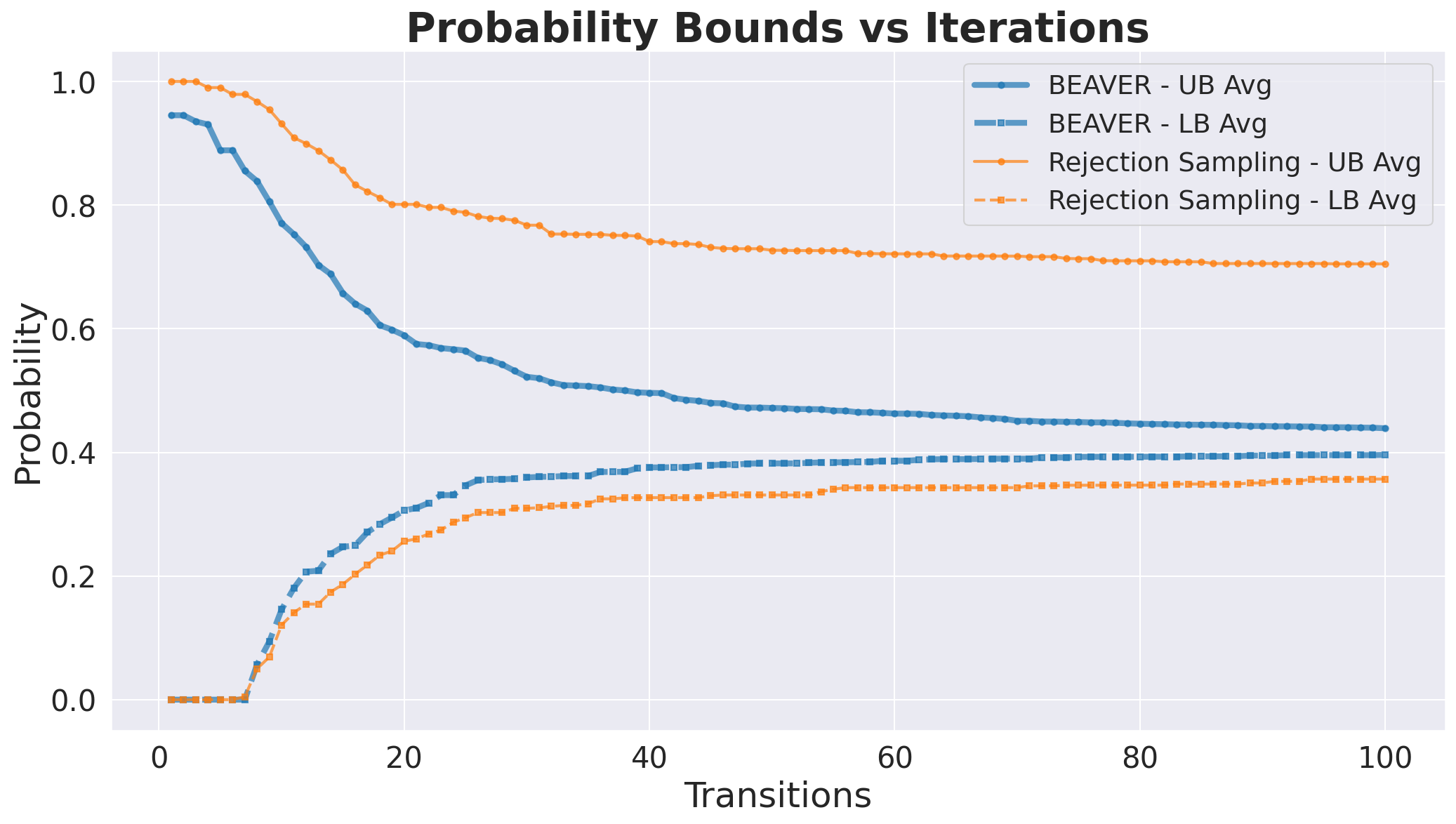
- 实验表明,BEAVER在多个任务中实现了更严格的概率界限,并识别出更多高风险实例。
📝 摘要(中文)
随着大型语言模型(LLM)从研究原型过渡到生产系统,从业者通常需要可靠的方法来验证模型输出是否满足所需的约束。虽然基于采样的估计提供了对模型行为的直观理解,但它们不能提供可靠的保证。我们提出了BEAVER,这是第一个实用的框架,用于计算LLM约束满足的确定性、可靠的概率界限。给定任何前缀封闭的语义约束,BEAVER使用新颖的token trie和frontier数据结构系统地探索生成空间,并在每次迭代中保持可证明的可靠界限。我们形式化了验证问题,证明了我们方法的可靠性,并在多个最先进的LLM上评估了BEAVER在正确性验证、隐私验证和安全代码生成任务中的表现。与在相同计算预算下的基线方法相比,BEAVER实现了6到8倍更严格的概率界限,并识别出3到4倍更多的高风险实例,从而能够进行精确的表征和风险评估,而宽松的界限或经验评估无法提供这些。
🔬 方法详解
问题定义:论文旨在解决如何对大型语言模型(LLM)的输出进行确定性验证的问题,即在给定约束条件下,保证LLM输出满足约束的概率。现有方法,如基于采样的验证,无法提供严格的概率保证,难以满足实际应用中对安全性和可靠性的需求。
核心思路:BEAVER的核心思路是通过系统地探索LLM的生成空间,计算满足约束条件的输出的概率上界和下界。它利用token trie数据结构来表示LLM的生成空间,并使用frontier数据结构来维护待探索的节点。通过迭代地扩展frontier,BEAVER可以逐步缩小概率界限的范围,最终得到满足约束条件的概率的确定性界限。
技术框架:BEAVER框架主要包含以下几个模块:1) 约束定义模块:定义需要验证的约束条件,例如正确性、隐私性或安全性。2) 生成空间探索模块:使用token trie和frontier数据结构,系统地探索LLM的生成空间。3) 概率界限计算模块:在每次迭代中,计算满足约束条件的输出的概率上界和下界。4) 迭代控制模块:根据概率界限的范围,决定是否继续迭代,直到满足预设的精度要求。
关键创新:BEAVER的关键创新在于其确定性验证方法,它不同于传统的基于采样的验证方法,可以提供严格的概率保证。此外,BEAVER还提出了token trie和frontier数据结构,有效地表示和探索LLM的生成空间,提高了验证效率。
关键设计:BEAVER的关键设计包括:1) Token Trie:用于表示LLM的生成空间,每个节点代表一个token,边代表token之间的转移概率。2) Frontier:用于维护待探索的节点,按照一定的策略(例如,概率最大优先)选择节点进行扩展。3) 概率界限计算:使用动态规划算法,计算满足约束条件的输出的概率上界和下界。4) 迭代停止条件:当概率上界和下界的差值小于预设的阈值时,停止迭代。
🖼️ 关键图片


📊 实验亮点
实验结果表明,与基线方法相比,BEAVER在相同计算预算下,实现了6到8倍更严格的概率界限,并识别出3到4倍更多的高风险实例。这表明BEAVER能够更精确地表征LLM的风险,并提供更可靠的保证。例如,在代码生成任务中,BEAVER能够更有效地识别出包含安全漏洞的代码。
🎯 应用场景
BEAVER可应用于对LLM在各种场景下的输出进行验证,例如:验证代码生成模型的安全性,确保生成的代码不包含漏洞;验证对话系统的隐私性,防止泄露用户敏感信息;验证医疗诊断模型的正确性,避免误诊。该研究有助于提高LLM在实际应用中的可靠性和安全性,促进LLM的广泛应用。
📄 摘要(原文)
As large language models (LLMs) transition from research prototypes to production systems, practitioners often need reliable methods to verify that model outputs satisfy required constraints. While sampling-based estimates provide an intuition of model behavior, they offer no sound guarantees. We present BEAVER, the first practical framework for computing deterministic, sound probability bounds on LLM constraint satisfaction. Given any prefix-closed semantic constraint, BEAVER systematically explores the generation space using novel token trie and frontier data structures, maintaining provably sound bounds at every iteration. We formalize the verification problem, prove soundness of our approach, and evaluate BEAVER on correctness verification, privacy verification and secure code generation tasks across multiple state of the art LLMs. BEAVER achieves 6 to 8 times tighter probability bounds and identifies 3 to 4 times more high risk instances compared to baseline methods under identical computational budgets, enabling precise characterization and risk assessment that loose bounds or empirical evaluation cannot provide.