A Systematic Framework for Enterprise Knowledge Retrieval: Leveraging LLM-Generated Metadata to Enhance RAG Systems
作者: Pranav Pushkar Mishra, Kranti Prakash Yeole, Ramyashree Keshavamurthy, Mokshit Bharat Surana, Fatemeh Sarayloo
分类: cs.IR, cs.AI
发布日期: 2025-12-05
备注: 7 pages, 3 figures, 3 tables
💡 一句话要点
提出一种利用LLM生成元数据增强RAG系统的企业知识检索框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 企业知识检索 检索增强生成 大型语言模型 元数据增强 文档分块
📋 核心要点
- 企业知识库庞大复杂,高效检索相关信息对运营效率和决策至关重要,现有方法难以满足需求。
- 该论文提出利用LLM动态生成文档片段的元数据,增强文档的语义表示,从而提升RAG系统的检索精度。
- 实验结果表明,元数据增强方法优于传统方法,递归分块结合TF-IDF加权嵌入实现了82.5%的精确率。
📝 摘要(中文)
本研究提出了一种系统的框架,利用大型语言模型(LLM)进行元数据增强,从而提升检索增强生成(RAG)系统中文档检索的效率。该方法采用了一个全面的、结构化的流程,动态地为文档片段生成有意义的元数据,从而显著提高其语义表示和检索准确性。通过大量的实验,我们比较了三种分块策略——语义分块、递归分块和朴素分块——并评估了它们与高级嵌入技术结合时的有效性。结果表明,元数据增强的方法始终优于仅使用内容的基线方法。递归分块与TF-IDF加权嵌入相结合,实现了82.5%的精确率,而仅使用语义内容的方法为73.3%。采用前缀融合的朴素分块策略实现了最高的Hit Rate@10,达到0.925。我们的评估采用交叉编码器重排序来生成ground truth,从而可以通过Hit Rate和元数据一致性指标进行严格评估。这些发现证实,元数据增强提高了向量聚类的质量,同时减少了检索延迟,使其成为跨知识领域的RAG系统的关键优化。这项工作为在企业环境中部署高性能、可扩展的文档检索解决方案提供了实用的见解,证明了元数据增强是提高RAG有效性的强大方法。
🔬 方法详解
问题定义:企业环境中存在大量复杂知识库,如何从中高效检索相关信息是一个关键问题。现有方法在处理大规模、异构数据时,检索效率和准确性较低,难以满足企业需求。传统方法依赖于关键词匹配或简单的语义相似度计算,无法充分理解文档的深层含义和上下文信息。
核心思路:该论文的核心思路是利用大型语言模型(LLM)生成文档片段的元数据,从而丰富文档的语义表示,提高检索的准确性和效率。通过为每个文档片段添加描述性元数据,可以更精确地捕捉文档的主题、关键词和上下文信息,从而改进向量检索的效果。
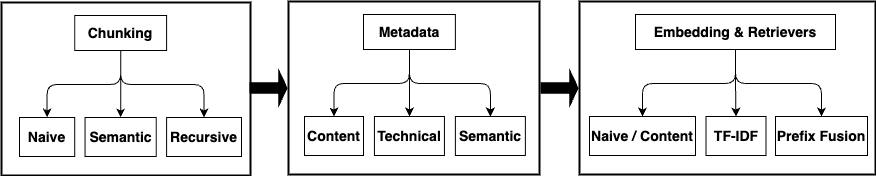
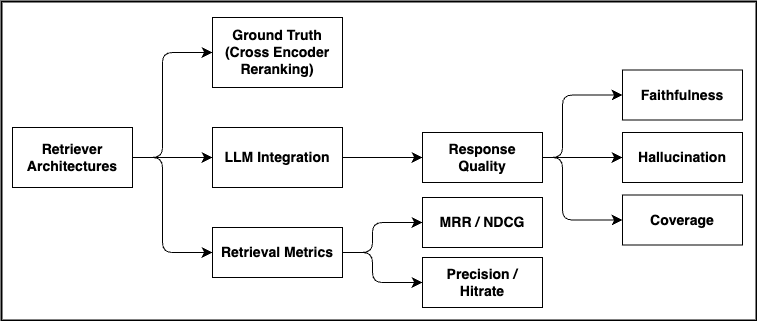
技术框架:该框架包含以下主要模块:1) 文档分块:将原始文档分割成更小的片段,采用语义分块、递归分块和朴素分块等策略。2) 元数据生成:利用LLM为每个文档片段生成元数据,包括主题、关键词、摘要等。3) 嵌入生成:将文档片段和元数据转换为向量表示,采用TF-IDF加权嵌入等技术。4) 向量检索:使用向量数据库存储和检索文档片段,根据查询向量找到最相关的文档片段。5) 重排序:使用交叉编码器对检索结果进行重排序,提高检索的准确性。
关键创新:该论文的关键创新在于将LLM应用于元数据生成,从而自动地为文档片段创建丰富的语义描述。与传统的手工标注或基于规则的元数据生成方法相比,LLM可以更好地理解文档的上下文信息,生成更准确、更全面的元数据。此外,该论文还系统地比较了不同的分块策略和嵌入技术,为企业知识检索提供了实用的指导。
关键设计:在分块策略方面,论文比较了语义分块、递归分块和朴素分块三种方法。在嵌入技术方面,采用了TF-IDF加权嵌入。此外,还使用了交叉编码器进行重排序,以提高检索的准确性。评估指标包括Hit Rate和元数据一致性,采用交叉编码器重排序生成ground truth。
🖼️ 关键图片
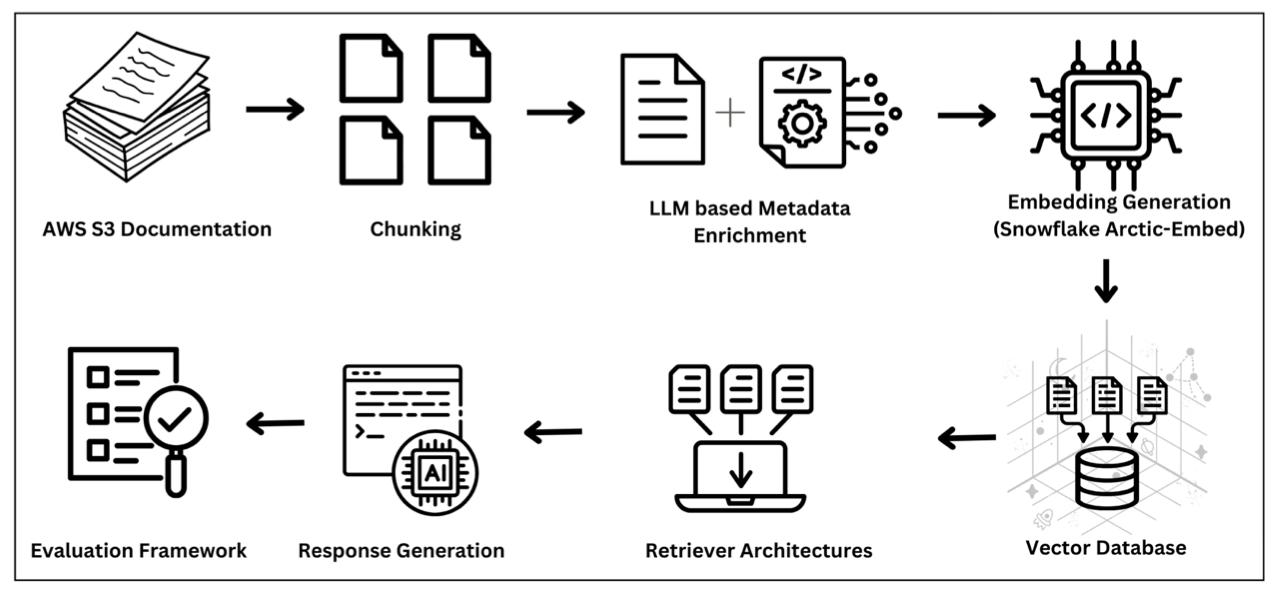
📊 实验亮点
实验结果表明,元数据增强的方法显著提高了RAG系统的检索性能。递归分块与TF-IDF加权嵌入相结合,实现了82.5%的精确率,相比于仅使用语义内容的方法提高了9.2%。采用前缀融合的朴素分块策略实现了最高的Hit Rate@10,达到0.925。这些结果表明,元数据增强是提高企业知识检索效率的有效方法。
🎯 应用场景
该研究成果可广泛应用于企业知识管理、智能客服、法律咨询、金融分析等领域。通过提升RAG系统的检索效率和准确性,可以帮助企业员工快速找到所需信息,提高工作效率和决策质量。未来,该方法还可以扩展到其他类型的知识库,如图像、视频和音频等,实现跨模态的知识检索。
📄 摘要(原文)
In enterprise settings, efficiently retrieving relevant information from large and complex knowledge bases is essential for operational productivity and informed decision-making. This research presents a systematic framework for metadata enrichment using large language models (LLMs) to enhance document retrieval in Retrieval-Augmented Generation (RAG) systems. Our approach employs a comprehensive, structured pipeline that dynamically generates meaningful metadata for document segments, substantially improving their semantic representations and retrieval accuracy. Through extensive experiments, we compare three chunking strategies-semantic, recursive, and naive-and evaluate their effectiveness when combined with advanced embedding techniques. The results demonstrate that metadata-enriched approaches consistently outperform content-only baselines, with recursive chunking paired with TF-IDF weighted embeddings yielding an 82.5% precision rate compared to 73.3% for semantic content-only approaches. The naive chunking strategy with prefix-fusion achieved the highest Hit Rate@10 of 0.925. Our evaluation employs cross-encoder reranking for ground truth generation, enabling rigorous assessment via Hit Rate and Metadata Consistency metrics. These findings confirm that metadata enrichment enhances vector clustering quality while reducing retrieval latency, making it a key optimization for RAG systems across knowledge domains. This work offers practical insights for deploying high-performance, scalable document retrieval solutions in enterprise settings, demonstrating that metadata enrichment is a powerful approach for enhancing RAG effectiveness.