Beyond Detection: A Comprehensive Benchmark and Study on Representation Learning for Fine-Grained Webshell Family Classification
作者: Feijiang Han
分类: cs.CR, cs.AI, cs.LG
发布日期: 2025-12-04
💡 一句话要点
提出Webshell家族分类基准,通过动态函数调用追踪和表示学习实现自动化分析。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: WebShell家族分类 动态分析 表示学习 函数调用追踪 图神经网络 恶意代码分析 自动化分析
📋 核心要点
- 现有WebShell分析主要依赖人工,效率低下,且难以应对加密和混淆等对抗手段。
- 本文提出基于动态函数调用追踪和表示学习的WebShell家族自动分类方法,提升分析效率。
- 通过真实数据集和LLM合成数据进行评估,建立了WebShell家族分类的基准,并分析了不同表示方法的性能。
📝 摘要(中文)
恶意WebShell通过破坏关键数字基础设施对医疗、金融等公共服务构成重大威胁。当前研究主要集中于WebShell检测,即区分恶意样本和良性样本。本文认为应从被动检测转向深入分析和主动防御,WebShell家族分类是其中一个有前景的方向,它能识别特定恶意软件的谱系,从而理解攻击者的策略并实现精确快速的响应。然而,这项关键任务在很大程度上仍未被探索,目前依赖于缓慢的人工专家分析。为了填补这一空白,本文首次系统地研究了WebShell家族分类的自动化。该方法首先提取动态函数调用跟踪,以捕获对常见加密和混淆具有抵抗力的内在行为。为了增强数据集的规模和多样性,使用大型语言模型合成新的变体来扩充这些真实世界的跟踪。然后将这些增强的跟踪抽象为序列、图和树,为基准测试一套全面的表示方法奠定基础。评估涵盖了经典的基于序列的嵌入(CBOW、GloVe)、transformers(BERT、SimCSE)以及一系列结构感知算法,包括图核、图编辑距离、Graph2Vec和各种图神经网络。通过在四个真实世界的、家族注释的数据集上进行监督和非监督设置下的广泛实验,建立了一个强大的基线,并为该挑战提供了数据抽象、表示模型和学习范式的最有效组合的实践见解。
🔬 方法详解
问题定义:WebShell家族分类旨在识别恶意WebShell所属的特定恶意软件家族。现有方法主要依赖人工分析,效率低,且难以应对WebShell的加密和混淆技术。因此,需要一种自动化的、能够有效提取WebShell行为特征并进行家族分类的方法。
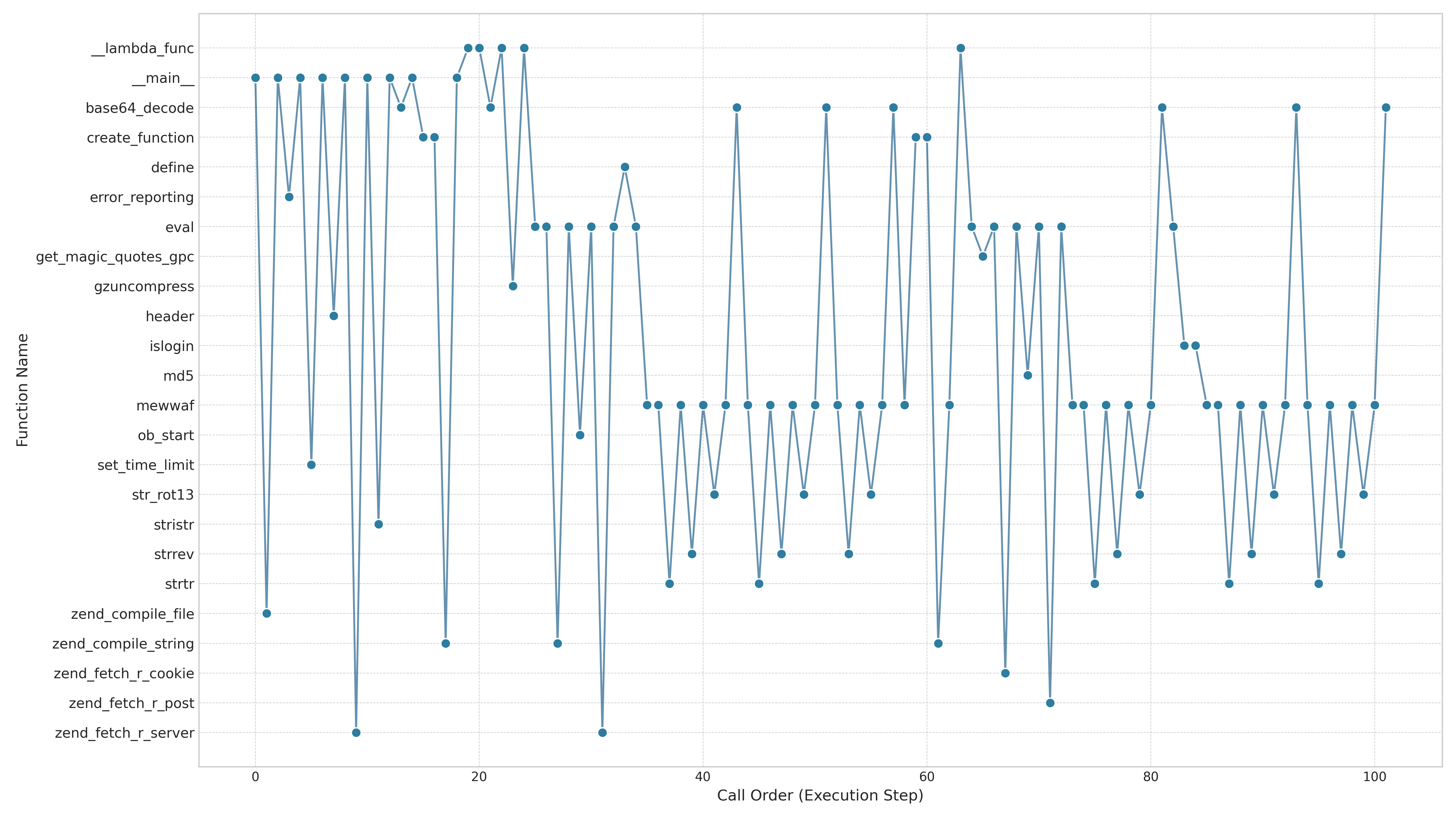
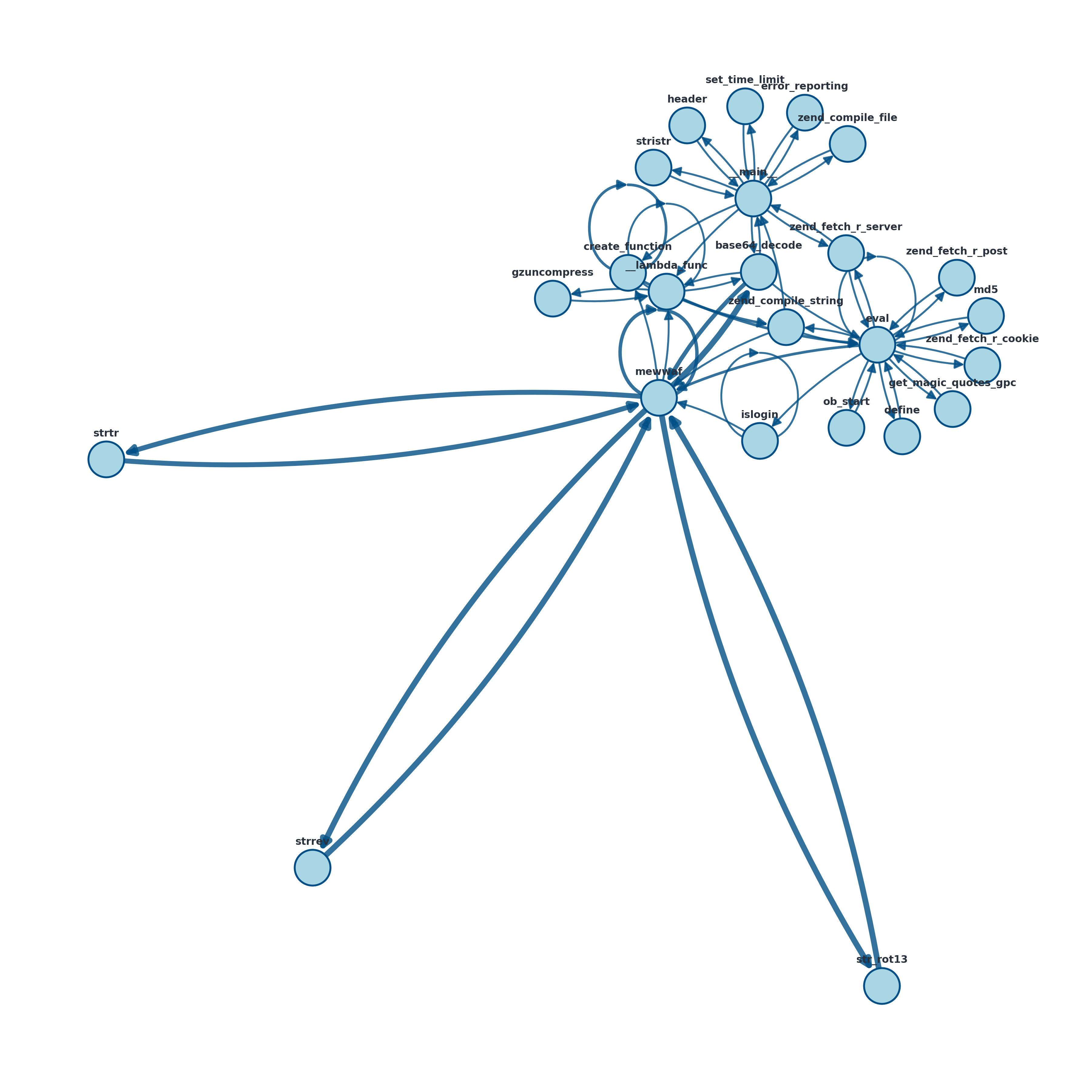
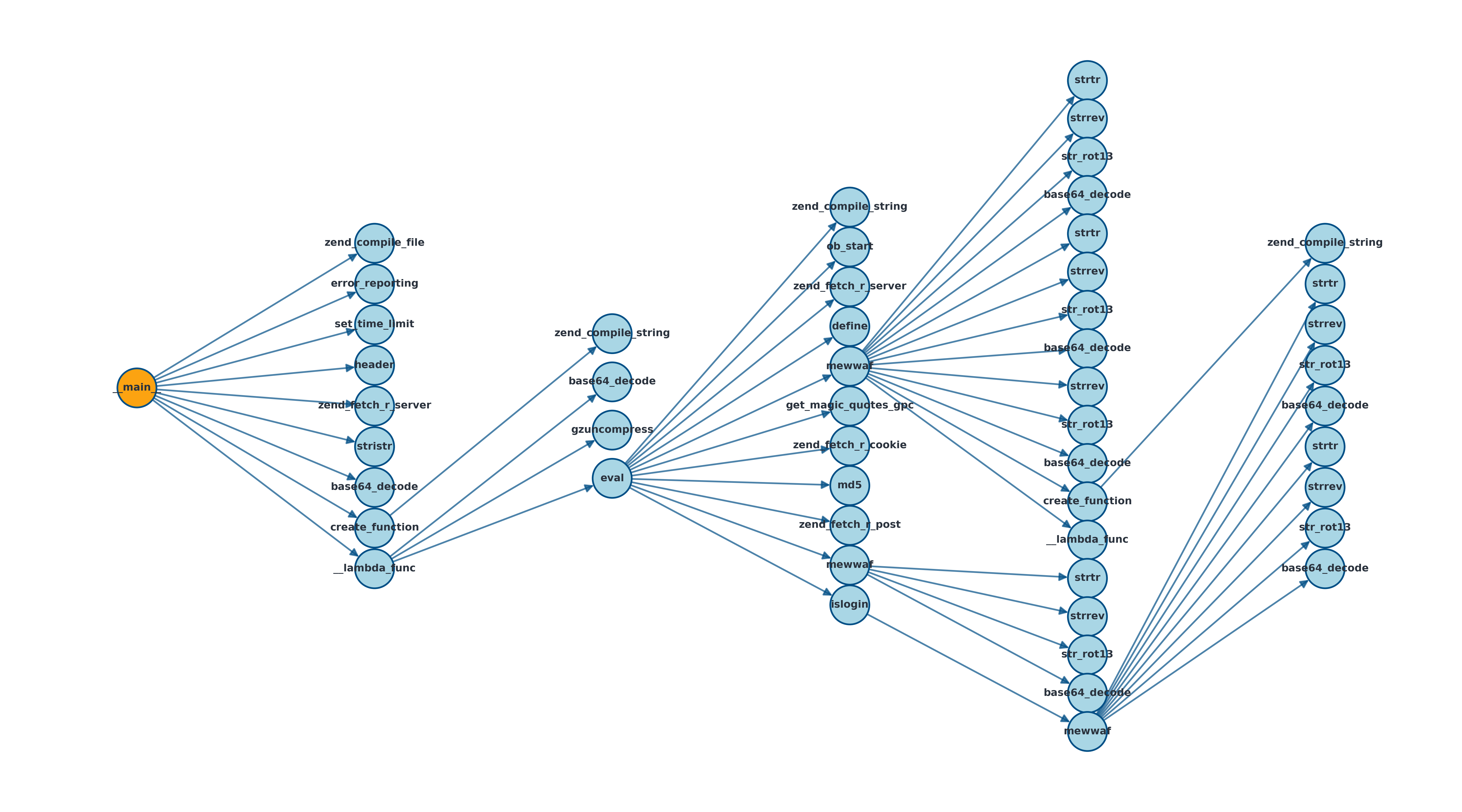
核心思路:本文的核心思路是利用动态函数调用追踪技术,提取WebShell在运行时产生的函数调用序列,这些序列能够反映WebShell的内在行为,并且对加密和混淆具有一定的抵抗性。然后,将这些函数调用序列抽象成序列、图和树等不同的数据结构,并利用各种表示学习方法学习这些数据结构的向量表示,最后使用分类器进行家族分类。
技术框架:整体框架包括以下几个阶段:1) 动态函数调用追踪:运行WebShell样本,记录其函数调用序列。2) 数据抽象:将函数调用序列抽象成序列、图和树等不同的数据结构。3) 表示学习:使用各种表示学习方法(如CBOW、GloVe、BERT、SimCSE、图核、图编辑距离、Graph2Vec、GNN等)学习这些数据结构的向量表示。4) 分类:使用分类器(如SVM、Random Forest等)对WebShell进行家族分类。
关键创新:本文的关键创新在于:1) 首次系统地研究了WebShell家族分类的自动化问题。2) 提出了基于动态函数调用追踪和表示学习的WebShell家族分类方法。3) 使用大型语言模型合成新的WebShell变体,扩充了数据集,提高了评估的稳定性。4) 对比了各种表示学习方法在WebShell家族分类任务上的性能,为该任务选择合适的表示学习方法提供了指导。
关键设计:在数据抽象阶段,将函数调用序列抽象成序列、图和树等不同的数据结构,以捕捉WebShell的不同行为特征。在表示学习阶段,使用了多种经典的序列嵌入方法(CBOW、GloVe)、Transformer模型(BERT、SimCSE)以及结构感知算法(图核、图编辑距离、Graph2Vec、GNN等),以充分利用不同数据结构的特征。在分类阶段,使用了SVM和Random Forest等常用的分类器。
🖼️ 关键图片
📊 实验亮点
实验结果表明,基于动态函数调用追踪和表示学习的方法能够有效进行WebShell家族分类。在四个真实世界的、家族注释的数据集上进行了广泛的实验,建立了强大的基线,并分析了不同数据抽象、表示模型和学习范式的性能。例如,某些图神经网络在特定数据集上表现出优于传统序列模型的性能。
🎯 应用场景
该研究成果可应用于自动化恶意代码分析、威胁情报生成和网络安全防御等领域。通过自动识别WebShell家族,可以帮助安全分析人员快速了解攻击者的策略,并采取相应的防御措施,从而提高网络安全防御的效率和准确性。此外,该方法还可以用于检测新型WebShell变种,提高对未知威胁的防御能力。
📄 摘要(原文)
Malicious WebShells pose a significant and evolving threat by compromising critical digital infrastructures and endangering public services in sectors such as healthcare and finance. While the research community has made significant progress in WebShell detection (i.e., distinguishing malicious samples from benign ones), we argue that it is time to transition from passive detection to in-depth analysis and proactive defense. One promising direction is the automation of WebShell family classification, which involves identifying the specific malware lineage in order to understand an adversary's tactics and enable a precise, rapid response. This crucial task, however, remains a largely unexplored area that currently relies on slow, manual expert analysis. To address this gap, we present the first systematic study to automate WebShell family classification. Our method begins with extracting dynamic function call traces to capture inherent behaviors that are resistant to common encryption and obfuscation. To enhance the scale and diversity of our dataset for a more stable evaluation, we augment these real-world traces with new variants synthesized by Large Language Models. These augmented traces are then abstracted into sequences, graphs, and trees, providing a foundation to benchmark a comprehensive suite of representation methods. Our evaluation spans classic sequence-based embeddings (CBOW, GloVe), transformers (BERT, SimCSE), and a range of structure-aware algorithms, including Graph Kernels, Graph Edit Distance, Graph2Vec, and various Graph Neural Networks. Through extensive experiments on four real-world, family-annotated datasets under both supervised and unsupervised settings, we establish a robust baseline and provide practical insights into the most effective combinations of data abstractions, representation models, and learning paradigms for this challenge.